JMedBench: A Benchmark for Evaluating Japanese Biomedical Large Language Models
作者: Junfeng Jiang, Jiahao Huang, Akiko Aizawa
分类: cs.CL
发布日期: 2024-09-20
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
JMedBench:用于评估日语生物医学大型语言模型的基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 日语LLM 生物医学 基准测试 自然语言处理 模型评估
📋 核心要点
- 现有日语LLM主要集中于通用领域,缺乏针对生物医学领域的专门模型和评估。
- 论文构建了JMedBench基准,包含多个日语生物医学数据集和评估工具,用于全面评估LLM。
- 实验表明,日语理解和生物医学知识丰富的LLM表现更优,但现有模型仍有提升空间。
📝 摘要(中文)
日语大型语言模型(LLM)的最新发展主要集中在通用领域,而日语生物医学LLM的进展较少。一个障碍是缺乏用于比较的全面、大规模基准。此外,评估日语生物医学LLM的资源也不足。为了推进该领域,我们提出了一个新的基准,包括跨四个类别的八个LLM和跨五个任务的20个日语生物医学数据集。实验结果表明:(1)对日语理解更好、生物医学知识更丰富的LLM在日语生物医学任务中表现更好,(2)并非主要为日语生物医学领域设计的LLM仍然可以表现出意想不到的良好性能,以及(3)现有的LLM在某些日语生物医学任务中仍有很大的改进空间。此外,我们提供的见解可以进一步促进该领域的发展。我们为基准量身定制的评估工具以及数据集可在https://huggingface.co/datasets/Coldog2333/JMedBench公开获取,以方便未来的研究。
