CLAIR-A: Leveraging Large Language Models to Judge Audio Captions
作者: Tsung-Han Wu, Joseph E. Gonzalez, Trevor Darrell, David M. Chan
分类: cs.CL, cs.SD, eess.AS
发布日期: 2024-09-19 (更新: 2025-08-11)
备注: Accepted to ASRU 2025; Code is publicly available at https://github.com/DavidMChan/clair-a
🔗 代码/项目: GITHUB
💡 一句话要点
CLAIR-A:利用大型语言模型评估音频描述质量
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频描述评估 大型语言模型 零样本学习 语义距离 可解释性
📋 核心要点
- 现有音频描述评估方法难以全面衡量质量,无法很好地与人类判断对齐,是目前面临的核心问题。
- CLAIR-A利用大型语言模型的零样本能力,通过计算语义距离来评估音频描述,无需额外训练。
- 实验表明,CLAIR-A在预测人类判断方面优于传统指标,并能提供更透明、更合理的评估解释。
📝 摘要(中文)
自动音频描述(AAC)任务旨在生成对音频输入的自然语言描述。评估这些机器生成的音频描述是一项复杂的任务,需要考虑多种因素,包括听觉场景理解、声音对象推断、时间连贯性和场景的环境背景。虽然目前的方法侧重于特定方面,但它们通常无法提供与人类判断良好对齐的总体分数。在这项工作中,我们提出了CLAIR-A,一种简单而灵活的方法,它利用大型语言模型(LLM)的零样本能力,通过直接向LLM询问语义距离分数来评估候选音频描述。在我们的评估中,与传统指标相比,CLAIR-A更好地预测了人类对质量的判断,在Clotho-Eval数据集上,相对于特定领域的FENSE指标,准确率相对提高了5.8%,相对于最佳通用指标,准确率提高了高达11%。此外,CLAIR-A提供了更高的透明度,允许语言模型解释其评分背后的原因,这些解释被人类评估者评为比基线方法提供的解释好30%。CLAIR-A已公开发布在https://github.com/DavidMChan/clair-a。
🔬 方法详解
问题定义:自动音频描述(AAC)旨在为给定的音频输入生成自然语言描述。然而,如何有效地评估这些描述的质量是一个挑战。现有的评估指标要么是通用的,无法捕捉音频领域的特殊性,要么是领域特定的,但缺乏与人类判断的一致性。这些方法难以综合考虑听觉场景理解、声音对象推断、时间连贯性和环境背景等多种因素。
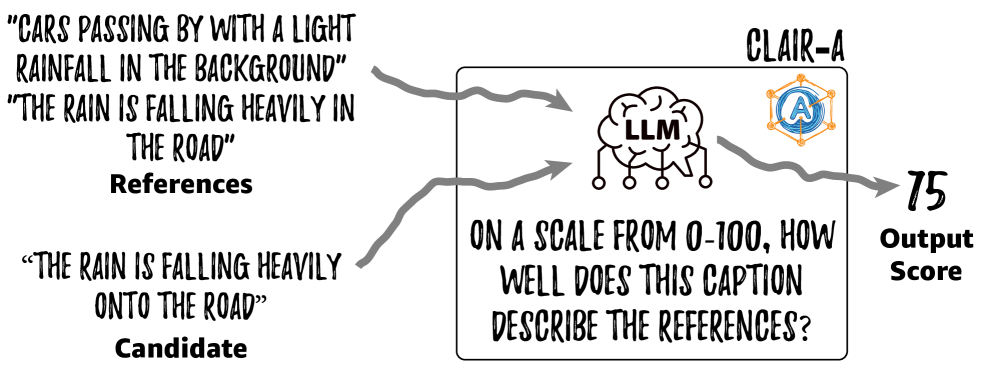
核心思路:CLAIR-A的核心思路是利用大型语言模型(LLM)强大的语义理解和推理能力,直接评估候选音频描述的质量。通过将评估任务转化为一个语义距离计算问题,CLAIR-A可以利用LLM的零样本能力,无需针对音频描述评估进行专门的训练。这种方法旨在更准确地反映人类对音频描述质量的判断。
技术框架:CLAIR-A的整体框架非常简洁。它主要包含以下步骤:1) 给定一个音频输入和相应的候选描述;2) 将候选描述输入到大型语言模型(LLM)中,并提示LLM计算该描述与理想描述之间的语义距离;3) LLM输出一个语义距离分数,该分数作为对候选描述质量的评估。此外,CLAIR-A还可以要求LLM解释其评分的原因,从而提高评估的透明度。
关键创新:CLAIR-A的关键创新在于它将大型语言模型应用于音频描述评估任务,并利用其零样本能力进行语义距离计算。与传统的评估指标相比,CLAIR-A能够更好地捕捉音频领域的复杂性和细微差别,并更准确地反映人类的判断。此外,CLAIR-A提供的可解释性是传统指标所不具备的。
