Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
作者: An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, Keming Lu, Mingfeng Xue, Runji Lin, Tianyu Liu, Xingzhang Ren, Zhenru Zhang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-09-18
💡 一句话要点
Qwen2.5-Math:通过自提升策略构建数学专家模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数学大语言模型 自提升学习 奖励模型 思维链 工具集成推理 监督微调 强化学习
📋 核心要点
- 现有数学大语言模型在数据质量和训练策略上存在提升空间,难以充分挖掘模型潜力。
- Qwen2.5-Math 通过自提升策略,在预训练、后训练和推理阶段均融入自迭代优化机制,持续提升模型性能。
- 实验结果表明,Qwen2.5-Math 在多个中英文数学数据集上取得了显著提升,展现了强大的数学推理能力。
📝 摘要(中文)
本报告介绍了一系列数学专用的大型语言模型:Qwen2.5-Math 和 Qwen2.5-Math-Instruct-1.5B/7B/72B。Qwen2.5 系列的核心创新在于将自提升的理念融入到整个流程中,从预训练、后训练到推理:(1) 在预训练阶段,利用 Qwen2-Math-Instruct 生成大规模、高质量的数学数据。(2) 在后训练阶段,通过对 Qwen2-Math-Instruct 进行大规模采样,开发了一个奖励模型 (RM)。然后将此 RM 应用于监督微调 (SFT) 中数据的迭代演化。通过更强大的 SFT 模型,可以迭代地训练和更新 RM,进而指导下一轮 SFT 数据迭代。在最终的 SFT 模型上,我们采用最终的 RM 进行强化学习,从而得到 Qwen2.5-Math-Instruct。(3) 此外,在推理阶段,RM 用于指导采样,优化模型的性能。Qwen2.5-Math-Instruct 支持中文和英文,并具有先进的数学推理能力,包括思维链 (CoT) 和工具集成推理 (TIR)。我们在英语和中文的 10 个数学数据集上评估了我们的模型,例如 GSM8K、MATH、GaoKao、AMC23 和 AIME24,涵盖了从小学水平到数学竞赛问题的各种难度。
🔬 方法详解
问题定义:现有的大语言模型在解决复杂的数学问题时,往往面临数据质量不高、训练方式不够精细等问题,导致模型无法充分学习和掌握数学推理能力。如何有效地利用有限的计算资源,训练出更强大的数学专家模型是一个挑战。
核心思路:论文的核心思路是采用自提升(Self-Improvement)策略,通过迭代的方式不断提升模型的性能。具体来说,就是利用模型自身的能力生成更高质量的数据,并利用这些数据反过来训练模型,从而形成一个正向循环。这种方法可以有效地利用模型自身的知识,逐步提升其解决数学问题的能力。
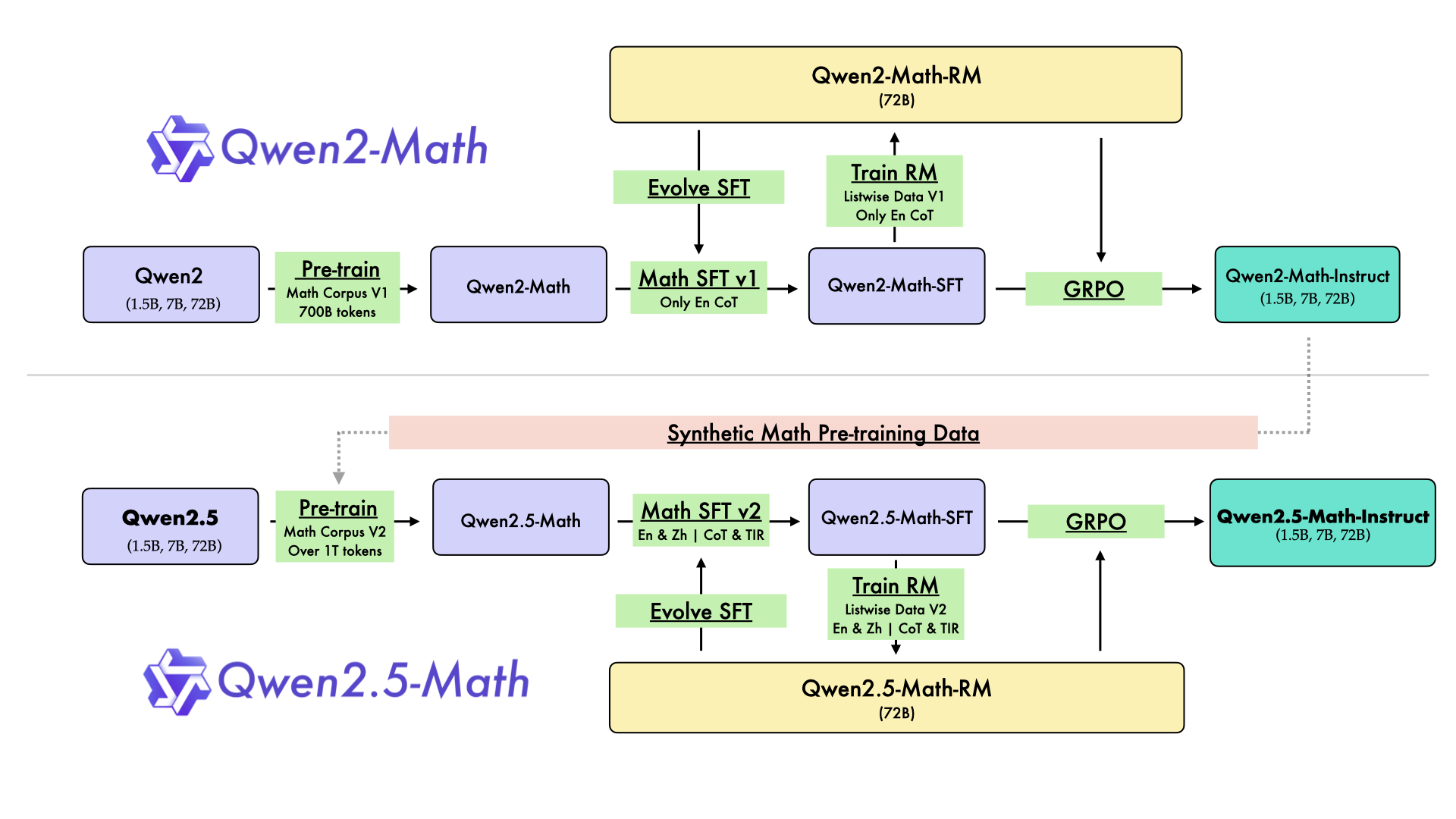
技术框架:整体框架包含预训练、后训练和推理三个阶段。在预训练阶段,使用 Qwen2-Math-Instruct 生成大规模数学数据。在后训练阶段,首先训练一个奖励模型(RM),然后使用该 RM 指导监督微调(SFT)数据的迭代演化。通过迭代训练和更新 RM,最终使用 RM 进行强化学习。在推理阶段,RM 用于指导采样,优化模型性能。
关键创新:最重要的技术创新点在于将自提升的理念贯穿于整个训练流程。与传统的单次训练方法不同,Qwen2.5-Math 通过迭代的方式不断提升数据质量和模型性能。这种方法可以有效地利用模型自身的知识,逐步提升其解决数学问题的能力。此外,在推理阶段使用 RM 指导采样也是一个创新点,可以进一步提升模型的性能。
