Surveying the MLLM Landscape: A Meta-Review of Current Surveys
作者: Ming Li, Keyu Chen, Ziqian Bi, Ming Liu, Xinyuan Song, Zekun Jiang, Tianyang Wang, Benji Peng, Qian Niu, Junyu Liu, Jinlang Wang, Sen Zhang, Xuanhe Pan, Jiawei Xu, Pohsun Feng
分类: cs.CL
发布日期: 2024-09-17 (更新: 2025-12-08)
备注: The article consists of 22 pages, including 2 figures and 108 references. The paper provides a meta-review of surveys on Multimodal Large Language Models (MLLMs), categorizing findings into key areas such as evaluation, applications, security, and future directions
💡 一句话要点
MLLM综述的元综述:系统性回顾多模态大语言模型评测方法与未来方向
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 MLLM 综述 元分析 评估方法 基准测试 未来趋势
📋 核心要点
- 现有MLLM评测方法缺乏系统性梳理,难以全面评估模型性能并指导未来研究方向。
- 本文对现有MLLM综述进行元分析,系统性地回顾了MLLM的评估方法、应用、伦理问题等。
- 通过比较分析现有综述,总结了MLLM评测的主要贡献和方法,并指出了未来研究的潜在方向。
📝 摘要(中文)
多模态大语言模型(MLLM)的兴起已成为人工智能领域的一股变革力量,使机器能够处理和生成跨多种模态(如文本、图像、音频和视频)的内容。这些模型代表了传统单模态系统的重大进步,为从自主代理到医疗诊断等各种应用开辟了新的前沿。通过整合多种模态,MLLM实现了对信息的更全面的理解,更接近于人类的感知。随着MLLM能力的扩展,对全面和准确的性能评估的需求变得越来越重要。本综述旨在对MLLM的基准测试和评估方法进行系统回顾,涵盖关键主题,如基本概念、应用、评估方法、伦理问题、安全性、效率和特定领域的应用。通过对现有文献的分类和分析,我们总结了各种综述的主要贡献和方法,进行了详细的比较分析,并考察了它们在学术界的影响。此外,我们还确定了MLLM研究中新兴的趋势和未充分探索的领域,为未来的研究提出了潜在的方向。本综述旨在为研究人员和从业人员提供对MLLM评估现状的全面理解,从而促进这个快速发展领域的进一步发展。
🔬 方法详解
问题定义:现有的多模态大语言模型(MLLM)发展迅速,但缺乏系统性的评估方法综述。这导致研究人员难以全面了解现有评估方法的优缺点,也难以确定未来研究的重点方向。现有综述可能存在覆盖范围不全、分析不够深入等问题,无法为研究人员提供充分的指导。
核心思路:本文的核心思路是对现有的MLLM综述进行“元综述”,即对已有的综述文章进行分析和比较。通过这种方式,可以更全面地了解MLLM评估领域的现状,并识别出重要的研究趋势和未解决的问题。这种方法能够整合不同综述的观点,避免单一综述可能存在的偏差。
技术框架:本文的整体框架包括以下几个主要阶段:1) 文献收集:收集关于MLLM评估方法的综述文章。2) 分类与分析:对收集到的综述文章进行分类,并分析其主要贡献、方法和结论。3) 比较分析:对不同综述文章进行比较,找出它们之间的异同点。4) 趋势识别:识别MLLM评估领域的新兴趋势和未充分探索的领域。5) 未来方向:提出未来研究的潜在方向。
关键创新:本文的关键创新在于采用了“元综述”的方法,对现有的MLLM综述进行系统性的分析和比较。这种方法能够更全面地了解MLLM评估领域的现状,并识别出重要的研究趋势和未解决的问题。与传统的综述文章相比,元综述能够提供更深入的分析和更全面的视角。
关键设计:本文的关键设计在于对综述文章的分类和分析框架。具体来说,本文关注以下几个方面:1) 评估方法:综述文章中提到的各种MLLM评估方法。2) 应用领域:MLLM在不同领域的应用情况。3) 伦理问题:与MLLM相关的伦理问题。4) 安全性:MLLM的安全性问题。5) 效率:MLLM的效率问题。通过对这些方面的分析,可以更全面地了解MLLM评估领域的现状。
