KVPruner: Structural Pruning for Faster and Memory-Efficient Large Language Models
作者: Bo Lv, Quan Zhou, Xuanang Ding, Yan Wang, Zeming Ma
分类: cs.CL
发布日期: 2024-09-17
💡 一句话要点
KVPruner:通过结构化剪枝加速并降低大语言模型的内存占用
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型剪枝 KV缓存 推理加速 内存优化 结构化剪枝 LoRA微调 困惑度分析
📋 核心要点
- 大语言模型推理时KV缓存占用大量内存,深度剪枝恢复训练耗时,宽度剪枝提速不明显。
- KVPruner通过全局困惑度分析确定块重要性,剪除不重要的KV通道,提升模型效率。
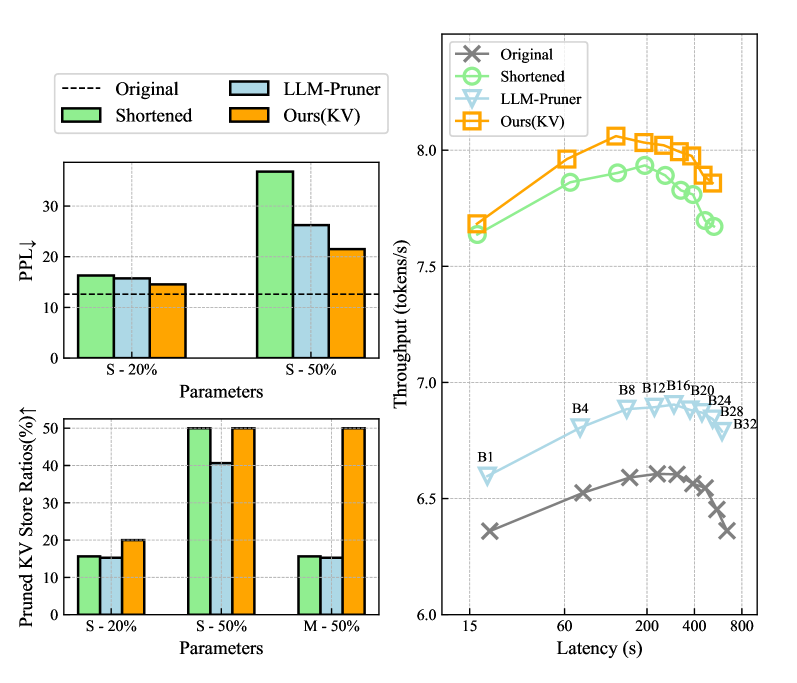
- 实验表明,KVPruner能减少50%内存占用,提升35%吞吐量,且仅需少量LoRA微调。
📝 摘要(中文)
大语言模型推理过程中,键值(KV)缓存带来的瓶颈是一个显著的挑战。深度剪枝虽然可以加速推理,但需要大量的恢复训练,这可能需要长达两周的时间。另一方面,宽度剪枝虽然保留了大部分性能,但速度提升有限。为了解决这些挑战,我们提出了KVPruner,旨在提高模型效率的同时保持性能。我们的方法使用基于全局困惑度的分析来确定每个块的重要性比率,并提供多种策略来剪除块内非必要的KV通道。与原始模型相比,KVPruner减少了50%的运行时内存使用,并将吞吐量提高了35%以上。此外,我们的方法只需要在小型数据集上进行两个小时的LoRA微调,即可恢复大部分性能。
🔬 方法详解
问题定义:大语言模型在推理阶段,KV缓存会消耗大量的内存资源,成为性能瓶颈。现有的深度剪枝方法虽然可以加速推理,但需要耗费大量时间进行恢复训练,成本很高。宽度剪枝方法虽然能保持较好的性能,但提速效果不明显,无法有效解决KV缓存带来的问题。
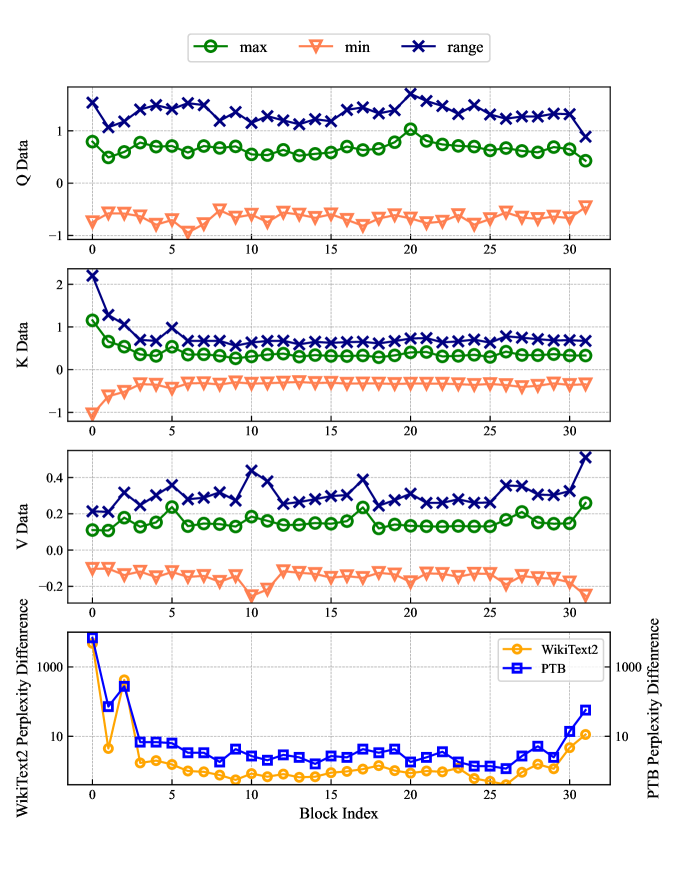
核心思路:KVPruner的核心思路是,并非所有的KV通道都同等重要,可以通过剪除不重要的KV通道来减少内存占用,同时提升推理速度。论文通过全局困惑度分析来评估每个Transformer块的重要性,并根据重要性比例来剪枝KV通道。
技术框架:KVPruner主要包含以下几个阶段:1) 重要性分析:使用全局困惑度作为指标,评估每个Transformer块的重要性。困惑度越低,说明该块对模型性能越重要。2) 剪枝策略:根据块的重要性,选择合适的剪枝策略。论文提出了多种剪枝策略,例如均匀剪枝、自适应剪枝等。3) LoRA微调:对剪枝后的模型进行LoRA微调,以恢复模型性能。
关键创新:KVPruner的关键创新在于:1) 提出了一种基于全局困惑度的块重要性评估方法,能够更准确地识别出不重要的KV通道。2) 提出了一种结构化的剪枝方法,能够有效地减少KV缓存的内存占用,同时保持模型性能。3) 结合LoRA微调,能够在短时间内恢复剪枝带来的性能损失。与现有方法相比,KVPruner能够在保证性能的前提下,显著降低内存占用和提升推理速度。
