RRM: Robust Reward Model Training Mitigates Reward Hacking
作者: Tianqi Liu, Wei Xiong, Jie Ren, Lichang Chen, Junru Wu, Rishabh Joshi, Yang Gao, Jiaming Shen, Zhen Qin, Tianhe Yu, Daniel Sohn, Anastasiia Makarova, Jeremiah Liu, Yuan Liu, Bilal Piot, Abe Ittycheriah, Aviral Kumar, Mohammad Saleh
分类: cs.CL
发布日期: 2024-09-20 (更新: 2025-02-27)
备注: Accepted in ICLR 2025
💡 一句话要点
提出RRM以解决奖励模型训练中的奖励攻击问题,提升LLM对齐效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 奖励模型 奖励攻击 大型语言模型对齐 因果推断 数据增强
📋 核心要点
- 现有奖励模型训练方法难以区分提示驱动的偏好与响应长度等无关伪影,导致奖励攻击。
- 论文提出一种因果框架,学习独立于伪影的偏好,并设计数据增强技术消除伪影。
- 实验表明,RRM能有效过滤不良伪影,显著提升奖励模型和DPO对齐策略的性能。
📝 摘要(中文)
奖励模型(RM)在将大型语言模型(LLM)与人类偏好对齐方面起着关键作用。然而,传统的RM训练依赖于与特定提示相关的响应对,难以区分提示驱动的偏好与提示无关的伪影,例如响应长度和格式。本文揭示了当前RM训练方法的一个根本局限性,即RM在确定偏好时无法有效区分上下文信号和无关伪影。为了解决这个问题,我们引入了一个因果框架,用于学习独立于这些伪影的偏好,并提出了一种新颖的数据增强技术来消除它们。大量实验表明,我们的方法成功地过滤掉了不良伪影,从而产生了一个更鲁棒的奖励模型(RRM)。我们的RRM提高了在Gemma-2-9b-it上训练的成对奖励模型的性能,在RewardBench上将准确率从80.61%提高到84.15%。此外,我们使用RM和RRM训练了两个DPO策略,表明RRM显著增强了DPO对齐的策略,将MT-Bench分数从7.27提高到8.31,并将AlpacaEval-2中长度控制的胜率从33.46%提高到52.49%。
🔬 方法详解
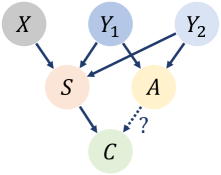
问题定义:现有奖励模型训练方法在对齐大型语言模型时,容易受到奖励攻击的影响。这是因为奖励模型无法有效区分来自提示的真实偏好信号和诸如响应长度、格式等无关伪影。这些伪影的存在使得模型容易学习到错误的偏好,从而导致奖励被“黑客”攻击,即模型生成符合奖励模型偏好但实际上不符合人类意图的响应。
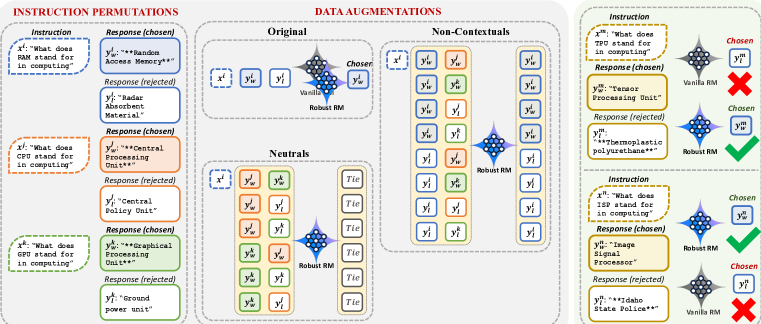
核心思路:论文的核心思路是建立一个因果框架,将人类偏好建模为独立于这些伪影的因素。通过识别并消除这些伪影的影响,奖励模型可以更准确地学习到真实的偏好。具体来说,论文通过数据增强技术来消除这些伪影,使得模型在训练过程中能够更好地关注上下文信号,而不是被无关因素所干扰。
技术框架:整体框架包含以下几个主要步骤:1) 识别并定义可能影响奖励模型的伪影;2) 设计数据增强策略,用于消除这些伪影的影响;3) 使用增强后的数据训练鲁棒的奖励模型(RRM);4) 使用RRM训练DPO策略,并评估其性能。该框架的核心在于数据增强策略的设计,它旨在通过修改训练数据,使得模型无法依赖于伪影来预测奖励。
关键创新:最重要的技术创新点在于提出了一个基于因果推断的数据增强方法,用于消除奖励模型训练中的伪影影响。与传统的奖励模型训练方法不同,该方法显式地考虑了伪影的存在,并通过数据增强技术来消除它们的影响。这种方法能够使得奖励模型更加关注上下文信号,从而提高其鲁棒性和泛化能力。
关键设计:论文的关键设计在于数据增强策略。具体来说,论文通过修改训练数据中的响应长度和格式等伪影,使得模型无法依赖于这些伪影来预测奖励。例如,可以通过截断或填充响应来改变其长度,或者通过修改响应的格式来改变其呈现方式。此外,论文还可能使用了对比学习等技术,使得模型能够更好地区分真实偏好和伪影。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RRM在RewardBench上将准确率从80.61%提高到84.15%。使用RRM训练的DPO策略在MT-Bench上将分数从7.27提高到8.31,在AlpacaEval-2中长度控制的胜率从33.46%提高到52.49%。这些结果表明,RRM能够有效过滤不良伪影,显著提升奖励模型和DPO对齐策略的性能。
🎯 应用场景
该研究成果可广泛应用于大型语言模型的对齐训练中,尤其是在需要高度可靠和安全的场景下,例如智能客服、医疗诊断、金融风控等。通过提高奖励模型的鲁棒性,可以有效防止模型生成有害或不符合人类意图的响应,从而提升用户体验和安全性。未来,该方法还可以扩展到其他类型的奖励模型和强化学习任务中。
📄 摘要(原文)
Reward models (RMs) play a pivotal role in aligning large language models (LLMs) with human preferences. However, traditional RM training, which relies on response pairs tied to specific prompts, struggles to disentangle prompt-driven preferences from prompt-independent artifacts, such as response length and format. In this work, we expose a fundamental limitation of current RM training methods, where RMs fail to effectively distinguish between contextual signals and irrelevant artifacts when determining preferences. To address this, we introduce a causal framework that learns preferences independent of these artifacts and propose a novel data augmentation technique designed to eliminate them. Extensive experiments show that our approach successfully filters out undesirable artifacts, yielding a more robust reward model (RRM). Our RRM improves the performance of a pairwise reward model trained on Gemma-2-9b-it, on RewardBench, increasing accuracy from 80.61% to 84.15%. Additionally, we train two DPO policies using both the RM and RRM, demonstrating that the RRM significantly enhances DPO-aligned policies, improving MT-Bench scores from 7.27 to 8.31 and length-controlled win-rates in AlpacaEval-2 from 33.46% to 52.49%.