Efficient Performance Tracking: Leveraging Large Language Models for Automated Construction of Scientific Leaderboards
作者: Furkan Şahinuç, Thy Thy Tran, Yulia Grishina, Yufang Hou, Bei Chen, Iryna Gurevych
分类: cs.CL
发布日期: 2024-09-19
💡 一句话要点
提出SciLead数据集,并利用LLM自动构建科学排行榜,解决信息不完整和错误问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 科学排行榜 大型语言模型 自动构建 信息抽取 数据集构建
📋 核心要点
- 现有科学排行榜依赖社区贡献,数据质量参差不齐,存在信息不完整和错误的问题。
- 论文提出SciLead数据集,通过人工管理克服现有数据集的缺陷,并模拟真实场景。
- 构建基于LLM的框架,用于在TDM三元组不同定义程度下自动构建科学排行榜。
📝 摘要(中文)
科学排行榜是标准化的排序系统,用于评估和比较竞争方法。排行榜通常由任务、数据集和评估指标(TDM)三元组定义,从而实现客观的性能评估,并通过基准测试促进创新。然而,出版物的指数级增长使得手动构建和维护这些排行榜变得不可行。自动排行榜构建已成为减少人工劳动的一种解决方案。现有的数据集基于社区贡献的排行榜,缺乏额外的管理。我们的分析表明,这些排行榜的大部分是不完整的,并且其中一些包含不正确的信息。在这项工作中,我们提出了SciLead,一个手动管理的科学排行榜数据集,克服了上述问题。基于此数据集,我们提出了三种实验设置,模拟了在排行榜构建期间TDM三元组完全定义、部分定义或未定义的真实场景。虽然之前的研究只探讨了第一种设置,但后两种设置更具代表性。为了解决这些不同的设置,我们开发了一个基于LLM的综合框架来构建排行榜。我们的实验和分析表明,各种LLM通常可以正确识别TDM三元组,但在从出版物中提取结果值时会遇到困难。我们公开了我们的代码和数据。
🔬 方法详解
问题定义:当前科学排行榜的构建和维护面临巨大挑战,主要体现在两个方面:一是手动构建成本高昂,难以跟上论文发表速度;二是现有数据集质量不高,依赖社区贡献,缺乏人工审核,导致信息不完整甚至错误。这些问题阻碍了科学研究的有效评估和比较。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大信息提取和推理能力,实现科学排行榜的自动构建。同时,为了解决现有数据集质量问题,论文构建了高质量的人工标注数据集SciLead,用于训练和评估LLM。
技术框架:论文提出的框架主要包含以下几个阶段:1) 数据准备:构建和清洗SciLead数据集,包含任务、数据集、评估指标和性能结果等信息。2) TDM三元组识别:利用LLM识别论文中的任务、数据集和评估指标。3) 结果提取:利用LLM从论文中提取对应TDM三元组的性能结果。4) 排行榜构建:根据提取的TDM三元组和性能结果,构建科学排行榜。
关键创新:论文的关键创新在于:1) 提出了高质量的科学排行榜数据集SciLead,为相关研究提供了可靠的数据基础。2) 提出了一个基于LLM的自动排行榜构建框架,能够处理TDM三元组不同定义程度的场景,更贴近实际应用。3) 实验分析表明,LLM在TDM三元组识别方面表现良好,但在结果提取方面仍有提升空间。
关键设计:论文设计了三种实验设置,分别模拟TDM三元组完全定义、部分定义和未定义的场景,以评估LLM在不同情况下的性能。具体的技术细节包括:使用了不同的LLM模型(具体模型未知),并针对结果提取任务设计了特定的prompt,以引导LLM提取正确的结果值。损失函数和网络结构等细节信息未知。
🖼️ 关键图片

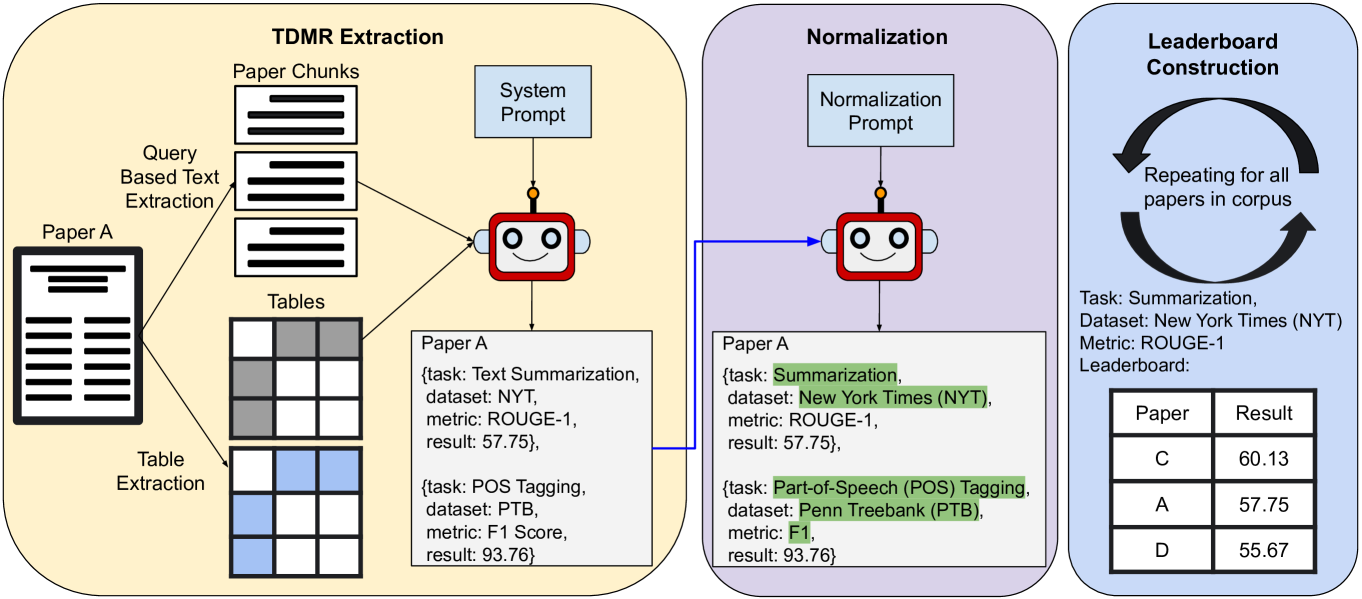
📊 实验亮点
