SC-Phi2: A Fine-tuned Small Language Model for StarCraft II Macromanagement Tasks
作者: Muhammad Junaid Khan, Gita Sukthankar
分类: cs.CL, cs.AI
发布日期: 2024-09-17
💡 一句话要点
SC-Phi2:微调的小型语言模型用于星际争霸II的宏观管理任务
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 星际争霸II 小型语言模型 宏观管理 微调 视觉信息 LoRA 量化
📋 核心要点
- 现有星际争霸AI通常依赖大型语言模型,计算成本高昂,难以部署在资源受限的环境中。
- SC-Phi2通过微调小型语言模型Phi2,并结合视觉信息,降低了计算需求,同时保持了良好的性能。
- 实验表明,SC-Phi2在构建顺序和全局状态预测等任务上表现出色,证明了小型语言模型在星际争霸AI中的潜力。
📝 摘要(中文)
本文介绍了SC-Phi2,一个为星际争霸II宏观管理任务微调的小型语言模型。小型语言模型,如Phi2、Gemma和DistilBERT,是大型语言模型(LLM)的精简版本,参数更少,运行所需的功耗和内存也更少。为了让微软的Phi2模型学习星际争霸,我们创建了一个新的SC2文本数据集,其中包含关于星际争霸种族、角色和动作的信息,并使用自监督学习对Phi-2进行微调。我们将这个语言模型与预训练的BLIP-2(Bootstrapping Language Image Pre-training)模型的Vision Transformer(ViT)配对,并在MSC重放数据集上对其进行微调。这使我们能够构建包含视觉游戏状态信息的动态提示。与星际争霸LLM中使用的大型模型(如GPT-3.5)不同,Phi2主要在教科书数据上进行训练,除了我们的训练过程提供的信息外,几乎不包含星际争霸II的固有知识。通过使用LoRA(Low-rank Adaptation)和量化,我们的模型可以在单个GPU上进行训练。我们证明了我们的模型在构建顺序和全局状态预测等微观管理任务中表现良好,且参数数量较少。
🔬 方法详解
问题定义:论文旨在解决星际争霸II宏观管理任务中,现有方法依赖大型语言模型导致计算成本过高的问题。现有方法难以在资源受限的环境中部署,限制了其应用范围。
