Model Tells Itself Where to Attend: Faithfulness Meets Automatic Attention Steering
作者: Qingru Zhang, Xiaodong Yu, Chandan Singh, Xiaodong Liu, Liyuan Liu, Jianfeng Gao, Tuo Zhao, Dan Roth, Hao Cheng
分类: cs.CL, cs.AI
发布日期: 2024-09-16
备注: 12 pages, 4 figures
🔗 代码/项目: GITHUB
💡 一句话要点
AutoPASTA:通过自动注意力引导提升LLM在开放域问答中的可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 注意力机制 开放域问答 模型可靠性 上下文理解
📋 核心要点
- 大型语言模型在长文本或干扰信息下,难以有效利用上下文,导致回答不忠实或产生幻觉。
- AutoPASTA通过自动识别关键上下文信息,并显式地引导LLM的注意力分数,从而提高模型可靠性。
- 实验表明,AutoPASTA能有效提升模型对关键上下文信息的理解,显著提高开放域问答的性能,如LLAMA3-70B-Instruct平均提升7.95%。
📝 摘要(中文)
大型语言模型(LLM)在各种实际任务中表现出卓越的性能。然而,它们常常难以完全理解和有效利用其输入上下文,导致不忠实或产生幻觉的回答。当上下文较长或包含分散注意力的信息时,这种困难会加剧,这会使LLM无法完全捕捉到关键证据。为了解决这个问题,许多工作使用提示来帮助LLM更忠实地利用上下文信息。例如,迭代提示分两步突出显示关键信息,首先要求LLM识别重要的上下文片段,然后据此得出答案。然而,提示方法仅限于在token空间中隐式地突出显示关键信息,这通常不足以完全引导模型的注意力。为了更可靠地提高模型的可靠性,我们提出AutoPASTA,一种自动识别关键上下文信息并通过引导LLM的注意力分数来显式突出显示它的方法。与提示类似,AutoPASTA在推理时应用,不需要更改任何模型参数。我们在开放域问答上的实验表明,AutoPASTA有效地使模型能够掌握关键的上下文信息,从而显著提高模型的可靠性和性能,例如,LLAMA3-70B-Instruct平均提高了7.95%。代码将在https://github.com/QingruZhang/AutoPASTA 公开。
🔬 方法详解
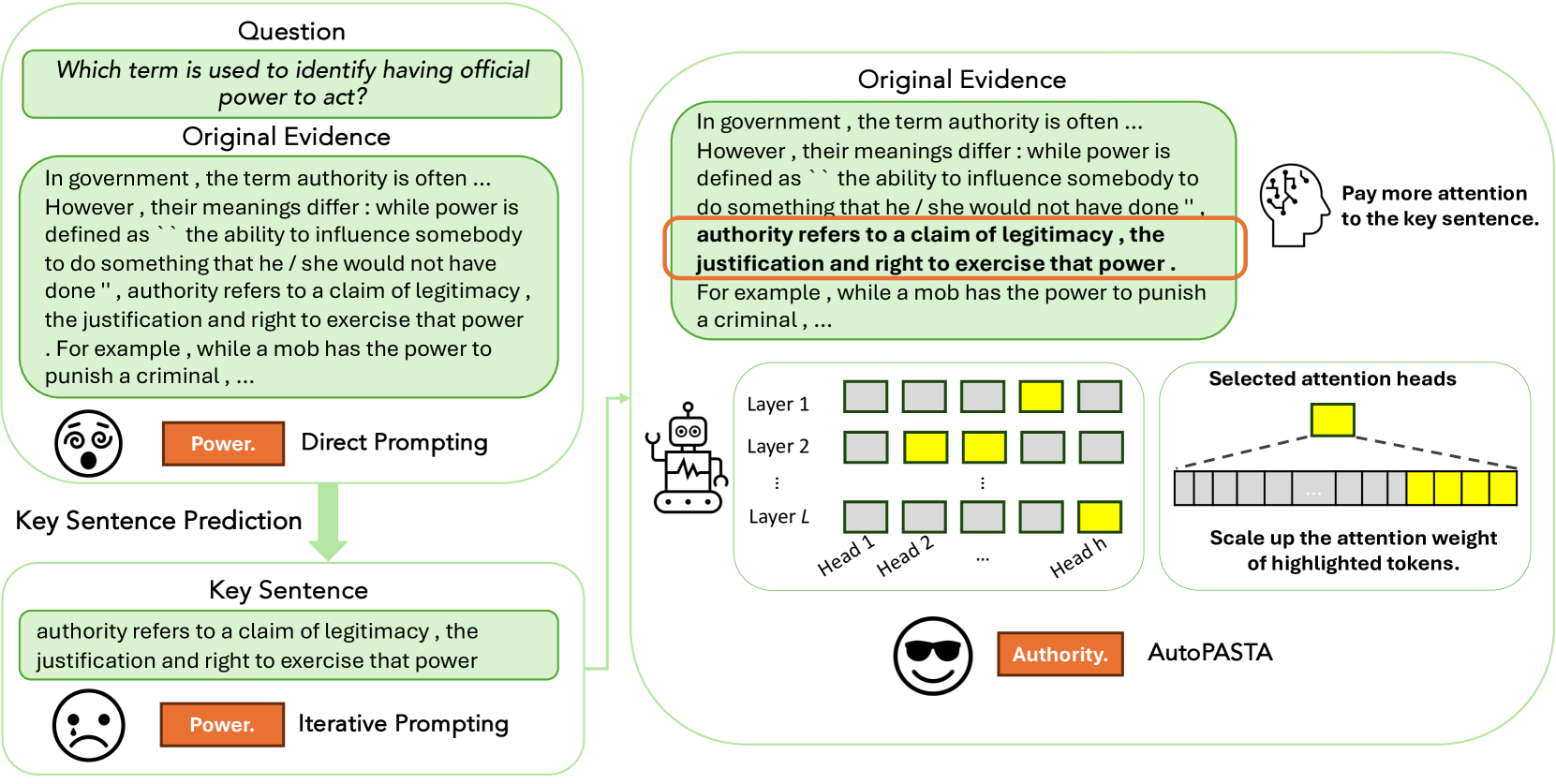