🖼️ 关键图片
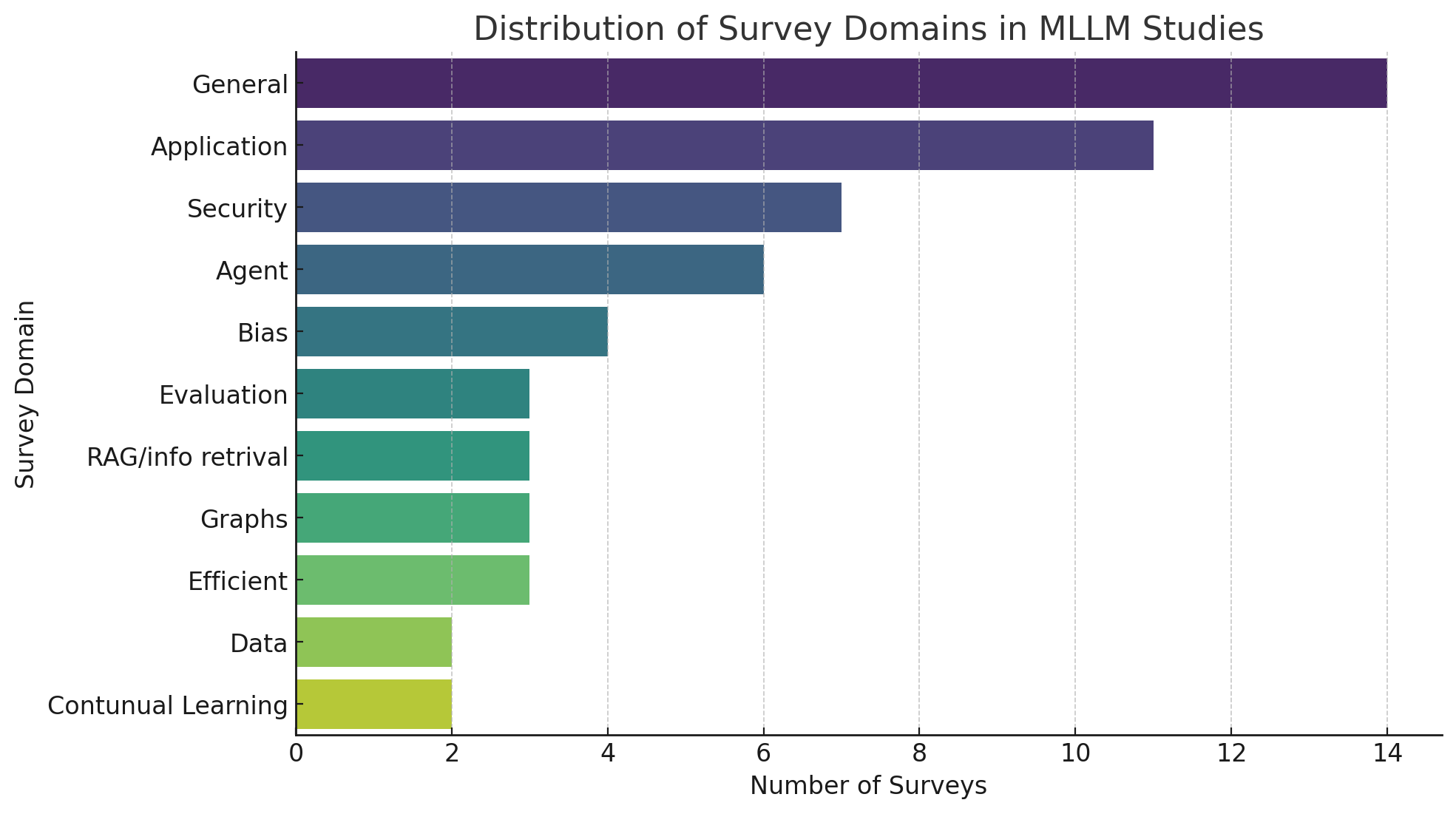

📊 实验亮点
本文通过对现有MLLM综述的元分析,总结了各种综述的主要贡献和方法,进行了详细的比较分析,并考察了它们在学术界的影响。此外,还识别了MLLM研究中新兴的趋势和未充分探索的领域,为未来的研究提出了潜在的方向。
🎯 应用场景
该研究成果可应用于指导MLLM的研究与开发,帮助研究人员选择合适的评估方法,并关注重要的伦理和安全问题。此外,该研究还可以促进MLLM在各个领域的应用,例如自主代理、医疗诊断等,最终提升人工智能系统的性能和可靠性。
📄 摘要(原文)
The rise of Multimodal Large Language Models (MLLMs) has become a transformative force in the field of artificial intelligence, enabling machines to process and generate content across multiple modalities, such as text, images, audio, and video. These models represent a significant advancement over traditional unimodal systems, opening new frontiers in diverse applications ranging from autonomous agents to medical diagnostics. By integrating multiple modalities, MLLMs achieve a more holistic understanding of information, closely mimicking human perception. As the capabilities of MLLMs expand, the need for comprehensive and accurate performance evaluation has become increasingly critical. This survey aims to provide a systematic review of benchmark tests and evaluation methods for MLLMs, covering key topics such as foundational concepts, applications, evaluation methodologies, ethical concerns, security, efficiency, and domain-specific applications. Through the classification and analysis of existing literature, we summarize the main contributions and methodologies of various surveys, conduct a detailed comparative analysis, and examine their impact within the academic community. Additionally, we identify emerging trends and underexplored areas in MLLM research, proposing potential directions for future studies. This survey is intended to offer researchers and practitioners a comprehensive understanding of the current state of MLLM evaluation, thereby facilitating further progress in this rapidly evolving field.