THaMES: An End-to-End Tool for Hallucination Mitigation and Evaluation in Large Language Models
作者: Mengfei Liang, Archish Arun, Zekun Wu, Cristian Munoz, Jonathan Lutch, Emre Kazim, Adriano Koshiyama, Philip Treleaven
分类: cs.CL
发布日期: 2024-09-17 (更新: 2024-11-30)
备注: NeurIPS 2024 SoLaR (Socially Responsible Language Modelling Research ) Workshop
期刊: NeurIPS Workshop on Socially Responsible Language Modelling Research 2024
💡 一句话要点
THaMES:用于大规模语言模型幻觉缓解与评估的端到端工具
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大规模语言模型 幻觉缓解 幻觉评估 自动化测试集生成 检索增强生成 上下文学习 参数高效微调
📋 核心要点
- 现有LLM幻觉检测与缓解方法孤立且缺乏标准化流程,难以满足特定领域的需求。
- THaMES框架提供端到端解决方案,自动化测试集生成,并集成多种幻觉缓解策略。
- 实验表明,不同模型对缓解策略的偏好不同,PEFT能显著提升特定模型的性能。
📝 摘要(中文)
本文介绍了一种名为THaMES(幻觉缓解与评估工具)的集成框架和库,旨在解决大规模语言模型(LLM)中日益严重的幻觉问题,即生成不准确的事实性内容。现有检测和缓解方法通常是孤立的,无法满足特定领域的需求,并且缺乏标准化的流程。THaMES提供了一个端到端的解决方案,用于评估和缓解LLM中的幻觉,包括自动测试集生成、多方面的基准测试和可适应的缓解策略。它能够自动从任何语料库创建测试集,通过批量处理、加权抽样和反事实验证等技术确保高质量、多样性和成本效益。THaMES评估模型在各种任务中检测和减少幻觉的能力,包括文本生成和二元分类,并应用最佳的缓解策略,如上下文学习(ICL)、检索增强生成(RAG)和参数高效微调(PEFT)。使用学术论文、政治新闻和维基百科知识库对最先进的LLM进行评估表明,像GPT-4o这样的商业模型从RAG中受益更多,而像Llama-3.1-8B-Instruct和Mistral-Nemo这样的开源模型从ICL中受益更多。此外,PEFT显著提高了Llama-3.1-8B-Instruct在评估任务中的性能。
🔬 方法详解
问题定义:论文旨在解决大规模语言模型中普遍存在的幻觉问题,即生成与事实不符的内容。现有方法通常是孤立的,缺乏统一的评估和缓解流程,难以适应不同领域的需求。此外,构建高质量、多样化的测试集成本高昂,阻碍了幻觉问题的有效研究。
核心思路:THaMES的核心思路是构建一个端到端的框架,自动化幻觉评估和缓解流程。通过自动生成高质量测试集,并集成多种缓解策略(ICL、RAG、PEFT),THaMES能够系统地评估和提升LLM的可靠性。这种集成化的设计使得用户能够方便地针对特定领域定制幻觉缓解方案。
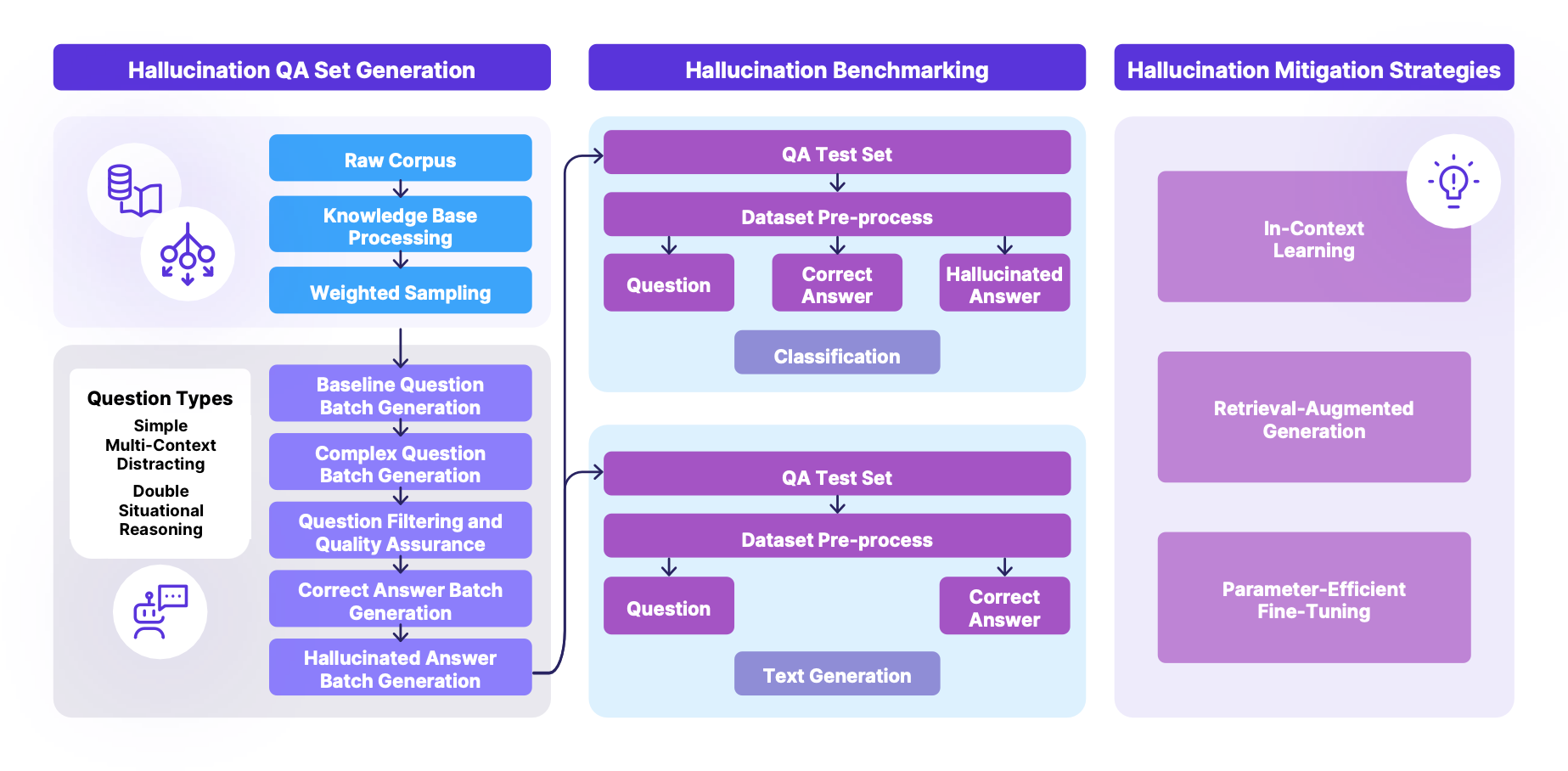
技术框架:THaMES框架包含以下主要模块:1) 自动化测试集生成模块,从任意语料库生成高质量、多样化的测试集;2) 多方面基准测试模块,评估模型在不同任务中检测和减少幻觉的能力;3) 可适应的缓解策略模块,集成ICL、RAG和PEFT等多种缓解策略,并根据模型特点选择最佳策略。整体流程是从语料库生成测试集,然后使用测试集评估模型,最后应用缓解策略提升模型性能。
关键创新:THaMES的关键创新在于其端到端的集成化设计,以及自动化测试集生成能力。与现有方法相比,THaMES提供了一个完整的幻觉评估和缓解流程,无需人工干预。自动化测试集生成模块通过批量处理、加权抽样和反事实验证等技术,显著降低了测试集构建的成本,并保证了数据质量和多样性。