问题定义:论文旨在解决大型语言模型(LLM)在处理长文本或包含干扰信息的上下文时,难以有效利用关键信息,从而导致回答不忠实或产生幻觉的问题。现有方法,如基于提示的方法,虽然可以帮助LLM关注关键信息,但它们通常只能在token空间中隐式地突出显示信息,不足以完全引导模型的注意力。
核心思路:AutoPASTA的核心思路是自动识别关键的上下文信息,并显式地引导LLM的注意力分数,从而使模型能够更准确地关注重要的证据。这种显式的注意力引导可以克服传统提示方法的局限性,提高模型对上下文的理解和利用能力。
技术框架:AutoPASTA在推理阶段应用,无需修改模型参数。其主要流程包括:1) 使用某种方法(具体方法未知,论文未详细说明)自动识别输入上下文中的关键信息片段;2) 根据识别出的关键信息,调整LLM的注意力权重,使模型更加关注这些关键片段;3) LLM基于调整后的注意力权重生成最终的答案。
关键创新:AutoPASTA的关键创新在于它能够自动地、显式地引导LLM的注意力。与传统的提示方法相比,AutoPASTA不是通过隐式的方式影响模型的注意力,而是直接修改注意力分数,从而更有效地引导模型关注关键信息。这种显式的注意力引导是AutoPASTA能够显著提高模型可靠性的关键。
关键设计:论文中没有详细说明自动识别关键信息的方法,以及如何根据关键信息调整注意力权重的具体技术细节。这些细节是AutoPASTA实现的关键,但论文中没有提供足够的信息。
🖼️ 关键图片
📊 实验亮点
