CREAM: Comparison-Based Reference-Free ELO-Ranked Automatic Evaluation for Meeting Summarization
作者: Ziwei Gong, Lin Ai, Harshsaiprasad Deshpande, Alexander Johnson, Emmy Phung, Zehui Wu, Ahmad Emami, Julia Hirschberg
分类: cs.CL
发布日期: 2024-09-17
💡 一句话要点
提出CREAM,一种基于比较和ELO排序的免参考会议摘要自动评估方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 会议摘要 自动评估 大型语言模型 思维链推理 ELO排序
📋 核心要点
- 现有自动摘要评估方法在长文本和对话式会议摘要等复杂场景下表现不足。
- CREAM通过思维链推理和关键事实对齐,在无参考摘要的情况下评估简洁性和完整性。
- CREAM采用ELO排序系统,为不同模型或提示配置的质量比较提供可靠机制。
📝 摘要(中文)
大型语言模型(LLMs)激发了人们对摘要自动评估方法的兴趣,它提供了一种比人工评估更快、更经济高效的替代方案。然而,现有的方法在应用于长文本摘要和基于对话的会议摘要等复杂任务时往往表现不佳。本文介绍了一种名为CREAM(Comparison-Based Reference-Free Elo-Ranked Automatic Evaluation for Meeting Summarization)的新型框架,旨在解决评估会议摘要的独特挑战。CREAM结合了思维链推理和关键事实对齐,以评估模型生成的摘要的简洁性和完整性,而无需参考摘要。通过采用ELO排序系统,我们的方法为比较不同模型或提示配置的质量提供了一种强大的机制。
🔬 方法详解
问题定义:论文旨在解决会议摘要自动评估的问题,现有方法在处理长文本和对话式会议记录时,无法准确评估摘要的质量,尤其是在缺乏参考摘要的情况下。现有的基于LLM的评估方法在长文本和复杂对话场景下表现不佳,无法有效衡量摘要的简洁性和完整性。
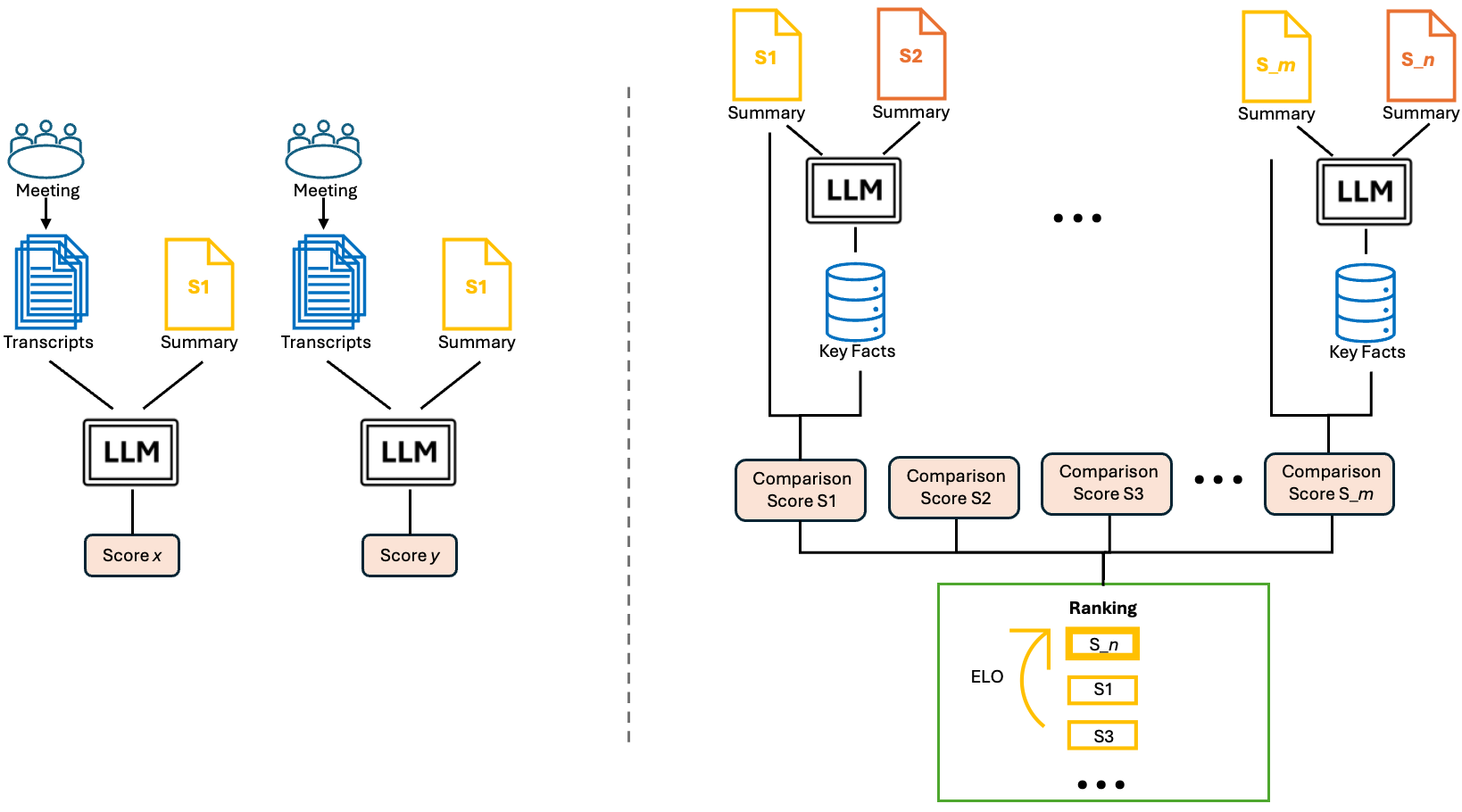
核心思路:CREAM的核心思路是利用大型语言模型(LLMs)的推理能力,通过思维链(Chain-of-Thought)的方式,对摘要进行多维度的评估,包括简洁性和完整性。同时,采用ELO排序系统,通过两两比较的方式,对不同摘要进行排序,从而避免了对参考摘要的依赖。这种设计旨在模拟人类评估的过程,提高评估的准确性和鲁棒性。
技术框架:CREAM框架主要包含以下几个阶段:1) 摘要生成:使用不同的模型或提示配置生成多个会议摘要。2) 思维链推理:利用LLM对每个摘要进行思维链推理,提取关键事实和信息。3) 关键事实对齐:将提取的关键事实与原始会议记录进行对齐,评估摘要的完整性和准确性。4) ELO排序:使用ELO排序系统,对不同摘要进行两两比较,根据比较结果更新摘要的排名。
