Attention-Seeker: Dynamic Self-Attention Scoring for Unsupervised Keyphrase Extraction
作者: Erwin D. López Z., Cheng Tang, Atsushi Shimada
分类: cs.CL, cs.IR
发布日期: 2024-09-17 (更新: 2024-12-16)
备注: This version has been accepted for presentation at COLING 2025, and all peer-reviewed changes have been incorporated
💡 一句话要点
提出Attention-Seeker以解决无监督关键短语提取问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 关键短语提取 自注意力机制 无监督学习 自然语言处理 信息检索
📋 核心要点
- 现有的关键短语提取方法通常需要手动调整参数,限制了其适用性和灵活性。
- Attention-Seeker通过动态利用自注意力图,自动评估候选短语的重要性,避免了手动调优的需求。
- 实验结果显示,Attention-Seeker在四个数据集上表现优于大多数基线模型,特别是在长文档的提取任务中取得了显著提升。
📝 摘要(中文)
本文提出了Attention-Seeker,一种无监督的关键短语提取方法,利用大型语言模型的自注意力图来评估候选短语的重要性。该方法识别模型在文本关键主题上显著关注的特定组件,如层、头和注意力向量,并利用这些组件提供的注意力权重对候选短语进行评分。与以往需要手动调整参数的模型不同,Attention-Seeker能够动态适应输入文本,增强了其实用性。我们在四个公开数据集上评估了Attention-Seeker的性能,结果表明,即使没有参数调优,Attention-Seeker在大多数基线模型中表现优异,在四个数据集中有三个达到了最先进的性能,尤其在长文档的关键短语提取方面表现突出。
🔬 方法详解
问题定义:本文旨在解决无监督关键短语提取中的参数调优问题,现有方法往往依赖于手动选择参数,导致灵活性不足。
核心思路:Attention-Seeker的核心思路是利用大型语言模型的自注意力机制,动态评估候选短语的重要性,从而实现无须手动调整的关键短语提取。
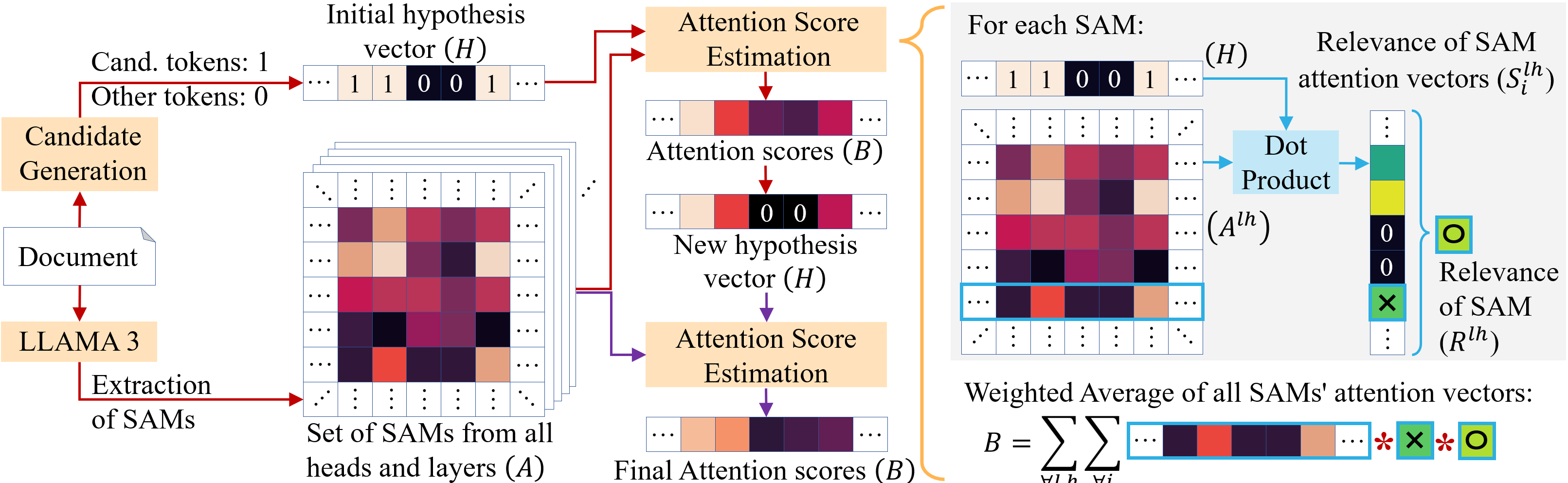
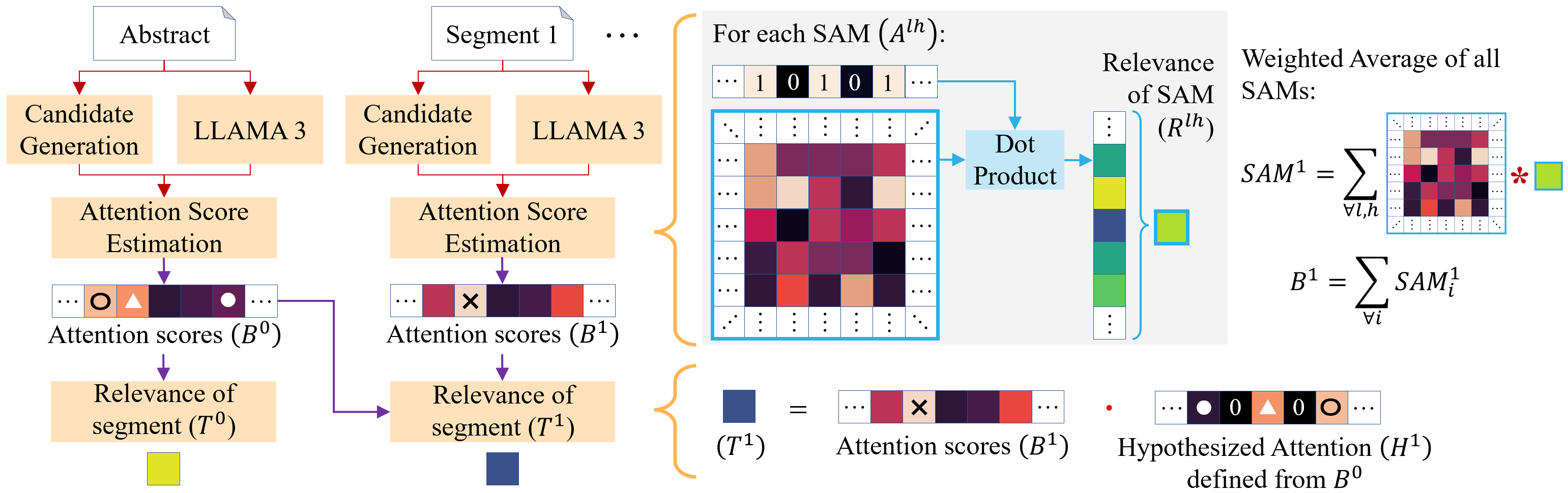
技术框架:该方法的整体架构包括自注意力图的提取、重要性评分计算和候选短语的排序三个主要模块。首先,从语言模型中提取自注意力图,然后基于注意力权重对候选短语进行评分,最后根据评分结果进行排序。
关键创新:Attention-Seeker的创新点在于其动态适应性,能够根据输入文本自动选择关注的层、头和注意力向量,显著提升了提取效果。与传统方法相比,它不再依赖于手动参数调优。
关键设计:在设计上,Attention-Seeker关注自注意力图的特定组件,利用这些组件的注意力权重进行评分,避免了复杂的超参数调整,简化了模型的使用过程。具体的参数设置和损失函数设计在实验中经过验证,以确保模型的有效性。
