Linguistic Minimal Pairs Elicit Linguistic Similarity in Large Language Models
作者: Xinyu Zhou, Delong Chen, Samuel Cahyawijaya, Xufeng Duan, Zhenguang G. Cai
分类: cs.CL
发布日期: 2024-09-19 (更新: 2024-12-13)
备注: COLING 2025
🔗 代码/项目: GITHUB
💡 一句话要点
利用语言最小对探究大型语言模型的语言相似性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 语言相似性 最小对 激活差异 跨语言对齐 理论语言学 自然语言处理
📋 核心要点
- 现有方法在探测大型语言模型的语言表示时缺乏有效的分析工具,难以量化语言知识的捕获情况。
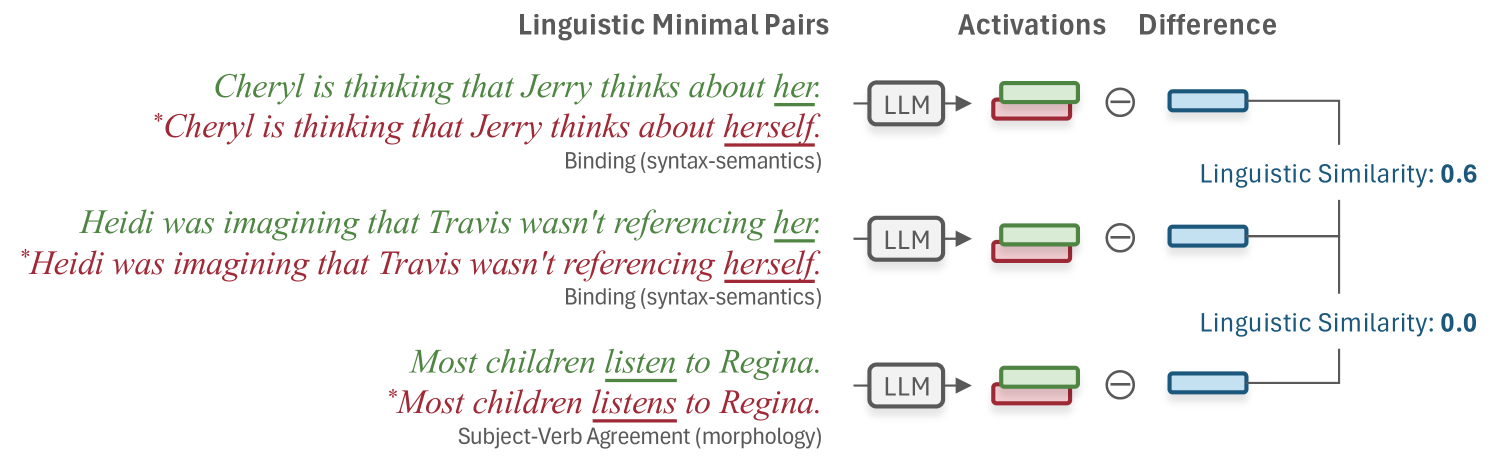
- 本研究提出利用语言最小对作为分析工具,通过激活差异测量来探究LLMs的语言相似性。
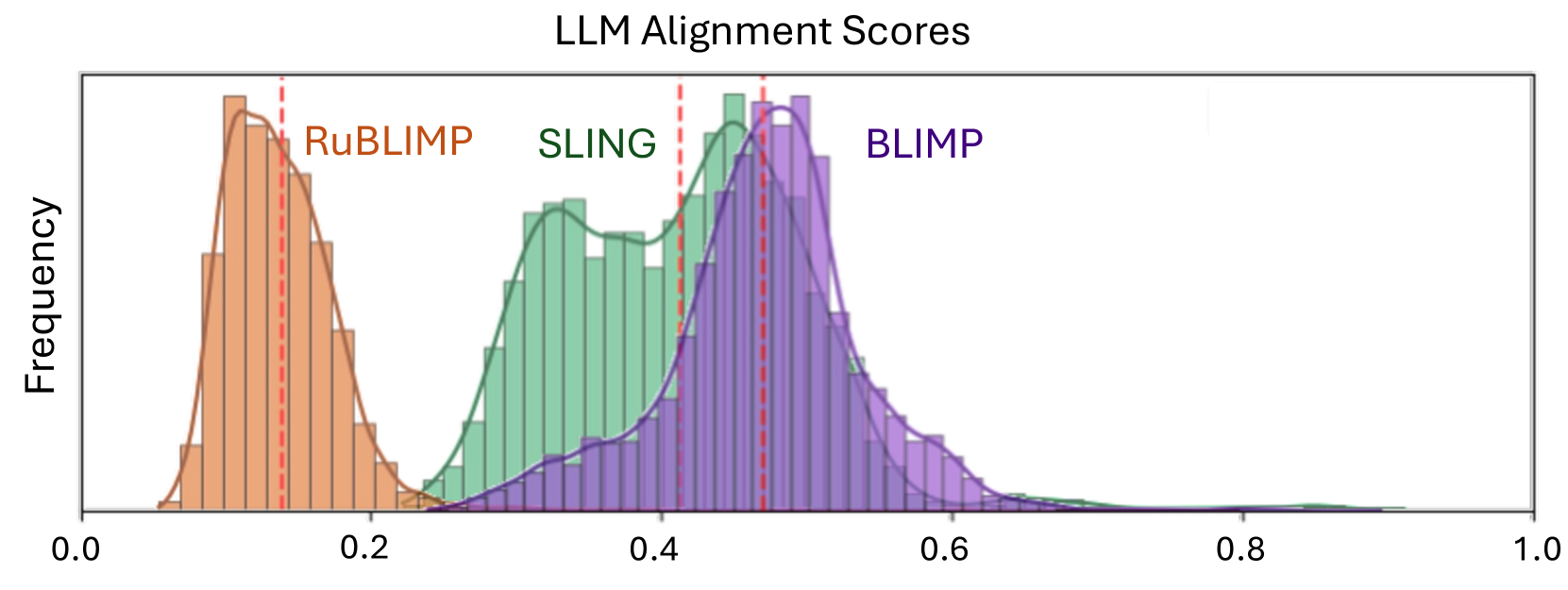
- 实验结果显示,语言相似性受训练数据影响显著,且与理论语言学类别高度一致,揭示了LLMs的语言理解特性。
📝 摘要(中文)
本研究引入了一种新颖的分析方法,通过语言最小对来探测大型语言模型(LLMs)内部的语言表示。我们通过测量最小对之间的LLM激活差异的相似性,量化并深入了解LLMs所捕获的语言知识。大规模实验涵盖100多种LLMs和15万对最小对,揭示了语言相似性的四个关键方面:LLMs之间的一致性、与理论分类的关系、对语义上下文的依赖性,以及相关现象的跨语言对齐。研究结果表明,语言相似性受训练数据暴露的显著影响,并且与细粒度的理论语言学类别高度一致,但与更广泛的类别关联较弱。LLMs在理解相关语言现象时表现出有限的跨语言对齐能力。
🔬 方法详解
问题定义:本研究旨在解决如何有效探测大型语言模型内部的语言表示及其相似性的问题。现有方法缺乏针对性分析工具,难以深入理解LLMs的语言知识捕获情况。
核心思路:通过引入语言最小对,利用其激活差异来量化LLMs的语言相似性,从而揭示其内部语言知识的结构和特性。这样的设计能够有效捕捉到模型对语言细微差别的敏感性。
技术框架:整体架构包括数据收集、激活差异计算、相似性量化和结果分析四个主要模块。首先收集多种语言的最小对数据,然后计算LLMs在这些输入下的激活差异,最后通过统计分析量化相似性。
关键创新:本研究的主要创新在于将语言最小对作为分析工具,提供了一种新的视角来理解LLMs的语言表示,与传统的直接比较方法相比,能够更细致地揭示语言知识的结构。
关键设计:在实验中,选择了多种LLMs作为研究对象,并设定了激活差异的计算方法,使用了特定的相似性度量标准,以确保结果的可靠性和有效性。
🖼️ 关键图片

📊 实验亮点
实验结果显示,语言相似性在高资源语言中表现出更高的跨模型一致性,且与细粒度的理论语言学类别高度一致。研究还发现,语言相似性与语义相似性之间的相关性较弱,显示出其上下文依赖性。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、语言学研究和教育技术等。通过深入理解LLMs的语言表示,可以为语言模型的优化和应用提供理论支持,推动相关技术的发展与应用。
📄 摘要(原文)
We introduce a novel analysis that leverages linguistic minimal pairs to probe the internal linguistic representations of Large Language Models (LLMs). By measuring the similarity between LLM activation differences across minimal pairs, we quantify the and gain insight into the linguistic knowledge captured by LLMs. Our large-scale experiments, spanning 100+ LLMs and 150k minimal pairs in three languages, reveal properties of linguistic similarity from four key aspects: consistency across LLMs, relation to theoretical categorizations, dependency to semantic context, and cross-lingual alignment of relevant phenomena. Our findings suggest that 1) linguistic similarity is significantly influenced by training data exposure, leading to higher cross-LLM agreement in higher-resource languages. 2) Linguistic similarity strongly aligns with fine-grained theoretical linguistic categories but weakly with broader ones. 3) Linguistic similarity shows a weak correlation with semantic similarity, showing its context-dependent nature. 4) LLMs exhibit limited cross-lingual alignment in their understanding of relevant linguistic phenomena. This work demonstrates the potential of minimal pairs as a window into the neural representations of language in LLMs, shedding light on the relationship between LLMs and linguistic theory. Codes and data are available at https://github.com/ChenDelong1999/Linguistic-Similarity