Enhancing Knowledge Distillation of Large Language Models through Efficient Multi-Modal Distribution Alignment
作者: Tianyu Peng, Jiajun Zhang
分类: cs.CL
发布日期: 2024-09-19 (更新: 2024-12-18)
备注: Accepted by COLING 2025, 19 pages
💡 一句话要点
提出基于排序损失的知识蒸馏方法,提升小模型学习大模型多模态分布的能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 大型语言模型 多模态分布 排序损失 模型压缩
📋 核心要点
- 现有知识蒸馏方法难以有效学习大型语言模型的多模态概率分布,导致学生模型性能受限。
- 提出基于排序损失的知识蒸馏(RLKD),通过对齐师生模型预测峰值的排序来学习多模态分布。
- 实验表明,RLKD能使学生模型更好地学习教师模型的多模态分布,并在下游任务中取得显著的性能提升。
📝 摘要(中文)
知识蒸馏(KD)是一种有效的模型压缩方法,可以将大型语言模型(LLM)的内部能力转移到较小的模型上。然而,教师LLM预测的多模态概率分布给学生模型的学习带来了困难。本文首先通过实验证明了多模态分布对齐的重要性,然后强调了现有KD方法在学习多模态分布方面的低效性。为了解决这个问题,我们提出了基于排序损失的知识蒸馏(RLKD),它鼓励教师模型和学生模型之间峰值预测排序的一致性。通过结合词级别的排序损失,我们确保了与现有蒸馏目标的良好兼容性,同时充分利用了两个预测分布峰值中不同类别之间的细粒度信息。实验结果表明,我们的方法使学生模型能够更好地学习教师模型的多模态分布,从而在各种下游任务中显著提高性能。
🔬 方法详解
问题定义:现有知识蒸馏方法在将大型语言模型(LLM)的知识迁移到小型模型时,面临着学生模型难以学习教师模型输出的多模态概率分布的问题。教师模型预测的概率分布通常包含多个可能的答案(峰值),而传统的知识蒸馏方法往往侧重于模仿教师模型的单一最佳预测,忽略了其他潜在的正确答案,导致学生模型无法充分学习教师模型的知识。
核心思路:论文的核心思路是通过对齐教师模型和学生模型预测结果的排序,来促使学生模型学习教师模型的多模态分布。具体来说,该方法鼓励学生模型预测的概率分布中,各个候选答案的相对排序与教师模型保持一致。这样,即使学生模型无法完全复制教师模型的概率值,也能学习到不同答案之间的重要性关系,从而更好地理解教师模型的知识。
技术框架:该方法在传统的知识蒸馏框架中引入了一个新的排序损失项。整体流程如下:首先,教师模型和学生模型分别对输入进行预测,得到各自的概率分布。然后,计算教师模型和学生模型预测结果的排序,并使用排序损失函数来衡量两个排序之间的差异。最后,将排序损失与现有的蒸馏损失(如KL散度)结合起来,共同优化学生模型。
关键创新:该方法的关键创新在于引入了排序损失来对齐师生模型预测结果的排序。与传统的知识蒸馏方法相比,该方法更加关注不同候选答案之间的相对关系,而不是仅仅模仿教师模型的单一最佳预测。这使得学生模型能够更好地学习教师模型的多模态分布,从而提高模型的泛化能力。
关键设计:论文使用了词级别的排序损失,这意味着排序是基于每个词的预测概率进行的。排序损失的具体形式未知,但通常可以使用诸如pairwise ranking loss或listwise ranking loss等方法。此外,该方法与现有的蒸馏目标兼容,可以灵活地与其他蒸馏损失函数结合使用。具体参数设置未知。
🖼️ 关键图片

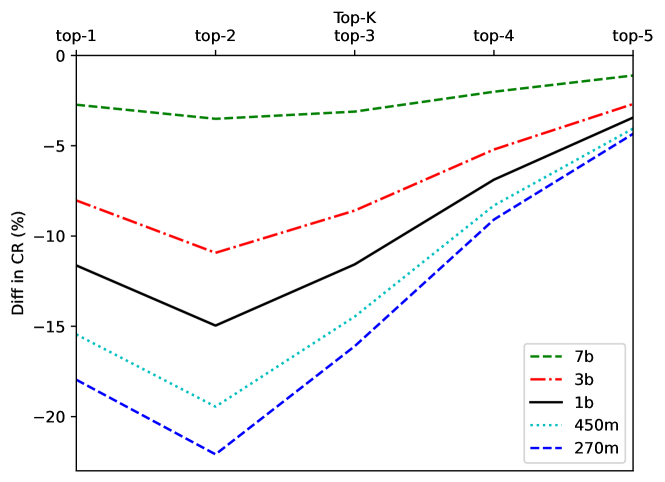

📊 实验亮点
实验结果表明,提出的RLKD方法能够显著提高学生模型的性能。具体提升幅度未知,但论文强调该方法使学生模型更好地学习教师模型的多模态分布,从而在各种下游任务中取得了显著的性能提升。该方法与现有蒸馏目标兼容,易于集成到现有的知识蒸馏框架中。
🎯 应用场景
该研究成果可应用于各种需要模型压缩的场景,例如移动设备上的自然语言处理、边缘计算等。通过知识蒸馏,可以将大型语言模型的强大能力迁移到小型模型上,从而在资源受限的环境中实现高性能的自然语言处理应用。此外,该方法还可以用于提高模型的鲁棒性和泛化能力,使其在面对噪声数据或未见过的任务时表现更好。
📄 摘要(原文)
Knowledge distillation (KD) is an effective model compression method that can transfer the internal capabilities of large language models (LLMs) to smaller ones. However, the multi-modal probability distribution predicted by teacher LLMs causes difficulties for student models to learn. In this paper, we first demonstrate the importance of multi-modal distribution alignment with experiments and then highlight the inefficiency of existing KD approaches in learning multi-modal distributions. To address this problem, we propose Ranking Loss based Knowledge Distillation (RLKD), which encourages the consistency of the ranking of peak predictions between the teacher and student models. By incorporating word-level ranking loss, we ensure excellent compatibility with existing distillation objectives while fully leveraging the fine-grained information between different categories in peaks of two predicted distribution. Experimental results demonstrate that our method enables the student model to better learn the multi-modal distributions of the teacher model, leading to a significant performance improvement in various downstream tasks.