🔬 方法详解
问题定义:目前,日语生物医学领域缺乏专门的大规模基准测试,这阻碍了该领域日语大型语言模型(LLM)的开发和评估。现有的通用日语LLM可能无法充分理解生物医学领域的专业知识和术语,导致在相关任务中表现不佳。因此,需要一个专门的基准来评估和比较不同LLM在日语生物医学任务中的性能。
核心思路:该论文的核心思路是构建一个综合性的基准测试,即JMedBench,它包含多个日语生物医学数据集,涵盖不同的任务类型。通过在JMedBench上评估各种LLM,可以系统地分析它们的优势和劣势,从而为未来的模型开发提供指导。此外,该基准的公开可用性可以促进该领域的研究和合作。
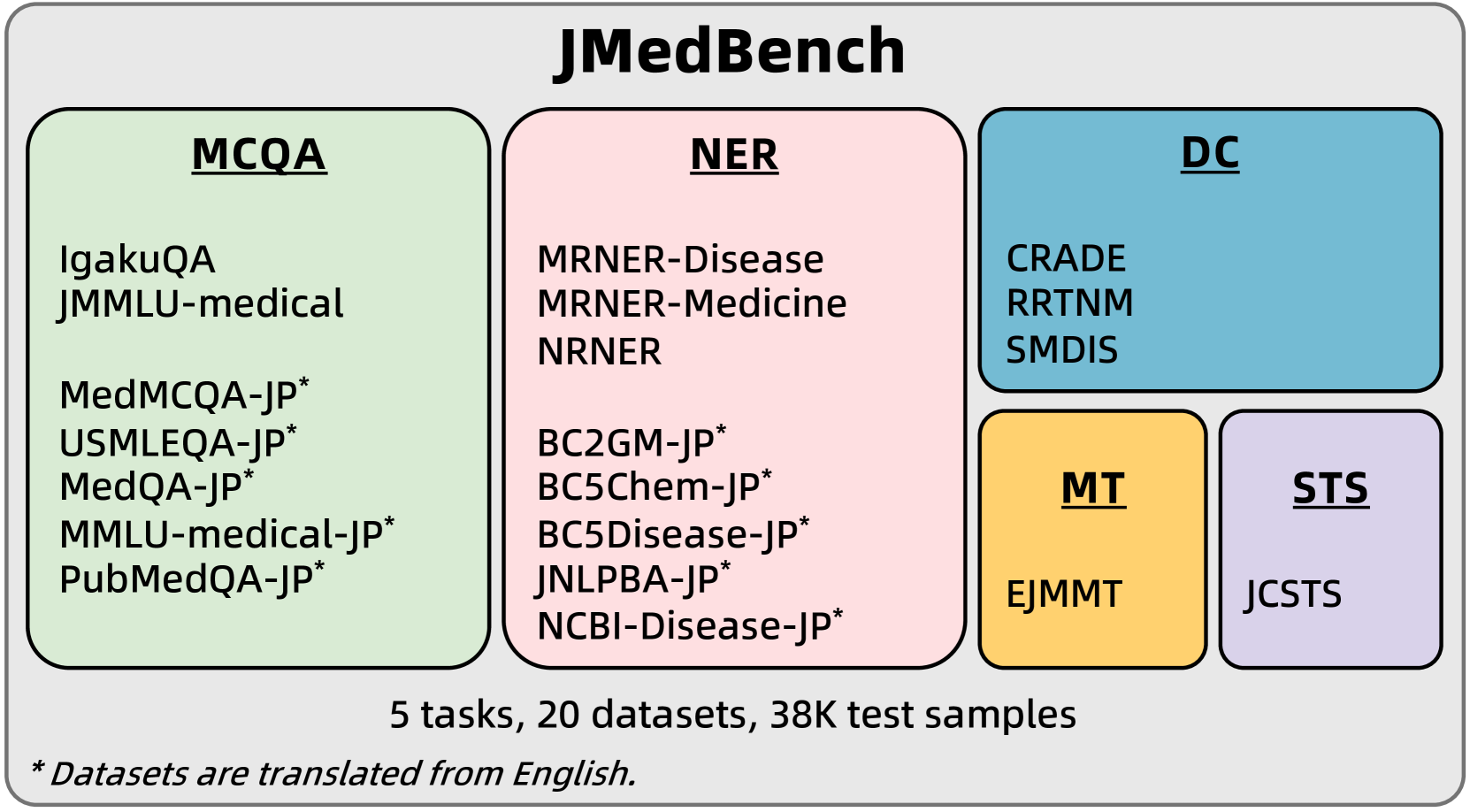
技术框架:JMedBench基准测试主要包含以下几个部分: 1. 数据集收集与整理:收集了20个日语生物医学数据集,涵盖五个任务:文本分类、命名实体识别、关系抽取、问答和文本生成。 2. 模型选择:选择了8个具有代表性的LLM,包括通用LLM和专门的生物医学LLM。 3. 评估指标:针对不同的任务类型,选择了合适的评估指标,如准确率、F1值等。 4. 实验评估:在JMedBench上对选定的LLM进行评估,并分析实验结果。
关键创新:该论文的关键创新在于构建了一个专门针对日语生物医学领域的综合性基准测试。与现有的通用基准测试相比,JMedBench更关注生物医学领域的专业知识和术语,能够更准确地评估LLM在该领域的性能。此外,JMedBench的公开可用性也促进了该领域的研究和发展。
