Revealing and Mitigating the Challenge of Detecting Character Knowledge Errors in LLM Role-Playing
作者: Wenyuan Zhang, Shuaiyi Nie, Jiawei Sheng, Zefeng Zhang, Xinghua Zhang, Yongquan He, Tingwen Liu
分类: cs.CL, cs.HC
发布日期: 2024-09-18 (更新: 2025-05-20)
备注: 25 pages, 6 figures, 20 tables
💡 一句话要点
提出RoleKE-Bench,揭示并缓解LLM角色扮演中角色知识错误检测的挑战
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM角色扮演 知识错误检测 RoleKE-Bench 自我回忆 自我怀疑 代理推理 知识库 基准测试
📋 核心要点
- 现有LLM角色扮演研究忽略了LLM检测角色已知和未知知识错误的能力,导致自动构建高质量角色语料库面临挑战。
- 论文提出RoleKE-Bench基准,用于评估LLM检测角色知识错误的能力,并设计了基于代理的推理方法S$^2$RD来提升检测性能。
- 实验结果表明,即使是最新的LLM在检测角色知识错误方面表现不佳,而提出的S$^2$RD方法能够有效提高LLM的错误检测能力。
📝 摘要(中文)
大型语言模型(LLM)角色扮演受到了广泛关注。真实的角色知识对于构建逼真的LLM角色扮演代理至关重要。然而,现有工作通常忽略了LLM在角色扮演时检测角色已知知识错误(KKE)和未知知识错误(UKE)的能力,这会导致角色可训练语料库的自动构建质量低下。在本文中,我们提出了RoleKE-Bench来评估LLM检测KKE和UKE错误的能力。结果表明,即使是最新的LLM也难以有效地检测这两种类型的错误,尤其是在面对熟悉的知识时。我们尝试了各种推理策略,并提出了一种基于代理的推理方法,即自我回忆和自我怀疑(S$^2$RD),以进一步探索提高错误检测能力的潜力。实验表明,我们的方法有效地提高了LLM检测角色知识错误的能力,但这仍然是一个需要持续关注的问题。
🔬 方法详解
问题定义:论文旨在解决LLM在角色扮演过程中,难以准确检测角色已知知识错误(KKE)和未知知识错误(UKE)的问题。现有方法主要关注生成逼真的角色回复,而忽略了LLM对角色知识的理解和辨别能力,这导致自动构建高质量角色扮演训练语料库变得困难。LLM无法有效识别角色知识中的错误,会降低角色扮演的真实性和可靠性。
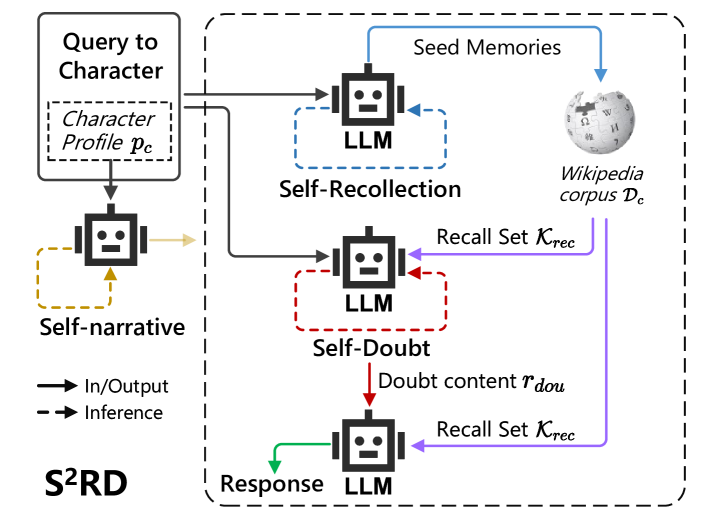
核心思路:论文的核心思路是构建一个专门用于评估LLM角色知识错误检测能力的基准RoleKE-Bench,并提出一种基于代理的推理方法S$^2$RD(Self-Recollection and Self-Doubt),通过模拟人类的自我反思和质疑过程,来提高LLM对角色知识错误的检测能力。这种方法旨在让LLM在生成回复前,先回忆相关知识,然后对自己的判断进行质疑,从而更准确地识别错误。
技术框架:整体框架包含两个主要部分:RoleKE-Bench基准的构建和S$^2$RD方法的应用。RoleKE-Bench包含KKE和UKE两种类型的错误,用于全面评估LLM的错误检测能力。S$^2$RD方法作为一个独立的模块,可以嵌入到现有的LLM角色扮演系统中。该方法首先让LLM回忆相关知识,然后生成一个初始回复,接着让LLM对自己的回复进行质疑,并根据质疑结果修改回复。
关键创新:论文的关键创新在于提出了RoleKE-Bench基准,这是首个专门用于评估LLM角色知识错误检测能力的基准。此外,S$^2$RD方法通过模拟人类的自我反思和质疑过程,有效地提高了LLM的错误检测能力。与现有方法相比,S$^2$RD方法更加注重LLM对角色知识的理解和辨别,而不是仅仅关注生成逼真的回复。
关键设计:S$^2$RD方法的关键设计包括:1) 自我回忆阶段:利用LLM的知识库回忆与当前问题相关的角色知识。2) 自我质疑阶段:设计特定的prompt,引导LLM对自己的回答进行质疑,例如“这个回答是否符合角色的性格?”、“这个回答是否与角色的已知知识相符?”。3) 回复修正阶段:根据质疑的结果,对初始回复进行修改,以消除错误。具体的参数设置和损失函数未知,因为论文摘要中没有提及。
🖼️ 关键图片


📊 实验亮点
实验结果表明,即使是最新的LLM在RoleKE-Bench基准上的表现仍然不佳,表明LLM在角色知识错误检测方面存在显著挑战。提出的S$^2$RD方法能够有效提高LLM的错误检测能力,但具体的性能提升数据未知,因为摘要中没有给出具体的数值结果。该研究强调了LLM角色扮演中知识错误检测的重要性,并为未来的研究提供了新的方向。
🎯 应用场景
该研究成果可应用于提升LLM角色扮演的真实性和可靠性,例如在游戏、虚拟助手、教育等领域。通过提高LLM对角色知识的理解和辨别能力,可以构建更加智能和逼真的角色扮演代理。此外,RoleKE-Bench基准可以促进LLM角色扮演领域的研究,推动相关技术的进步。未来,该研究可以扩展到更复杂的角色扮演场景,并探索更多有效的错误检测方法。
📄 摘要(原文)
Large language model (LLM) role-playing has gained widespread attention. Authentic character knowledge is crucial for constructing realistic LLM role-playing agents. However, existing works usually overlook the exploration of LLMs' ability to detect characters' known knowledge errors (KKE) and unknown knowledge errors (UKE) while playing roles, which would lead to low-quality automatic construction of character trainable corpus. In this paper, we propose RoleKE-Bench to evaluate LLMs' ability to detect errors in KKE and UKE. The results indicate that even the latest LLMs struggle to detect these two types of errors effectively, especially when it comes to familiar knowledge. We experimented with various reasoning strategies and propose an agent-based reasoning method, Self-Recollection and Self-Doubt (S$^2$RD), to explore further the potential for improving error detection capabilities. Experiments show that our method effectively improves the LLMs' ability to detect error character knowledge, but it remains an issue that requires ongoing attention.