关键设计:CLAIR-A的关键设计在于如何有效地提示大型语言模型(LLM)进行语义距离计算。论文中可能使用了特定的提示工程技术,例如,使用特定的提示语来引导LLM关注音频描述的关键方面,并提供合理的解释。具体的参数设置和网络结构取决于所使用的大型语言模型,论文中可能没有详细描述。
🖼️ 关键图片
📊 实验亮点
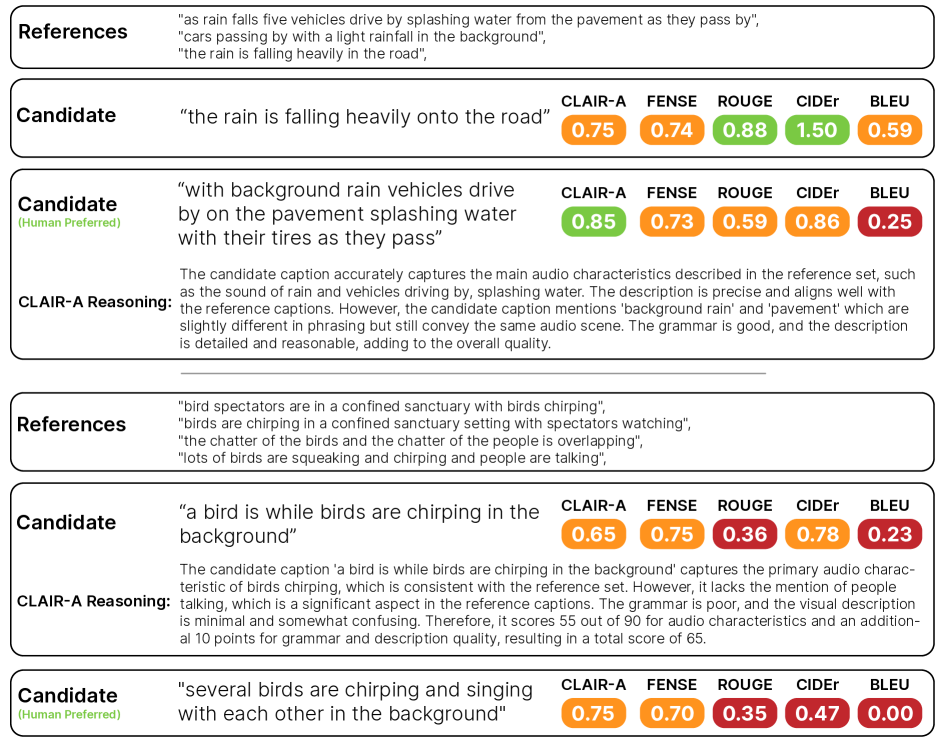
实验结果表明,CLAIR-A在Clotho-Eval数据集上优于传统的评估指标。相对于领域特定的FENSE指标,准确率相对提高了5.8%,相对于最佳通用指标,准确率提高了高达11%。此外,人类评估者认为CLAIR-A提供的解释比基线方法提供的解释好30%,表明CLAIR-A具有更高的透明度和可解释性。
🎯 应用场景
CLAIR-A可应用于各种自动音频描述相关的任务和应用中,例如,用于训练和评估音频描述生成模型,改进音频内容检索系统,以及为听力障碍人士提供更准确的音频描述服务。该方法具有很高的实际价值,有望推动音频理解和生成领域的发展。
📄 摘要(原文)
The Automated Audio Captioning (AAC) task asks models to generate natural language descriptions of an audio input. Evaluating these machine-generated audio captions is a complex task that requires considering diverse factors, among them, auditory scene understanding, sound-object inference, temporal coherence, and the environmental context of the scene. While current methods focus on specific aspects, they often fail to provide an overall score that aligns well with human judgment. In this work, we propose CLAIR-A, a simple and flexible method that leverages the zero-shot capabilities of large language models (LLMs) to evaluate candidate audio captions by directly asking LLMs for a semantic distance score. In our evaluations, CLAIR-A better predicts human judgements of quality compared to traditional metrics, with a 5.8% relative accuracy improvement compared to the domain-specific FENSE metric and up to 11% over the best general-purpose measure on the Clotho-Eval dataset. Moreover, CLAIR-A offers more transparency by allowing the language model to explain the reasoning behind its scores, with these explanations rated up to 30% better by human evaluators than those provided by baseline methods. CLAIR-A is made publicly available at https://github.com/DavidMChan/clair-a.