关键设计:论文的关键设计包括:1) 使用全局困惑度作为重要性指标,而非局部指标,能够更全面地评估块的重要性。2) 提出了多种剪枝策略,可以根据不同的模型和数据集选择合适的策略。3) 使用LoRA微调,能够在短时间内恢复模型性能,降低了训练成本。具体的参数设置和损失函数细节在论文中有详细描述,例如LoRA的秩(rank)的选择,微调的学习率等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,KVPruner能够在减少50%运行时内存使用的同时,将吞吐量提高35%以上。与原始模型相比,KVPruner在性能上几乎没有损失,并且只需要在小型数据集上进行两个小时的LoRA微调即可恢复大部分性能。这些结果表明,KVPruner是一种高效且实用的模型剪枝方法。
🎯 应用场景
KVPruner具有广泛的应用前景,尤其适用于资源受限的场景,如移动设备、边缘计算等。它可以帮助开发者在这些平台上部署更大规模的语言模型,提供更强大的AI服务。此外,KVPruner还可以应用于云端推理服务,降低推理成本,提高服务效率。未来,该技术有望推动大语言模型在更多领域的应用。
📄 摘要(原文)
The bottleneck associated with the key-value(KV) cache presents a significant challenge during the inference processes of large language models. While depth pruning accelerates inference, it requires extensive recovery training, which can take up to two weeks. On the other hand, width pruning retains much of the performance but offers slight speed gains. To tackle these challenges, we propose KVPruner to improve model efficiency while maintaining performance. Our method uses global perplexity-based analysis to determine the importance ratio for each block and provides multiple strategies to prune non-essential KV channels within blocks. Compared to the original model, KVPruner reduces runtime memory usage by 50% and boosts throughput by over 35%. Additionally, our method requires only two hours of LoRA fine-tuning on small datasets to recover most of the performance.