Mutual Information-based Representations Disentanglement for Unaligned Multimodal Language Sequences
作者: Fan Qian, Jiqing Han, Jianchen Li, Yongjun He, Tieran Zheng, Guibin Zheng
分类: cs.CL, cs.MM
发布日期: 2024-09-19
备注: 31 pages, 8 figures
💡 一句话要点
提出基于互信息解耦的MIRD方法,解决非对齐多模态语言序列的信息冗余问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 表示解耦 互信息最小化 非对齐序列 模态无关表示 模态特定表示 信息冗余
📋 核心要点
- 现有方法在非对齐多模态序列中独立学习各模态的模态无关表示,忽略了非线性相关性,导致信息冗余。
- MIRD方法设计了解耦框架,联合学习单个模态无关表示,并采用互信息最小化约束,消除信息冗余。
- 实验结果表明,MIRD方法在多个基准数据集上表现出色,验证了其有效性,并引入无标签数据进一步提升性能。
📝 摘要(中文)
非对齐多模态语言序列的关键挑战在于有效整合来自不同模态的信息,以获得精细的多模态联合表示。最近,解耦和融合方法通过显式学习模态无关和模态特定的表示,然后将它们融合到多模态联合表示中,取得了有希望的性能。然而,这些方法通常独立地学习每个模态的模态无关表示,并利用正交约束来减少模态无关和模态特定表示之间的线性相关性,忽略了消除它们的非线性相关性。因此,获得的多模态联合表示通常存在信息冗余,导致模型的过拟合和泛化能力差。在本文中,我们提出了一种基于互信息解耦(MIRD)的非对齐多模态语言序列方法,其中设计了一种新的解耦框架来联合学习单个模态无关表示。此外,采用互信息最小化约束来确保表示的优越解耦,从而消除多模态联合表示中的信息冗余。同时,通过引入无标签数据来缓解由有限的标签数据引起的互信息估计的挑战。同时,无标签数据也有助于表征多模态数据的底层结构,从而进一步防止过拟合,提高模型的性能。在几个广泛使用的基准数据集上的实验结果验证了我们提出的方法的有效性。
🔬 方法详解
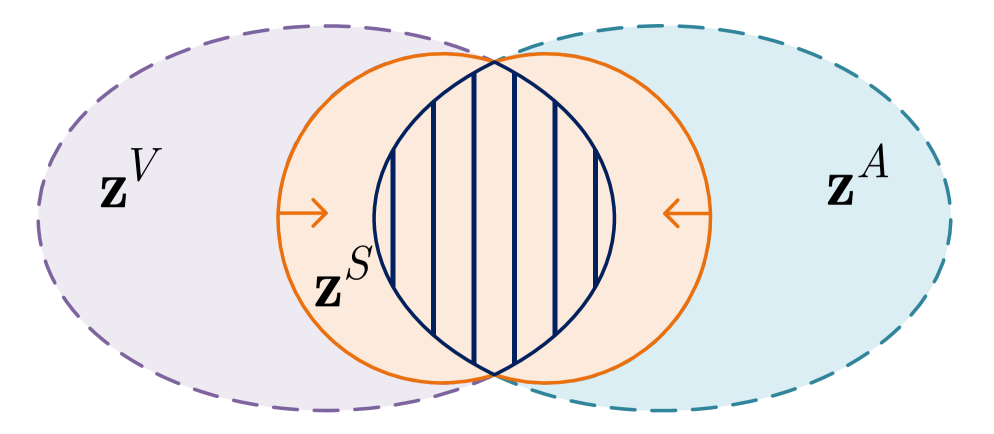
问题定义:现有方法在处理非对齐多模态语言序列时,通常独立学习每个模态的模态无关表示,并且仅使用正交约束来降低模态无关和模态特定表示之间的线性相关性。这种做法忽略了两者之间可能存在的非线性相关性,导致最终的多模态联合表示包含冗余信息,进而影响模型的泛化能力和容易过拟合。
核心思路:MIRD的核心思路是通过联合学习一个统一的模态无关表示,并利用互信息最小化约束来显式地减少模态无关和模态特定表示之间的信息共享,从而实现更彻底的解耦。这样可以有效消除多模态联合表示中的冗余信息,提升模型的泛化能力。
技术框架:MIRD方法包含以下主要模块:1. 特征提取模块:用于从各个模态的输入序列中提取特征。2. 解耦模块:该模块是MIRD的核心,它联合学习一个模态无关表示,并学习各个模态的模态特定表示。3. 互信息最小化模块:通过最小化模态无关表示和模态特定表示之间的互信息,实现更彻底的解耦。4. 融合模块:将模态无关表示和模态特定表示融合,得到最终的多模态联合表示。5. 预测模块:利用多模态联合表示进行预测。
关键创新:MIRD的关键创新在于:1. 联合学习单个模态无关表示,避免了独立学习造成的冗余。2. 引入互信息最小化约束,显式地减少模态无关和模态特定表示之间的信息共享,实现更彻底的解耦。3. 利用无标签数据缓解了互信息估计的挑战,并帮助模型学习多模态数据的底层结构。
关键设计:1. 互信息估计:采用基于神经网络的互信息估计器,并利用无标签数据进行训练,以提高估计的准确性。2. 损失函数:损失函数包括预测损失、互信息损失和重构损失。预测损失用于指导模型进行预测,互信息损失用于减少模态无关和模态特定表示之间的信息共享,重构损失用于保证模态特定表示包含足够的信息。3. 网络结构:解耦模块采用编码器-解码器结构,编码器用于提取特征,解码器用于重构输入序列。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MIRD方法在多个基准数据集上取得了显著的性能提升。例如,在MOSI数据集上,MIRD方法相比于现有最佳方法,在7分类准确率上提升了2.3%,在二分类准确率上提升了1.8%。这些结果验证了MIRD方法在处理非对齐多模态语言序列方面的有效性。
🎯 应用场景
MIRD方法可应用于各种需要处理非对齐多模态语言序列的任务,例如情感分析、对话系统、视频理解等。通过提升多模态表示的质量,MIRD可以提高这些任务的性能,并促进更自然、更智能的人机交互。未来,该方法可以进一步扩展到更多模态和更复杂的场景。
📄 摘要(原文)
The key challenge in unaligned multimodal language sequences lies in effectively integrating information from various modalities to obtain a refined multimodal joint representation. Recently, the disentangle and fuse methods have achieved the promising performance by explicitly learning modality-agnostic and modality-specific representations and then fusing them into a multimodal joint representation. However, these methods often independently learn modality-agnostic representations for each modality and utilize orthogonal constraints to reduce linear correlations between modality-agnostic and modality-specific representations, neglecting to eliminate their nonlinear correlations. As a result, the obtained multimodal joint representation usually suffers from information redundancy, leading to overfitting and poor generalization of the models. In this paper, we propose a Mutual Information-based Representations Disentanglement (MIRD) method for unaligned multimodal language sequences, in which a novel disentanglement framework is designed to jointly learn a single modality-agnostic representation. In addition, the mutual information minimization constraint is employed to ensure superior disentanglement of representations, thereby eliminating information redundancy within the multimodal joint representation. Furthermore, the challenge of estimating mutual information caused by the limited labeled data is mitigated by introducing unlabeled data. Meanwhile, the unlabeled data also help to characterize the underlying structure of multimodal data, consequently further preventing overfitting and enhancing the performance of the models. Experimental results on several widely used benchmark datasets validate the effectiveness of our proposed approach.