Enhancing Unsupervised Sentence Embeddings via Knowledge-Driven Data Augmentation and Gaussian-Decayed Contrastive Learning
作者: Peichao Lai, Zhengfeng Zhang, Wentao Zhang, Fangcheng Fu, Bin Cui
分类: cs.CL
发布日期: 2024-09-19 (更新: 2025-10-04)
💡 一句话要点
提出基于知识驱动数据增强和高斯衰减对比学习的无监督句子嵌入方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 无监督学习 句子嵌入 数据增强 知识图谱 对比学习
📋 核心要点
- 现有无监督句子嵌入方法依赖LLM进行数据增强,但面临数据多样性不足和噪声过大的挑战。
- 论文提出一种基于知识图谱的LLM数据增强流水线,并设计高斯衰减对比学习模型GCSE,提升模型判别能力。
- 实验表明,该方法在STS任务上取得SOTA性能,且所需数据量和LLM规模更小,验证了其效率和鲁棒性。
📝 摘要(中文)
本文提出了一种基于大型语言模型(LLMs)的数据增强流水线,并引入了高斯衰减梯度辅助对比句子嵌入(GCSE)模型,以增强无监督句子嵌入。现有方法在数据增强方面存在数据多样性不足和数据噪声过高的问题。为了解决数据多样性不足的问题,该流水线利用知识图谱(KGs)提取实体和数量,使LLMs能够生成更多样化的样本。为了解决数据噪声过高的问题,GCSE模型使用高斯衰减函数来限制错误负样本的影响,从而增强模型的区分能力。实验结果表明,该方法在语义文本相似性(STS)任务中取得了最先进的性能,并且使用更少的数据样本和更小的LLMs,证明了其在各种模型中的效率和鲁棒性。
🔬 方法详解
问题定义:现有的无监督句子嵌入方法,虽然利用大型语言模型进行数据增强,但生成的样本多样性不足,并且由于无监督数据的固有特性,容易引入噪声,导致模型学习效果不佳。具体来说,现有方法忽略了细粒度的知识,如实体和数量,限制了生成样本的多样性。同时,合成样本中可能包含不具备区分性的信息,甚至引入错误信息,影响模型的判别能力。
核心思路:论文的核心思路是通过知识驱动的数据增强来提升样本的多样性,并使用高斯衰减的对比学习方法来降低噪声的影响。通过从知识图谱中提取实体和数量,引导LLM生成更多样化的样本。同时,利用高斯衰减函数来降低潜在的错误负样本对模型训练的影响,从而提高模型的鲁棒性和判别能力。
技术框架:整体框架包含两个主要阶段:数据增强阶段和模型训练阶段。在数据增强阶段,首先利用知识图谱提取实体和数量信息,然后利用这些信息提示LLM生成更多样化的句子。在模型训练阶段,使用生成的句子对训练GCSE模型。GCSE模型采用对比学习框架,并引入高斯衰减函数来调整负样本的权重。
关键创新:论文的关键创新在于结合知识图谱进行数据增强,以及引入高斯衰减的对比学习方法。与现有方法相比,该方法能够生成更具多样性的样本,并有效降低噪声的影响。高斯衰减函数能够自适应地调整负样本的权重,从而使模型更加关注高质量的负样本,提高模型的判别能力。
关键设计:GCSE模型使用对比学习损失函数,目标是拉近相似句子之间的距离,推远不相似句子之间的距离。高斯衰减函数用于调整负样本的权重,其公式为 exp(-d^2 / (2 * sigma^2)),其中 d 是句子嵌入之间的距离,sigma 是一个可调节的参数。通过调整 sigma 的值,可以控制高斯衰减的程度。论文中,sigma 的值通过实验进行调整,以达到最佳性能。
🖼️ 关键图片
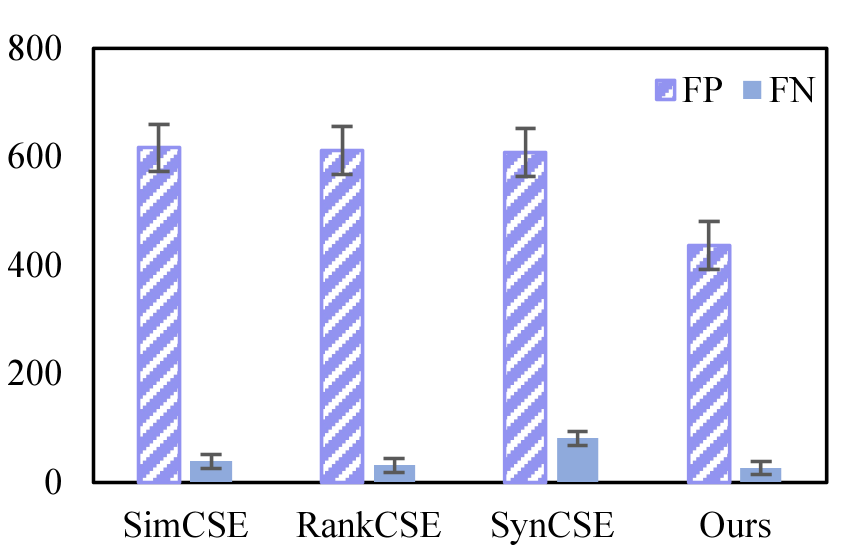

