Task Arithmetic for Language Expansion in Speech Translation
作者: Yao-Fei Cheng, Hayato Futami, Yosuke Kashiwagi, Emiru Tsunoo, Wen Shen Teo, Siddhant Arora, Shinji Watanabe
分类: cs.CL, cs.AI
发布日期: 2024-09-17 (更新: 2025-07-29)
💡 一句话要点
提出增强型任务算术方法,用于语音翻译中的语言扩展,无需重新训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音翻译 任务算术 语言扩展 多语言模型 模型融合
📋 核心要点
- 现有语音翻译模型扩展新语言对时,需要大量数据和重新训练,成本高昂。
- 论文提出增强型任务算术方法,通过结合语言控制模型,实现无需重新训练的语言扩展。
- 实验结果表明,该方法在BLEU和COMET指标上均有显著提升,验证了其有效性。
📝 摘要(中文)
大型语言模型(LLMs)的最新进展激发了人们对语音-文本多模态基础模型的兴趣,并在指令调优的语音翻译(ST)方面取得了显著的性能。然而,由于需要在组合的新旧数据集上重新训练,扩展语言对的成本很高。为了解决这个问题,我们的目标是利用现有的单对一ST系统,通过任务算术构建一个一对多ST系统,而无需重新训练。直接在ST中应用任务算术会导致语言混淆;因此,我们引入了一种增强型任务算术方法,该方法结合了语言控制模型,以确保生成正确的目标语言。我们在MuST-C和CoVoST-2上的实验表明,BLEU得分提高了4.66和4.92,COMET得分提高了8.87和11.83。此外,我们证明了我们的框架可以通过基于现有的机器翻译(MT)和ST模型,通过任务类比合成ST模型,从而扩展到缺乏配对ST训练数据或预训练ST模型的语言对。
🔬 方法详解
问题定义:论文旨在解决语音翻译(ST)模型扩展语言对时需要大量重新训练的问题。现有的ST模型通常是单对一的,即只能处理一种源语言到一种目标语言的翻译。当需要支持新的语言对时,必须收集新的训练数据,并重新训练整个模型,这耗时且耗资源。直接应用任务算术进行模型融合会导致语言混淆,影响翻译质量。
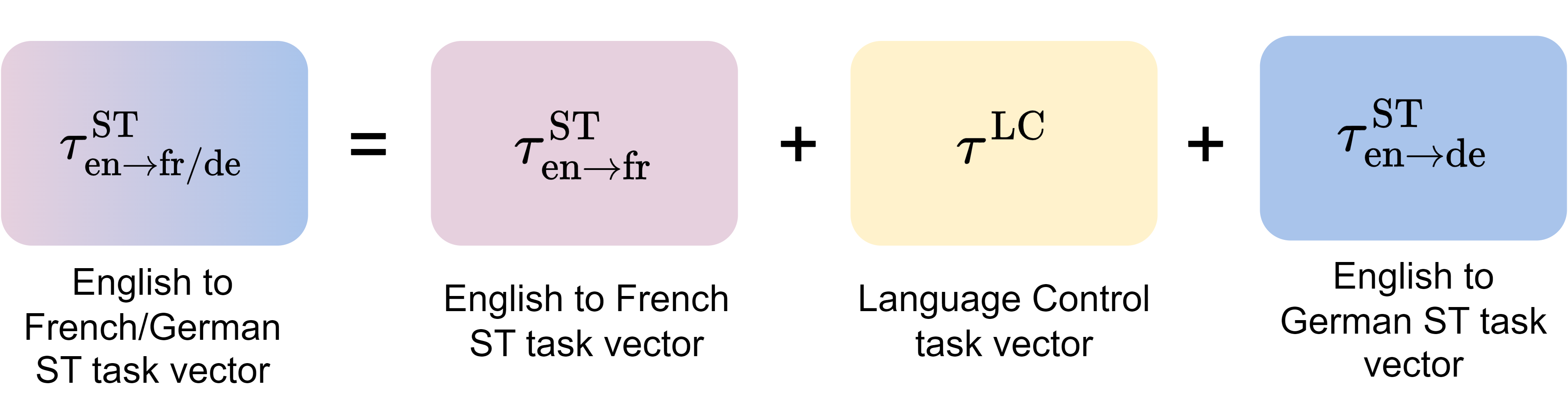
核心思路:论文的核心思路是利用任务算术,通过组合现有单对一ST模型的参数,构建一个一对多ST模型,从而避免重新训练。为了解决直接应用任务算术导致的语言混淆问题,引入了语言控制模型,用于指导目标语言的生成,确保翻译的准确性。
技术框架:整体框架包括以下几个主要模块:1) 多个单对一ST模型,每个模型负责一种源语言到一种目标语言的翻译;2) 任务算术模块,用于将多个单对一ST模型的参数进行线性组合,得到一个融合后的模型;3) 语言控制模型,用于根据目标语言的指示,调整融合模型的输出,确保生成正确的语言;4) 训练和评估模块,用于训练语言控制模型,并评估整个系统的性能。
关键创新:论文的关键创新在于提出了增强型任务算术方法,该方法在任务算术的基础上,引入了语言控制模型,从而解决了直接应用任务算术导致的语言混淆问题。此外,论文还提出了利用任务类比,基于现有的机器翻译(MT)和ST模型,合成ST模型的方法,从而扩展到缺乏配对ST训练数据或预训练ST模型的语言对。
关键设计:语言控制模型的设计是关键。具体实现细节未知,但推测可能采用某种形式的条件生成模型,例如条件变分自编码器(CVAE)或条件生成对抗网络(CGAN),以目标语言作为条件,指导翻译结果的生成。任务算术的具体实现方式可能是简单的参数加权平均,权重可能根据各个单对一ST模型的性能进行调整。损失函数的设计可能包括翻译损失(例如交叉熵损失)和语言控制损失(用于约束语言控制模型的输出)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在MuST-C和CoVoST-2数据集上取得了显著的性能提升。在MuST-C上,BLEU得分提高了4.66,COMET得分提高了8.87。在CoVoST-2上,BLEU得分提高了4.92,COMET得分提高了11.83。这些结果表明,该方法能够有效地扩展语音翻译系统支持的语言对,并提高翻译质量。
🎯 应用场景
该研究成果可应用于多语言语音翻译系统,例如国际会议同声传译、跨国商务交流、在线教育等场景。通过该方法,可以快速扩展语音翻译系统支持的语言对,降低开发成本,提高翻译效率,促进不同语言人群之间的交流与合作。未来,该技术有望应用于智能客服、语音助手等领域,实现更加自然和便捷的跨语言交互。
📄 摘要(原文)
Recent progress in large language models (LLMs) has gained interest in speech-text multimodal foundation models, achieving strong performance on instruction-tuned speech translation (ST). However, expanding language pairs is costly due to re-training on combined new and previous datasets. To address this, we aim to build a one-to-many ST system from existing one-to-one ST systems using task arithmetic without re-training. Direct application of task arithmetic in ST leads to language confusion; therefore, we introduce an augmented task arithmetic method incorporating a language control model to ensure correct target language generation. Our experiments on MuST-C and CoVoST-2 show BLEU score improvements of up to 4.66 and 4.92, with COMET gains of 8.87 and 11.83. In addition, we demonstrate our framework can extend to language pairs lacking paired ST training data or pre-trained ST models by synthesizing ST models based on existing machine translation (MT) and ST models via task analogies.