DynamicNER: A Dynamic, Multilingual, and Fine-Grained Dataset for LLM-based Named Entity Recognition
作者: Hanjun Luo, Yingbin Jin, Xinfeng Li, Xuecheng Liu, Ruizhe Chen, Tong Shang, Kun Wang, Qingsong Wen, Zuozhu Liu
分类: cs.CL, cs.AI
发布日期: 2024-09-17 (更新: 2025-09-19)
备注: This paper is accepted by EMNLP 2025 Main Conference
🔗 代码/项目: GITHUB
💡 一句话要点
提出DynamicNER数据集,用于评估LLM在动态、多语言和细粒度命名实体识别中的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 命名实体识别 大型语言模型 动态数据集 多语言 细粒度 基准测试 上下文理解
📋 核心要点
- 现有NER数据集主要面向传统机器学习方法,无法充分评估LLM在细粒度实体识别和上下文理解方面的能力。
- DynamicNER数据集通过动态分类,多语言支持和细粒度实体类型,为LLM提供更全面的评估基准。
- 论文提出CascadeNER方法,利用两阶段策略和轻量级LLM,在细粒度NER任务上实现了更高的准确率。
📝 摘要(中文)
大型语言模型(LLM)的进步激发了人们对其在命名实体识别(NER)方法中应用的兴趣。然而,现有的数据集主要为传统机器学习方法设计,在语料库选择和整体数据集设计逻辑方面不足以支持基于LLM的方法。此外,现有数据集中普遍存在的固定且相对粗粒度的实体分类,未能充分评估基于LLM的方法的卓越泛化和上下文理解能力,从而阻碍了对其广泛应用前景的全面展示。为了解决这些限制,我们提出了DynamicNER,这是第一个专为基于LLM的方法设计的NER数据集,具有动态分类,在不同上下文中为同一实体引入各种实体类型和实体类型列表,从而更好地利用基于LLM的NER的泛化能力。该数据集也是多语言和多粒度的,涵盖8种语言和155种实体类型,语料库跨越各种领域。此外,我们还引入了CascadeNER,一种基于两阶段策略和轻量级LLM的新型NER方法,在细粒度任务上实现了更高的准确率,同时需要更少的计算资源。实验表明,DynamicNER可以作为基于LLM的NER方法的强大而有效的基准。此外,我们还对传统方法和基于LLM的方法在我们的数据集上进行了分析。我们的代码和数据集可在https://github.com/Astarojth/DynamicNER上公开获取。
🔬 方法详解
问题定义:现有NER数据集的实体类型定义较为固定和粗糙,无法充分利用LLM的泛化能力和上下文理解能力。此外,数据集的语言覆盖范围和领域多样性也存在局限性,难以全面评估LLM在不同场景下的NER性能。
核心思路:DynamicNER的核心思路是构建一个动态、多语言和细粒度的数据集,以更好地评估和利用LLM在NER任务中的能力。通过引入动态分类,允许同一实体在不同上下文中具有不同的类型定义,从而模拟真实世界的复杂性。
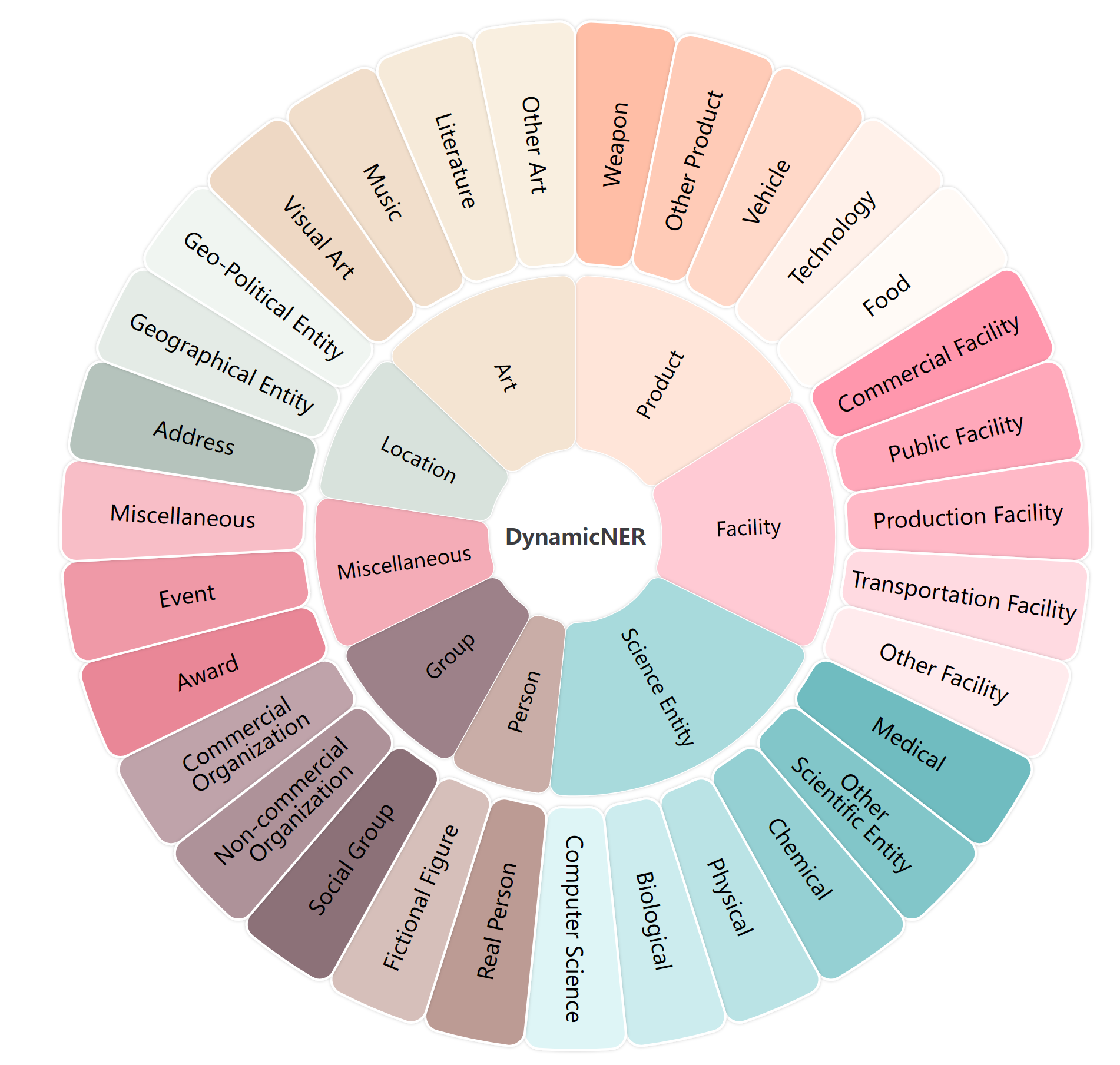
技术框架:DynamicNER数据集包含以下几个关键组成部分:1)多语言语料库,覆盖8种语言;2)细粒度实体类型体系,包含155种实体类型;3)动态实体类型标注,允许同一实体在不同上下文中具有不同的类型定义。CascadeNER方法采用两阶段策略:第一阶段使用轻量级LLM进行粗粒度实体识别,第二阶段使用另一个轻量级LLM进行细粒度实体类型分类。
关键创新:DynamicNER数据集的关键创新在于其动态实体类型标注方法,允许同一实体在不同上下文中具有不同的类型定义。这使得数据集能够更好地模拟真实世界的复杂性,并更全面地评估LLM的上下文理解能力。CascadeNER方法的关键创新在于其两阶段策略,通过将粗粒度实体识别和细粒度实体类型分类解耦,可以有效地提高细粒度NER的准确率。