核心思路:论文的核心思路是利用小型语言模型Phi2,通过微调使其具备星际争霸II的知识,并结合视觉信息,从而在降低计算成本的同时,保持良好的性能。这种方法旨在实现一个轻量级、高效的星际争霸II AI模型。
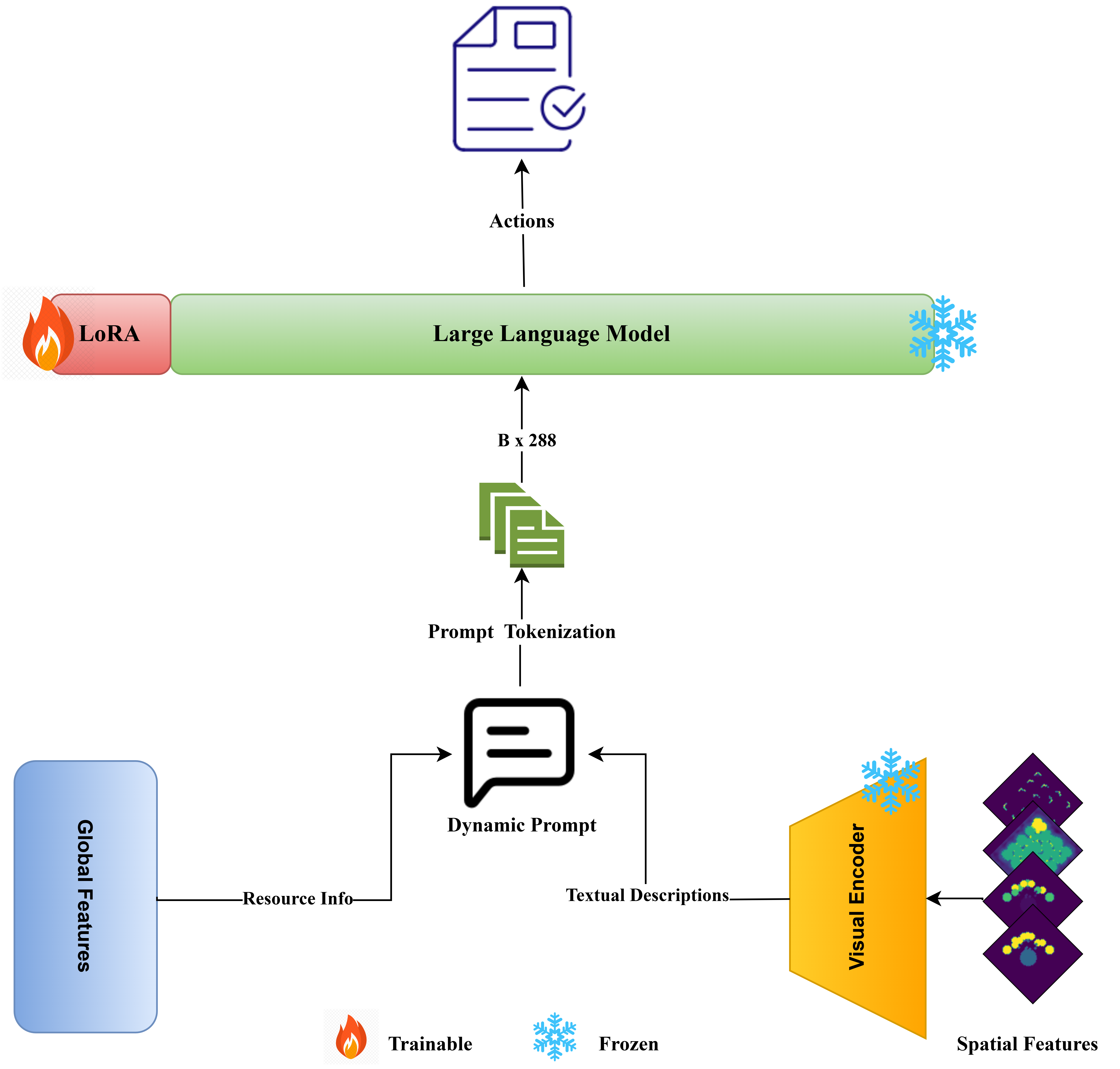
技术框架:整体框架包含两个主要模块:1) 基于Phi2微调的语言模型,用于处理文本信息;2) 基于BLIP-2的Vision Transformer (ViT),用于处理视觉信息。这两个模块通过动态提示的方式进行结合,将视觉游戏状态信息融入到语言模型的输入中。整个流程包括数据收集、模型微调、模型评估等步骤。
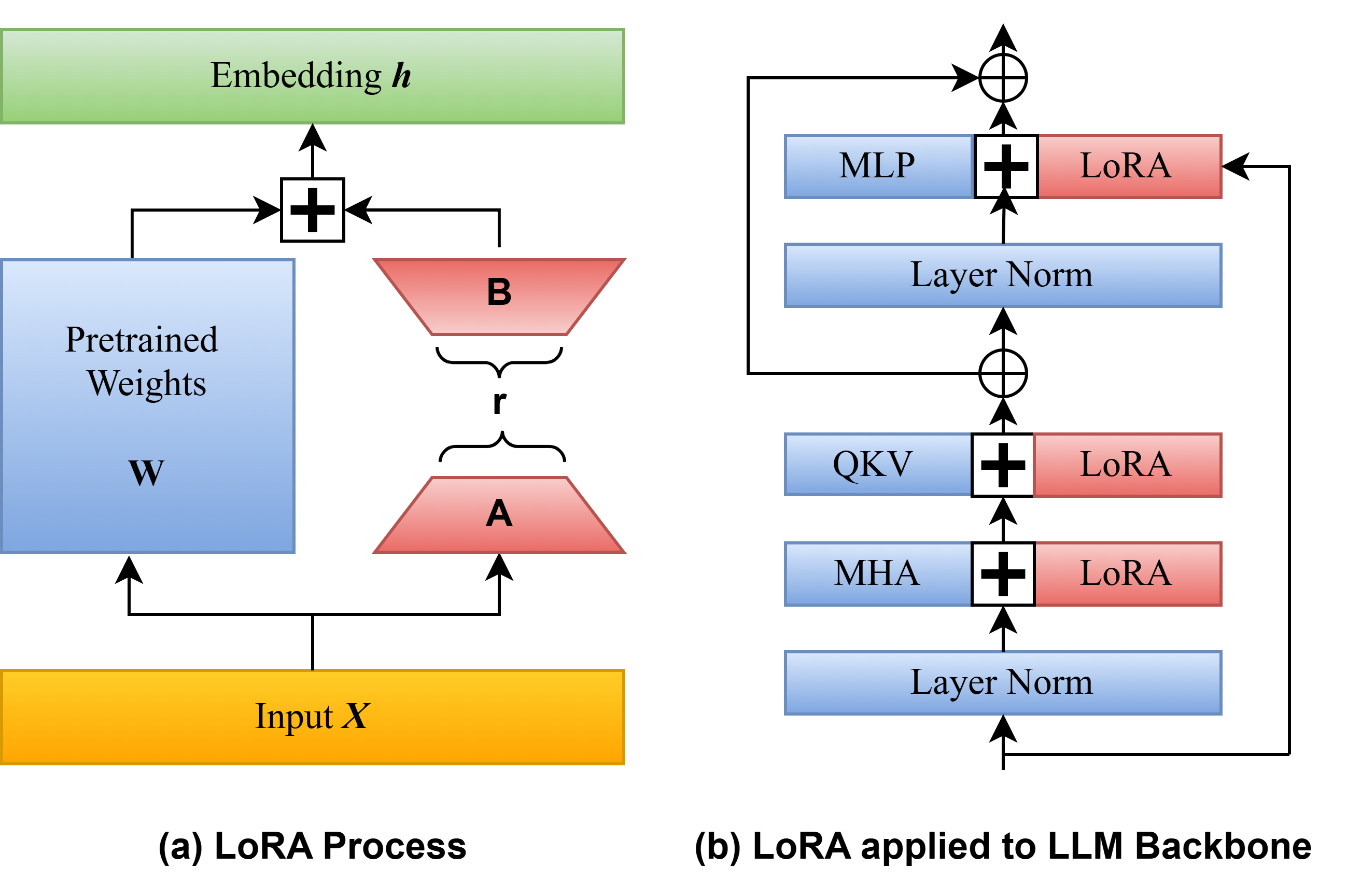
关键创新:最重要的创新点在于将小型语言模型Phi2应用于星际争霸II的宏观管理任务,并结合视觉信息。与以往依赖大型语言模型的方法不同,SC-Phi2在保证性能的同时,显著降低了计算成本。此外,使用LoRA和量化技术进一步降低了训练成本,使得模型可以在单个GPU上进行训练。
关键设计:论文使用了自监督学习对Phi2进行微调,创建了一个新的SC2文本数据集,其中包含关于星际争霸种族、角色和动作的信息。ViT在MSC重放数据集上进行微调。LoRA用于降低训练参数量,量化技术用于降低模型大小。动态提示的设计是关键,它将视觉信息有效地融入到语言模型的输入中。具体的参数设置和损失函数等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
SC-Phi2在构建顺序和全局状态预测等微观管理任务中表现良好,证明了小型语言模型在星际争霸AI中的潜力。通过使用LoRA和量化,模型可以在单个GPU上进行训练,显著降低了计算成本。虽然论文中没有给出具体的性能数据和对比基线,但其在资源受限环境下的可行性是其主要亮点。
🎯 应用场景
SC-Phi2具有广泛的应用前景,可用于开发低成本、易于部署的星际争霸II AI助手,辅助玩家进行宏观管理决策。此外,该研究思路可以推广到其他资源受限环境下的游戏AI开发,例如移动平台上的游戏。未来,可以进一步探索如何利用小型语言模型和视觉信息,构建更智能、更高效的游戏AI。
📄 摘要(原文)
This paper introduces SC-Phi2, a fine-tuned StarCraft II small language model for macromanagement tasks. Small language models, like Phi2, Gemma, and DistilBERT, are streamlined versions of large language models (LLMs) with fewer parameters that require less power and memory to run. To teach Microsoft's Phi2 model about StarCraft, we create a new SC2 text dataset with information about StarCraft races, roles, and actions and use it to fine-tune Phi-2 with self-supervised learning. We pair this language model with a Vision Transformer (ViT) from the pre-trained BLIP-2 (Bootstrapping Language Image Pre-training) model, fine-tuning it on the MSC replay dataset. This enables us to construct dynamic prompts that include visual game state information. Unlike the large models used in StarCraft LLMs such as GPT-3.5, Phi2 is trained primarily on textbook data and contains little inherent knowledge of StarCraft II beyond what is provided by our training process. By using LoRA (Low-rank Adaptation) and quantization, our model can be trained on a single GPU. We demonstrate that our model performs well at micromanagement tasks such as build order and global state prediction with a small number of parameters.