LLM Surgery: Efficient Knowledge Unlearning and Editing in Large Language Models
作者: Akshaj Kumar Veldanda, Shi-Xiong Zhang, Anirban Das, Supriyo Chakraborty, Stephen Rawls, Sambit Sahu, Milind Naphade
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-09-19
💡 一句话要点
LLM手术:提出一种高效的大语言模型知识遗忘与编辑方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 知识遗忘 知识编辑 模型微调 反向梯度 KL散度 Llama2
📋 核心要点
- 大型语言模型存在嵌入过时或有害知识的问题,需要高效的知识更新和遗忘机制。
- LLM手术框架通过优化包含反向梯度、梯度下降和KL散度的三组件目标函数,实现知识的遗忘、更新和保留。
- 实验表明,该方法在Llama2-7B上实现了显著的知识遗忘,更新集准确率提升20%,并保持了原有知识的性能。
📝 摘要(中文)
大型语言模型(LLM)已经革新了多个领域,但其效用也伴随着与预训练期间嵌入的过时或有问题知识相关的重大挑战。本文旨在解决修改LLM以遗忘有问题和过时信息,同时高效集成新知识而无需从头开始重新训练的难题。我们提出了一种名为LLM手术的框架,通过优化一个三组件目标函数来高效地修改LLM的行为:(1) 对遗忘数据集(有问题和过时信息)执行反向梯度;(2) 对更新数据集(新的和更新的信息)执行梯度下降;(3) 最小化保留数据集(未更改文本的小子集)上的KL散度,确保预训练模型和修改后模型输出之间的一致性。由于缺乏专门为我们的新任务量身定制的公开数据集,我们编译了一个新的数据集和一个评估基准。使用Llama2-7B,我们证明了LLM手术可以在遗忘集上实现显著的遗忘,在更新集上实现20%的准确率提升,并保持在保留集上的性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型中存在的过时或有害知识难以有效移除和更新的问题。现有方法通常需要从头开始重新训练模型,计算成本高昂且效率低下。因此,如何高效地修改LLM的行为,使其能够遗忘不需要的知识并学习新的知识,同时保持原有知识的性能,是本研究要解决的核心问题。
核心思路:论文的核心思路是通过一种类似于“手术”的方式,精确地修改LLM中的知识表示,而无需完全重新训练。具体来说,通过优化一个目标函数,该函数包含三个组成部分:一是通过反向梯度来“擦除”不需要的知识;二是通过梯度下降来“注入”新的知识;三是通过KL散度来保持原有知识的稳定。这种方法旨在实现知识的精确修改,同时最大限度地减少对模型其他部分的影响。
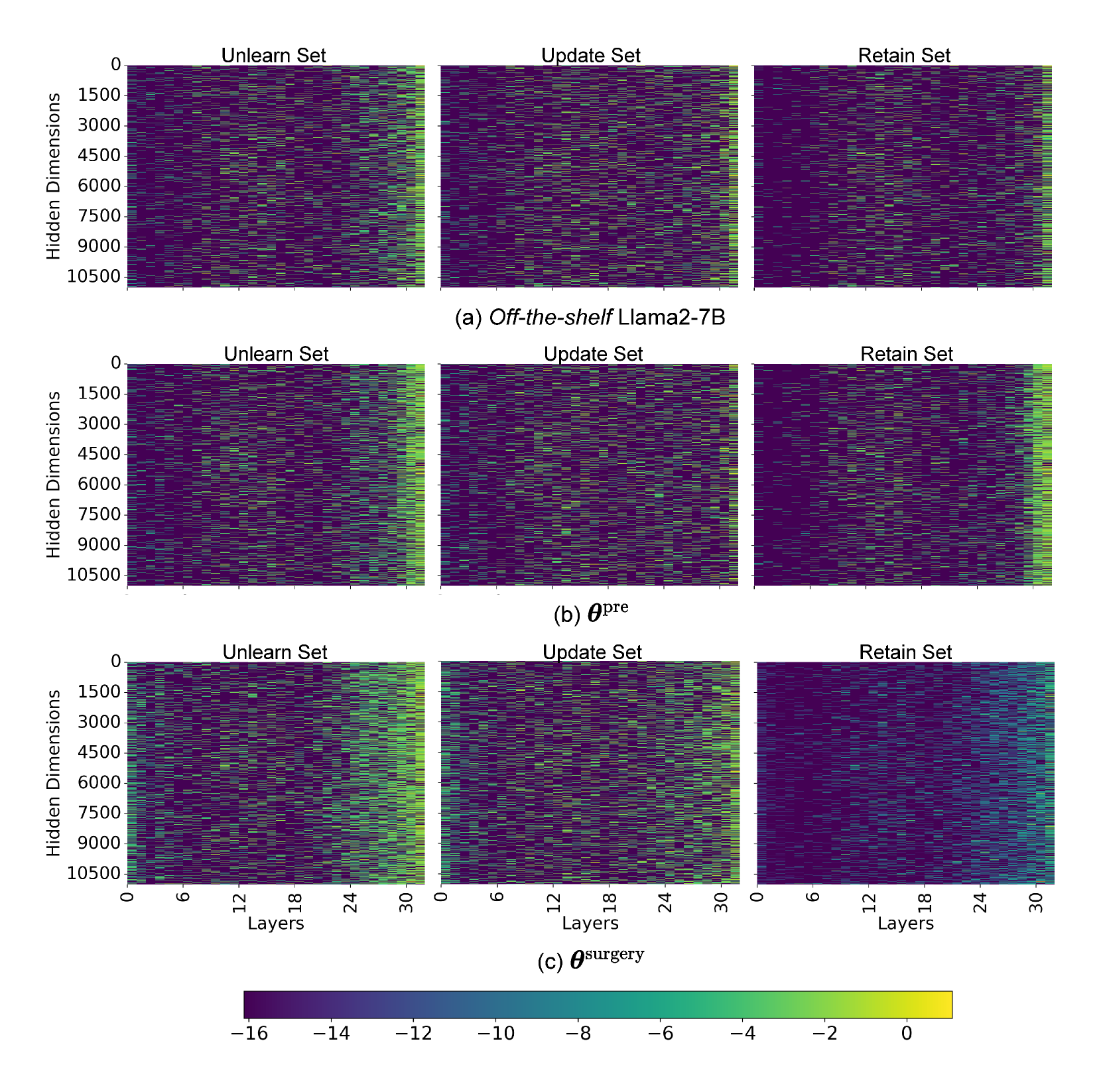
技术框架:LLM手术框架主要包含以下几个阶段:1) 数据准备:构建包含遗忘数据集(Unlearn Set)、更新数据集(Update Set)和保留数据集(Retain Set)的数据集。遗忘数据集包含需要移除的知识,更新数据集包含需要学习的新知识,保留数据集包含需要保持的知识。2) 目标函数构建:构建包含三个组成部分的目标函数:反向梯度损失、梯度下降损失和KL散度损失。3) 模型微调:使用构建的目标函数对LLM进行微调,以实现知识的遗忘、更新和保留。4) 评估:使用评估基准对修改后的LLM进行评估,以验证其性能。
关键创新:论文的关键创新在于提出了一种高效的知识遗忘和编辑框架,该框架能够精确地修改LLM中的知识表示,而无需完全重新训练。与现有方法相比,该方法具有更高的效率和更低的计算成本。此外,论文还构建了一个新的数据集和一个评估基准,为该领域的研究提供了支持。