关键创新:CREAM的关键创新在于:1) 免参考评估:无需参考摘要即可进行评估,解决了实际应用中参考摘要难以获取的问题。2) 基于比较的评估:通过两两比较的方式,提高了评估的鲁棒性和准确性。3) 结合思维链推理:利用LLM的推理能力,对摘要进行更深入的分析和评估。
关键设计:CREAM的关键设计包括:1) 思维链提示工程:设计有效的思维链提示,引导LLM进行准确的推理和关键事实提取。2) ELO排序参数:选择合适的ELO排序参数,如K值,以控制排名的更新速度和稳定性。3) 关键事实对齐策略:设计有效的关键事实对齐策略,例如使用语义相似度匹配或知识图谱对齐,以提高对齐的准确性。
🖼️ 关键图片

📊 实验亮点
论文提出的CREAM框架在会议摘要评估任务上取得了显著成果。通过实验验证,CREAM能够有效地评估摘要的质量,并与人工评估结果具有较高的一致性。此外,CREAM在不同模型和提示配置下的表现稳定,证明了其鲁棒性和泛化能力。具体的性能数据和对比基线信息未知。
🎯 应用场景
CREAM可应用于各种会议摘要场景,例如自动生成会议纪要、评估不同摘要模型的性能、优化摘要生成算法等。该方法能够有效降低人工评估的成本,提高摘要评估的效率和客观性。未来,CREAM可以扩展到其他文本摘要任务,例如新闻摘要、文档摘要等,具有广泛的应用前景。
📄 摘要(原文)
Large Language Models (LLMs) have spurred interest in automatic evaluation methods for summarization, offering a faster, more cost-effective alternative to human evaluation. However, existing methods often fall short when applied to complex tasks like long-context summarizations and dialogue-based meeting summarizations. In this paper, we introduce CREAM (Comparison-Based Reference-Free Elo-Ranked Automatic Evaluation for Meeting Summarization), a novel framework that addresses the unique challenges of evaluating meeting summaries. CREAM leverages a combination of chain-of-thought reasoning and key facts alignment to assess conciseness and completeness of model-generated summaries without requiring reference. By employing an ELO ranking system, our approach provides a robust mechanism for comparing the quality of different models or prompt configurations.