关键设计:自动化测试集生成模块采用了加权抽样策略,根据不同类型样本的重要性进行抽样,以保证测试集的多样性。反事实验证技术用于检测和过滤掉不准确的样本,确保测试集的质量。缓解策略模块根据模型特点选择最佳策略,例如,对于知识密集型任务,RAG可能更有效,而对于需要推理的任务,ICL可能更有效。PEFT的具体实现细节(如adapter的结构和训练参数)需要根据具体模型和任务进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,商业模型如GPT-4o更适合RAG缓解策略,而开源模型如Llama-3.1-8B-Instruct和Mistral-Nemo更适合ICL。此外,PEFT显著提升了Llama-3.1-8B-Instruct在评估任务中的性能。这些结果为选择合适的幻觉缓解策略提供了重要的参考。
🎯 应用场景
THaMES可应用于各种需要可靠信息生成的领域,如智能客服、新闻摘要、科研助手等。通过降低LLM的幻觉率,THaMES能够提升这些应用的可信度和实用性。未来,THaMES可以扩展到更多模态,例如图像和视频,以解决多模态LLM中的幻觉问题。
📄 摘要(原文)
Hallucination, the generation of factually incorrect content, is a growing challenge in Large Language Models (LLMs). Existing detection and mitigation methods are often isolated and insufficient for domain-specific needs, lacking a standardized pipeline. This paper introduces THaMES (Tool for Hallucination Mitigations and EvaluationS), an integrated framework and library addressing this gap. THaMES offers an end-to-end solution for evaluating and mitigating hallucinations in LLMs, featuring automated test set generation, multifaceted benchmarking, and adaptable mitigation strategies. It automates test set creation from any corpus, ensuring high data quality, diversity, and cost-efficiency through techniques like batch processing, weighted sampling, and counterfactual validation. THaMES assesses a model's ability to detect and reduce hallucinations across various tasks, including text generation and binary classification, applying optimal mitigation strategies like In-Context Learning (ICL), Retrieval Augmented Generation (RAG), and Parameter-Efficient Fine-tuning (PEFT). Evaluations of state-of-the-art LLMs using a knowledge base of academic papers, political news, and Wikipedia reveal that commercial models like GPT-4o benefit more from RAG than ICL, while open-weight models like Llama-3.1-8B-Instruct and Mistral-Nemo gain more from ICL. Additionally, PEFT significantly enhances the performance of Llama-3.1-8B-Instruct in both evaluation tasks.