关键设计:目标函数的设计是关键。反向梯度损失用于“擦除”不需要的知识,其计算方式是使用遗忘数据集上的梯度进行反向传播。梯度下降损失用于“注入”新的知识,其计算方式是使用更新数据集上的梯度进行正向传播。KL散度损失用于保持原有知识的稳定,其计算方式是最小化修改前后模型在保留数据集上的输出分布的差异。此外,论文还对各个损失函数的权重进行了调整,以平衡知识遗忘、更新和保留之间的关系。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM手术框架在Llama2-7B模型上取得了显著的性能提升。在遗忘集上,该方法能够有效地移除不需要的知识;在更新集上,该方法实现了20%的准确率提升;在保留集上,该方法能够保持原有知识的性能。这些结果表明,LLM手术框架是一种高效且有效的知识遗忘和编辑方法。
🎯 应用场景
该研究成果可应用于多个领域,例如:1) 清除LLM中存在的偏见或有害信息,提高模型的安全性;2) 快速更新LLM的知识库,使其能够适应不断变化的世界;3) 定制LLM的行为,使其能够满足特定用户的需求。该研究具有重要的实际价值和广阔的应用前景,有望推动LLM在各个领域的应用。
📄 摘要(原文)
Large language models (LLMs) have revolutionized various domains, yet their utility comes with significant challenges related to outdated or problematic knowledge embedded during pretraining. This paper addresses the challenge of modifying LLMs to unlearn problematic and outdated information while efficiently integrating new knowledge without retraining from scratch. Here, we propose LLM Surgery, a framework to efficiently modify LLM behaviour by optimizing a three component objective function that: (1) Performs reverse gradient on unlearning dataset (problematic and outdated information), (2) Performs gradient descent on the update dataset (new and updated information), and (3) Minimizes the KL divergence on the retain dataset (small subset of unchanged text), ensuring alignment between pretrained and modified model outputs. Due to the lack of publicly available datasets specifically tailored for our novel task, we compiled a new dataset and an evaluation benchmark. Using Llama2-7B, we demonstrate that LLM Surgery can achieve significant forgetting on the unlearn set, a 20\% increase in accuracy on the update set, and maintain performance on the retain set.