关键设计:在后训练阶段,奖励模型(RM)的设计至关重要。RM 的目标是评估模型生成的数学解题过程的质量。论文通过对 Qwen2-Math-Instruct 进行大规模采样来训练 RM。此外,SFT 数据的迭代演化也需要精心设计,以确保每次迭代都能提升数据质量和模型性能。具体的参数设置、损失函数和网络结构等技术细节在论文中可能有所描述,但此处无法详细展开。
🖼️ 关键图片


📊 实验亮点
Qwen2.5-Math 在多个中英文数学数据集上取得了显著的性能提升,例如在 GSM8K、MATH、GaoKao、AMC23 和 AIME24 等数据集上均取得了优异的成绩。具体的数据提升幅度需要在论文中查找,但整体而言,该模型展现了强大的数学推理能力,超越了之前的模型。
🎯 应用场景
Qwen2.5-Math 在教育、科研等领域具有广泛的应用前景。它可以作为智能辅导系统的一部分,帮助学生解决数学难题,提供个性化的学习体验。此外,该模型还可以用于数学研究,辅助科研人员进行复杂的数学建模和计算,加速科研进展。
📄 摘要(原文)
In this report, we present a series of math-specific large language models: Qwen2.5-Math and Qwen2.5-Math-Instruct-1.5B/7B/72B. The core innovation of the Qwen2.5 series lies in integrating the philosophy of self-improvement throughout the entire pipeline, from pre-training and post-training to inference: (1) During the pre-training phase, Qwen2-Math-Instruct is utilized to generate large-scale, high-quality mathematical data. (2) In the post-training phase, we develop a reward model (RM) by conducting massive sampling from Qwen2-Math-Instruct. This RM is then applied to the iterative evolution of data in supervised fine-tuning (SFT). With a stronger SFT model, it's possible to iteratively train and update the RM, which in turn guides the next round of SFT data iteration. On the final SFT model, we employ the ultimate RM for reinforcement learning, resulting in the Qwen2.5-Math-Instruct. (3) Furthermore, during the inference stage, the RM is used to guide sampling, optimizing the model's performance. Qwen2.5-Math-Instruct supports both Chinese and English, and possess advanced mathematical reasoning capabilities, including Chain-of-Thought (CoT) and Tool-Integrated Reasoning (TIR). We evaluate our models on 10 mathematics datasets in both English and Chinese, such as GSM8K, MATH, GaoKao, AMC23, and AIME24, covering a range of difficulties from grade school level to math competition problems.