关键设计:DynamicNER数据集的实体类型体系基于现有的知识库和NER数据集,并进行了扩展和细化。CascadeNER方法使用预训练的轻量级LLM作为基础模型,并采用交叉熵损失函数进行训练。具体的参数设置和网络结构细节在论文中进行了详细描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,DynamicNER数据集可以作为基于LLM的NER方法的强大而有效的基准。CascadeNER方法在细粒度NER任务上实现了更高的准确率,同时需要更少的计算资源。具体性能数据和对比基线在论文中进行了详细展示。
🎯 应用场景
DynamicNER数据集和CascadeNER方法可广泛应用于信息抽取、知识图谱构建、智能问答等领域。该研究有助于提升LLM在复杂场景下的NER性能,从而提高相关应用的准确性和可靠性。未来,可以进一步扩展DynamicNER数据集的语言覆盖范围和领域多样性,并探索更有效的细粒度NER方法。
📄 摘要(原文)
The advancements of Large Language Models (LLMs) have spurred a growing interest in their application to Named Entity Recognition (NER) methods. However, existing datasets are primarily designed for traditional machine learning methods and are inadequate for LLM-based methods, in terms of corpus selection and overall dataset design logic. Moreover, the prevalent fixed and relatively coarse-grained entity categorization in existing datasets fails to adequately assess the superior generalization and contextual understanding capabilities of LLM-based methods, thereby hindering a comprehensive demonstration of their broad application prospects. To address these limitations, we propose DynamicNER, the first NER dataset designed for LLM-based methods with dynamic categorization, introducing various entity types and entity type lists for the same entity in different context, leveraging the generalization of LLM-based NER better. The dataset is also multilingual and multi-granular, covering 8 languages and 155 entity types, with corpora spanning a diverse range of domains. Furthermore, we introduce CascadeNER, a novel NER method based on a two-stage strategy and lightweight LLMs, achieving higher accuracy on fine-grained tasks while requiring fewer computational resources. Experiments show that DynamicNER serves as a robust and effective benchmark for LLM-based NER methods. Furthermore, we also conduct analysis for traditional methods and LLM-based methods on our dataset. Our code and dataset are openly available at https://github.com/Astarojth/DynamicNER.