实验结果表明,LLM在TDM三元组识别方面表现出色,但在结果提取方面仍面临挑战。具体性能数据未知,但论文强调了LLM在识别任务上的优势,以及在提取数值结果方面的改进空间。SciLead数据集的构建为后续研究提供了高质量的数据基础。
🎯 应用场景
该研究成果可应用于自动化科学研究评估、快速构建领域知识图谱、辅助科研人员进行文献综述和方法对比,并可用于构建智能科研助手,提升科研效率。未来,该技术有望扩展到其他领域,例如医疗、金融等,实现领域知识的自动化管理和应用。
📄 摘要(原文)
Scientific leaderboards are standardized ranking systems that facilitate evaluating and comparing competitive methods. Typically, a leaderboard is defined by a task, dataset, and evaluation metric (TDM) triple, allowing objective performance assessment and fostering innovation through benchmarking. However, the exponential increase in publications has made it infeasible to construct and maintain these leaderboards manually. Automatic leaderboard construction has emerged as a solution to reduce manual labor. Existing datasets for this task are based on the community-contributed leaderboards without additional curation. Our analysis shows that a large portion of these leaderboards are incomplete, and some of them contain incorrect information. In this work, we present SciLead, a manually-curated Scientific Leaderboard dataset that overcomes the aforementioned problems. Building on this dataset, we propose three experimental settings that simulate real-world scenarios where TDM triples are fully defined, partially defined, or undefined during leaderboard construction. While previous research has only explored the first setting, the latter two are more representative of real-world applications. To address these diverse settings, we develop a comprehensive LLM-based framework for constructing leaderboards. Our experiments and analysis reveal that various LLMs often correctly identify TDM triples while struggling to extract result values from publications. We make our code and data publicly available.