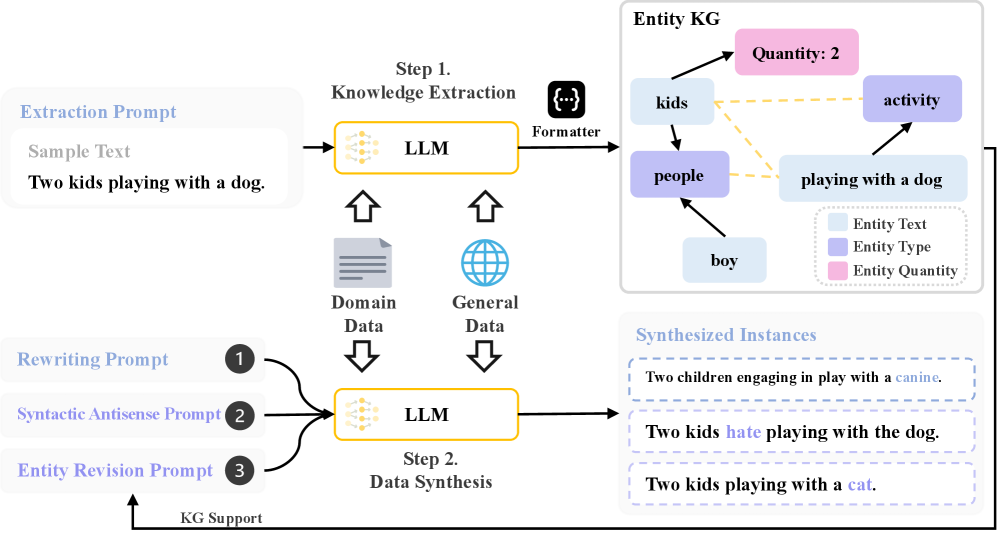
📊 实验亮点
实验结果表明,该方法在STS任务上取得了state-of-the-art的性能。例如,在STS-B数据集上,该方法相较于现有最佳方法取得了显著的提升。更重要的是,该方法使用更少的数据样本和更小的LLMs,证明了其效率和鲁棒性。这表明该方法在实际应用中具有更高的可行性。
🎯 应用场景
该研究成果可广泛应用于各种自然语言处理任务,例如语义搜索、文本分类、问答系统等。通过提升句子嵌入的质量,可以提高这些任务的性能。此外,该方法在数据量有限的情况下也能取得良好的效果,因此在低资源场景下具有重要的应用价值。未来,可以将该方法应用于跨语言场景,进一步提升其通用性。
📄 摘要(原文)
Recently, using large language models (LLMs) for data augmentation has led to considerable improvements in unsupervised sentence embedding models. However, existing methods encounter two primary challenges: limited data diversity and high data noise. Current approaches often neglect fine-grained knowledge, such as entities and quantities, leading to insufficient diversity. Besides, unsupervised data frequently lacks discriminative information, and the generated synthetic samples may introduce noise. In this paper, we propose a pipeline-based data augmentation method via LLMs and introduce the Gaussian-decayed gradient-assisted Contrastive Sentence Embedding (GCSE) model to enhance unsupervised sentence embeddings. To tackle the issue of low data diversity, our pipeline utilizes knowledge graphs (KGs) to extract entities and quantities, enabling LLMs to generate more diverse samples. To address high data noise, the GCSE model uses a Gaussian-decayed function to limit the impact of false hard negative samples, enhancing the model's discriminative capability. Experimental results show that our approach achieves state-of-the-art performance in semantic textual similarity (STS) tasks, using fewer data samples and smaller LLMs, demonstrating its efficiency and robustness across various models.