关键设计:数据集的选择涵盖了生物医学领域的多个方面,确保了基准测试的全面性。选择了具有代表性的LLM,包括通用LLM和专门的生物医学LLM,以便进行比较分析。针对不同的任务类型,选择了合适的评估指标,以确保评估结果的准确性。评估工具和数据集均已公开,方便其他研究人员使用和扩展。
🖼️ 关键图片
📊 实验亮点
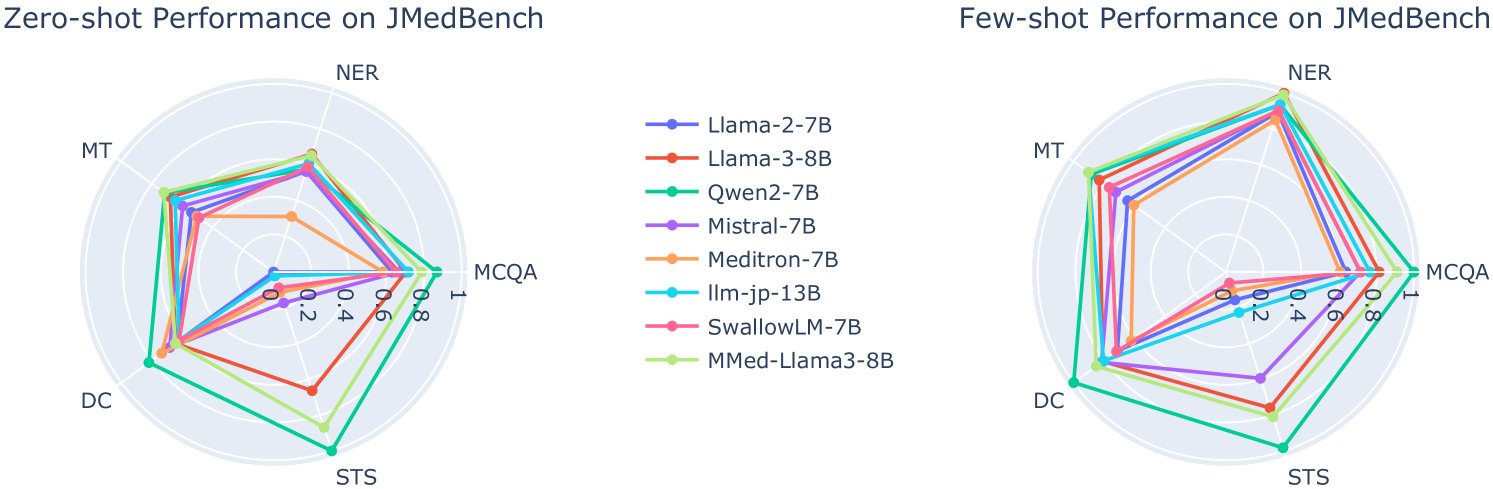
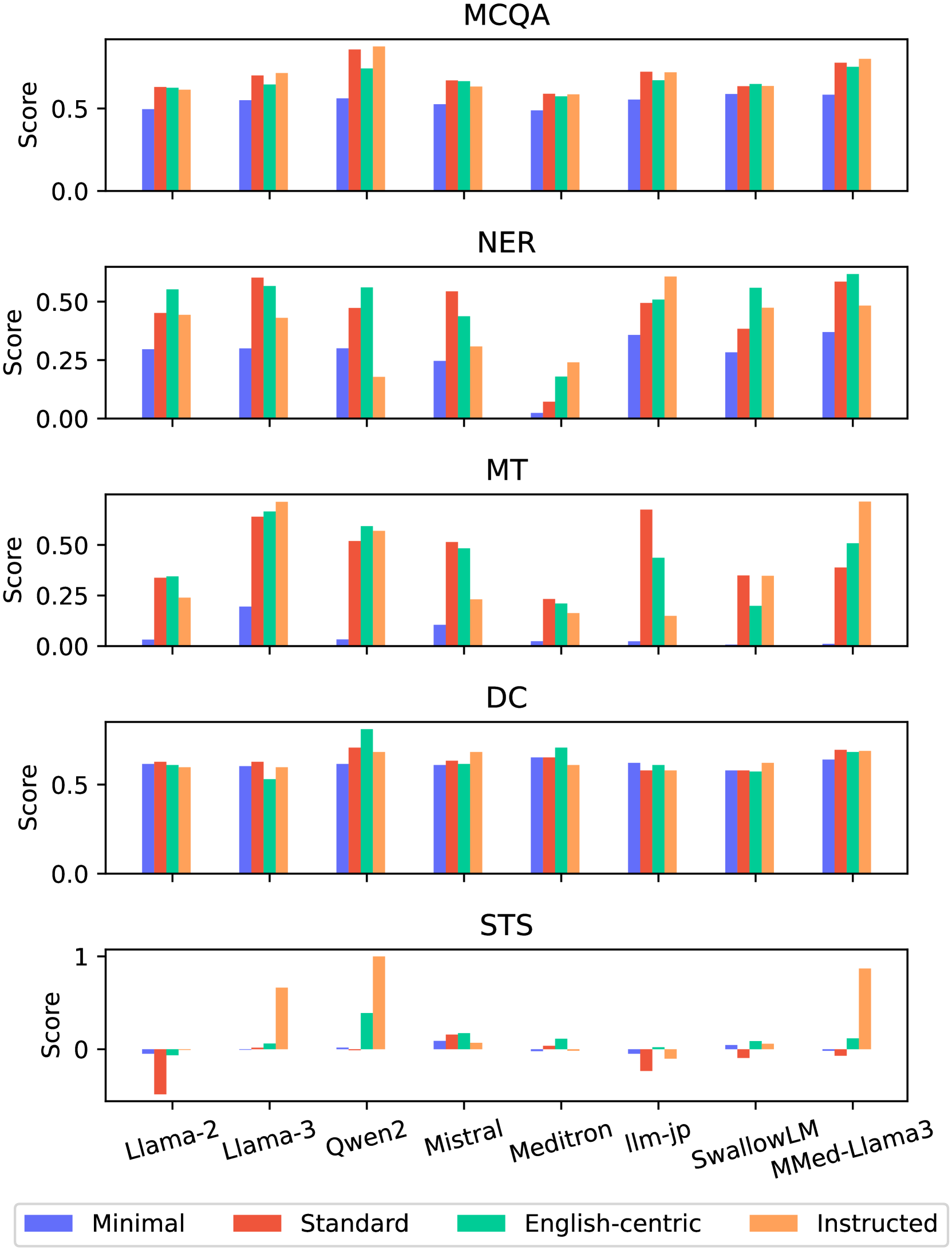
实验结果表明,对日语理解更好、生物医学知识更丰富的LLM在日语生物医学任务中表现更好。例如,某些专门针对日语设计的LLM在特定任务上取得了显著的性能提升。此外,研究还发现,即使不是专门为日语生物医学领域设计的LLM,在某些任务上也能表现出意想不到的良好性能。这些结果为未来的模型开发提供了有价值的参考。
🎯 应用场景
JMedBench可用于评估和比较不同的日语生物医学LLM,从而指导模型开发和选择。它还可以应用于医疗诊断、药物研发、医学信息检索等领域,提高相关任务的效率和准确性。未来,该基准可以扩展到其他语言和领域,促进跨语言和跨领域的生物医学研究。
📄 摘要(原文)
Recent developments in Japanese large language models (LLMs) primarily focus on general domains, with fewer advancements in Japanese biomedical LLMs. One obstacle is the absence of a comprehensive, large-scale benchmark for comparison. Furthermore, the resources for evaluating Japanese biomedical LLMs are insufficient. To advance this field, we propose a new benchmark including eight LLMs across four categories and 20 Japanese biomedical datasets across five tasks. Experimental results indicate that: (1) LLMs with a better understanding of Japanese and richer biomedical knowledge achieve better performance in Japanese biomedical tasks, (2) LLMs that are not mainly designed for Japanese biomedical domains can still perform unexpectedly well, and (3) there is still much room for improving the existing LLMs in certain Japanese biomedical tasks. Moreover, we offer insights that could further enhance development in this field. Our evaluation tools tailored to our benchmark as well as the datasets are publicly available in https://huggingface.co/datasets/Coldog2333/JMedBench to facilitate future research.