Contextual Compression in Retrieval-Augmented Generation for Large Language Models: A Survey
作者: Sourav Verma
分类: cs.CL, cs.IR
发布日期: 2024-09-20 (更新: 2024-10-02)
备注: Ongoing Work
💡 一句话要点
综述论文:检索增强生成中上下文压缩技术,提升大语言模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 上下文压缩 大型语言模型 知识检索 信息过滤
📋 核心要点
- 现有大语言模型受限于幻觉、知识更新滞后等问题,影响了其在知识密集型任务中的表现。
- 检索增强生成(RAG)通过引入外部知识库,弥补了LLM的不足,提升了生成内容的质量和可靠性。
- 该综述深入探讨了RAG中上下文压缩技术的演进,并指出了当前挑战和未来研究方向。
📝 摘要(中文)
大型语言模型(LLMs)展示了卓越的能力,但也存在幻觉、知识过时、不透明性和难以解释的推理等局限性。为了应对这些挑战,检索增强生成(RAG)已被证明是一种可行的解决方案,它利用外部数据库来提高生成内容的一致性和连贯性,这对于复杂的、知识丰富的任务尤其有价值,并通过利用特定领域的见解来促进持续改进。通过将LLMs的内在知识与外部数据库的庞大、动态存储库相结合,RAG实现了协同效应。然而,RAG也存在局限性,包括有限的上下文窗口、不相关的信息以及处理大量上下文数据的高昂开销。在这项综合性工作中,我们探讨了上下文压缩范式的演变,对该领域进行了深入的考察。最后,我们概述了当前的挑战,并提出了潜在的研究和发展方向,为该领域未来的发展铺平了道路。
🔬 方法详解
问题定义:论文旨在解决检索增强生成(RAG)中由于上下文窗口限制、检索信息冗余以及处理开销大等问题导致的性能瓶颈。现有方法难以有效利用检索到的信息,导致生成质量下降,计算成本增加。
核心思路:论文的核心思路是对RAG中的上下文信息进行压缩,去除冗余和不相关的信息,从而在有限的上下文窗口内保留最重要的信息,提高生成质量并降低计算开销。通过上下文压缩,可以使LLM更专注于关键信息,减少干扰。
技术框架:该综述性论文主要回顾了上下文压缩技术在RAG中的应用,并没有提出新的技术框架。它主要分析了现有方法的优缺点,并对未来的研究方向进行了展望。常见的上下文压缩方法包括:基于排序的方法(例如,选择最相关的段落)、基于摘要的方法(例如,生成检索文档的摘要)和基于学习的方法(例如,训练模型来选择或压缩上下文)。
关键创新:该论文的关键创新在于对现有上下文压缩方法进行了系统的分类和分析,并指出了不同方法在不同场景下的适用性。此外,论文还提出了未来研究方向,例如,如何更好地利用LLM的内在知识进行上下文压缩,以及如何设计更有效的上下文压缩模型。
关键设计:由于是综述性论文,没有具体的参数设置、损失函数或网络结构等技术细节。论文主要关注不同上下文压缩方法的原理和特点,以及它们在RAG中的应用效果。
🖼️ 关键图片

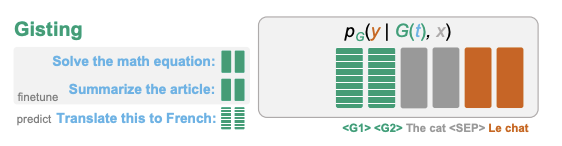
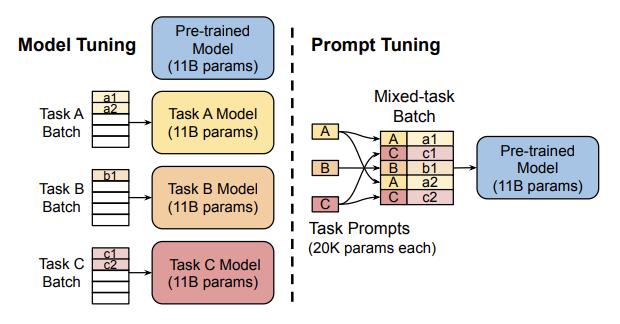
📊 实验亮点
该综述全面梳理了RAG中上下文压缩技术的发展现状,对比分析了不同方法的优劣,并指出了未来的研究方向。虽然没有提供具体的实验数据,但对该领域的研究人员具有重要的参考价值,有助于他们更好地理解和应用上下文压缩技术。
🎯 应用场景
该研究成果可广泛应用于问答系统、知识图谱构建、智能客服等领域。通过优化RAG中的上下文压缩技术,可以提升LLM在各种知识密集型任务中的性能,提高用户体验,并降低部署成本。未来,该技术有望在医疗、金融等专业领域发挥更大的作用。
📄 摘要(原文)
Large Language Models (LLMs) showcase remarkable abilities, yet they struggle with limitations such as hallucinations, outdated knowledge, opacity, and inexplicable reasoning. To address these challenges, Retrieval-Augmented Generation (RAG) has proven to be a viable solution, leveraging external databases to improve the consistency and coherence of generated content, especially valuable for complex, knowledge-rich tasks, and facilitates continuous improvement by leveraging domain-specific insights. By combining the intrinsic knowledge of LLMs with the vast, dynamic repositories of external databases, RAG achieves a synergistic effect. However, RAG is not without its limitations, including a limited context window, irrelevant information, and the high processing overhead for extensive contextual data. In this comprehensive work, we explore the evolution of Contextual Compression paradigms, providing an in-depth examination of the field. Finally, we outline the current challenges and suggest potential research and development directions, paving the way for future advancements in this area.