🖼️ 关键图片
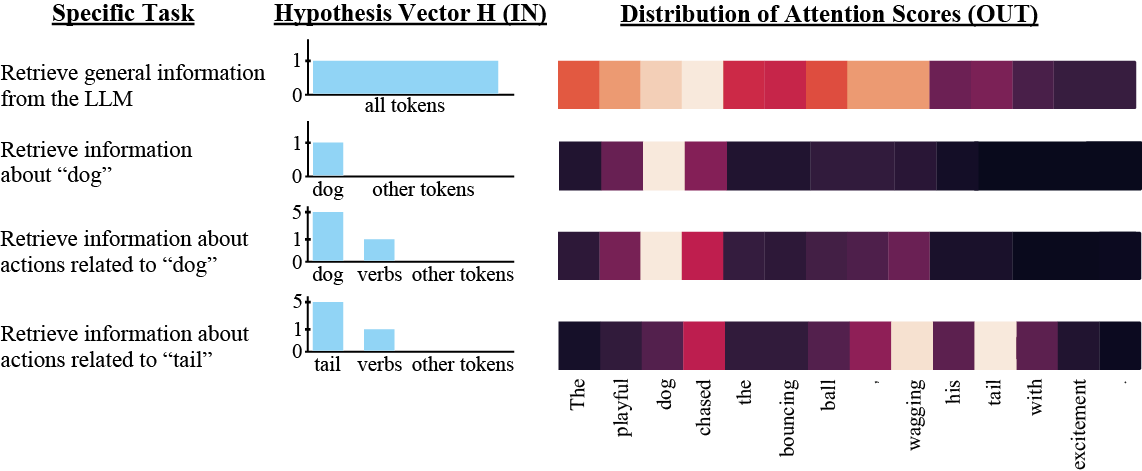
📊 实验亮点
在四个公开数据集上,Attention-Seeker在没有任何参数调优的情况下,超越了大多数基线模型,特别是在长文档的关键短语提取任务中,达到了最先进的性能,显示出其强大的实用性和有效性。
🎯 应用场景
该研究的潜在应用领域包括信息检索、文本摘要、内容推荐等。通过自动提取关键短语,Attention-Seeker可以帮助用户快速获取文本的核心信息,提高信息处理的效率。未来,该方法可能在多种语言处理任务中发挥重要作用,推动无监督学习的发展。
📄 摘要(原文)
This paper proposes Attention-Seeker, an unsupervised keyphrase extraction method that leverages self-attention maps from a Large Language Model to estimate the importance of candidate phrases. Our approach identifies specific components - such as layers, heads, and attention vectors - where the model pays significant attention to the key topics of the text. The attention weights provided by these components are then used to score the candidate phrases. Unlike previous models that require manual tuning of parameters (e.g., selection of heads, prompts, hyperparameters), Attention-Seeker dynamically adapts to the input text without any manual adjustments, enhancing its practical applicability. We evaluate Attention-Seeker on four publicly available datasets: Inspec, SemEval2010, SemEval2017, and Krapivin. Our results demonstrate that, even without parameter tuning, Attention-Seeker outperforms most baseline models, achieving state-of-the-art performance on three out of four datasets, particularly excelling in extracting keyphrases from long documents.