Familiarity-Aware Evidence Compression for Retrieval-Augmented Generation
作者: Dongwon Jung, Qin Liu, Tenghao Huang, Ben Zhou, Muhao Chen
分类: cs.CL, cs.AI, cs.IR, cs.LG
发布日期: 2024-09-19 (更新: 2025-10-17)
备注: EMNLP 2025 Findings
💡 一句话要点
提出FaviComp,一种兼顾模型熟悉度的检索增强生成证据压缩方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 证据压缩 开放域问答 知识融合 大型语言模型
📋 核心要点
- RAG方法易受检索到的不相关信息干扰,影响生成质量,证据压缩是解决方案之一。
- FaviComp通过使压缩后的证据更贴合目标模型的知识体系,提升证据利用率。
- 实验表明,FaviComp在开放域问答任务中显著优于现有压缩方法,准确率提升高达28.1%。
📝 摘要(中文)
检索增强生成(RAG)通过整合来自外部源的检索证据,来提升大型语言模型(LM)的能力。然而,RAG常常难以处理不一致和不相关的信息,这些信息会分散LM的注意力,尤其是在需要多条证据时。虽然使用压缩模型压缩检索到的证据旨在解决这个问题,但压缩后的证据对于下游任务的目标模型来说可能仍然不熟悉,从而无法有效地利用这些证据。我们提出FaviComp (Familarity-Aware Evidence Compression),一种新颖的免训练证据压缩技术,使检索到的证据对目标模型更加熟悉,同时无缝地整合来自模型的参数化知识。实验结果表明,FaviComp在多个开放域问答数据集上始终优于最新的证据压缩基线,在实现高压缩率的同时,准确率提高了高达28.1%。此外,我们还展示了在证据压缩过程中参数化知识和非参数化知识的有效整合。
🔬 方法详解
问题定义:RAG模型在利用检索到的外部知识时,容易受到噪声信息的影响,导致生成质量下降。现有的证据压缩方法试图过滤掉无关信息,但压缩后的证据可能与目标语言模型的固有知识存在gap,导致模型难以有效利用这些压缩后的信息。因此,如何使压缩后的证据既包含有效信息,又与目标模型“熟悉”,是本文要解决的核心问题。
核心思路:FaviComp的核心思路是在证据压缩过程中,同时考虑非参数化知识(检索到的证据)和参数化知识(目标语言模型自身的知识)。通过某种方式,将压缩后的证据调整到更符合目标模型“认知”的状态,从而提高模型对压缩后证据的利用效率。这种“熟悉度”的提升,能够帮助模型更好地理解和整合外部知识,最终提升生成质量。
技术框架:FaviComp是一个免训练的证据压缩技术,其整体流程可以概括为:首先,利用检索模块获取相关证据;然后,使用FaviComp对证据进行压缩,使其更符合目标模型的知识体系;最后,将压缩后的证据输入到生成模型中,生成最终答案。该框架的关键在于FaviComp模块的设计,它负责在不进行额外训练的情况下,提升证据与目标模型之间的熟悉度。
关键创新:FaviComp的关键创新在于其“熟悉度感知”的证据压缩方法。与传统的证据压缩方法不同,FaviComp不仅关注证据的信息量,更关注证据与目标模型之间的关联性。通过某种机制(具体细节未知),FaviComp能够识别并保留那些与目标模型知识体系更契合的证据片段,从而提高模型对压缩后证据的理解和利用效率。这种“熟悉度感知”的压缩方法,是FaviComp优于现有方法的核心原因。
关键设计:论文中并未详细描述FaviComp的具体实现细节,例如如何量化“熟悉度”,以及如何根据“熟悉度”进行证据压缩。这些细节可能涉及到特定的算法或模型设计,需要在论文正文中进一步查找。目前已知的是,FaviComp是一种免训练的方法,这意味着它可能依赖于某种预定义的规则或启发式方法来评估和压缩证据。
🖼️ 关键图片

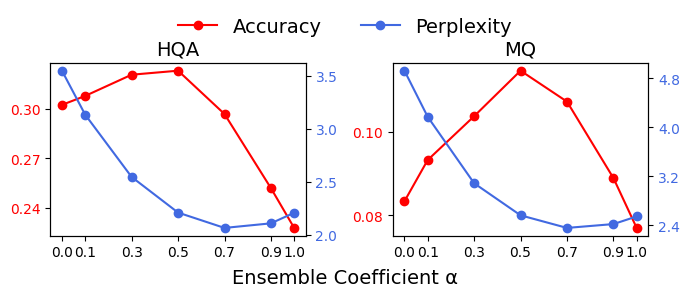

📊 实验亮点
实验结果表明,FaviComp在多个开放域问答数据集上显著优于现有的证据压缩基线方法。具体而言,FaviComp在准确率方面取得了高达28.1%的提升,同时保持了较高的压缩率。这些结果充分证明了FaviComp在提升模型对检索证据利用效率方面的有效性。
🎯 应用场景
FaviComp可广泛应用于各种需要检索增强生成的场景,例如开放域问答、知识图谱推理、对话生成等。通过提升模型对检索证据的利用效率,FaviComp能够显著提高这些应用的性能和可靠性。未来,FaviComp有望成为RAG框架中的一个重要组成部分,推动RAG技术在更多领域的应用。
📄 摘要(原文)
Retrieval-augmented generation (RAG) improves large language models (LMs) by incorporating non-parametric knowledge through evidence retrieved from external sources. However, it often struggles to cope with inconsistent and irrelevant information that can distract the LM from its tasks, especially when multiple evidence pieces are required. While compressing the retrieved evidence with a compression model aims to address this issue, the compressed evidence may still be unfamiliar to the target model used for downstream tasks, potentially failing to utilize the evidence effectively. We propose FaviComp (Familarity-Aware Evidence Compression), a novel training-free evidence compression technique that makes retrieved evidence more familiar to the target model, while seamlessly integrating parametric knowledge from the model. Experimental results show that FaviComp consistently outperforms most recent evidence compression baselines across multiple open-domain QA datasets, improving accuracy by up to 28.1% while achieving high compression rates. Additionally, we demonstrate the effective integration of both parametric and non-parametric knowledge during evidence compression.