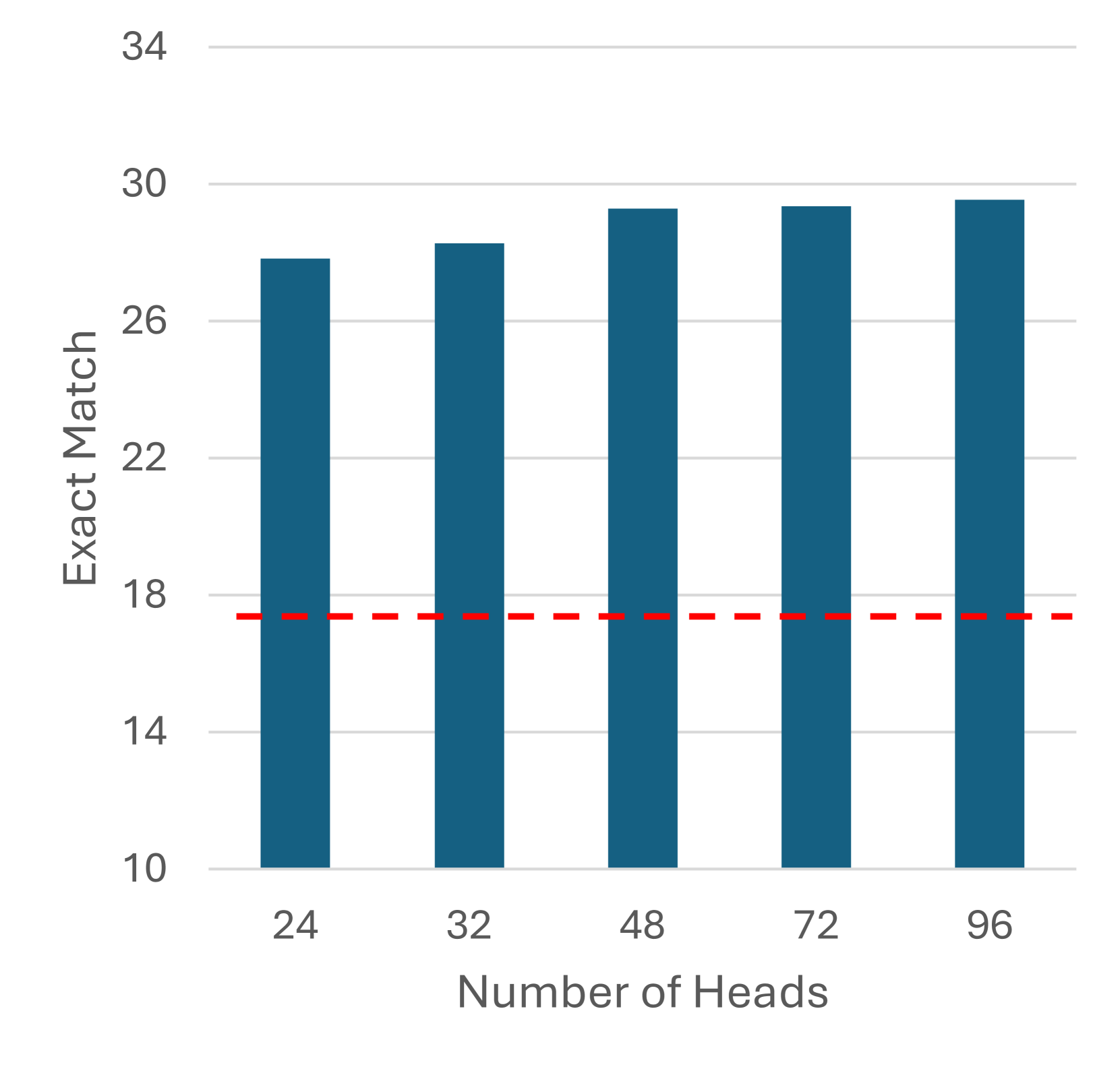
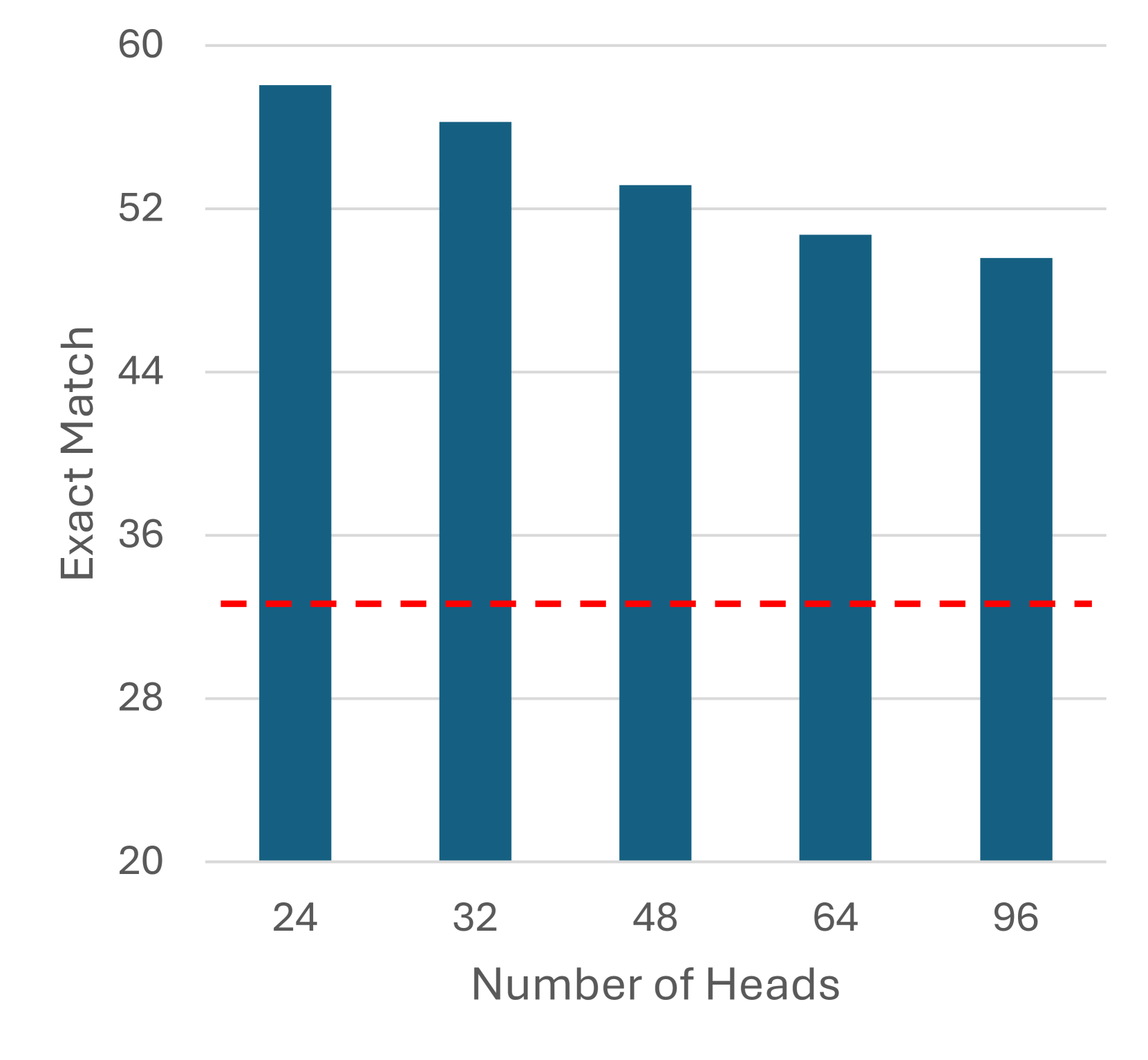
AutoPASTA在开放域问答任务上取得了显著的性能提升。实验结果表明,AutoPASTA能够有效地使模型掌握关键的上下文信息,从而显著提高模型的可靠性和性能。例如,在LLAMA3-70B-Instruct模型上,AutoPASTA实现了平均7.95%的性能提升,证明了其有效性。
🎯 应用场景
AutoPASTA具有广泛的应用前景,可以应用于各种需要LLM处理长文本或复杂上下文的任务中,例如开放域问答、文档摘要、信息检索等。通过提高LLM的可靠性和准确性,AutoPASTA可以帮助人们更有效地利用LLM解决实际问题,并减少因模型幻觉而产生的错误信息。
📄 摘要(原文)
Large language models (LLMs) have demonstrated remarkable performance across various real-world tasks. However, they often struggle to fully comprehend and effectively utilize their input contexts, resulting in responses that are unfaithful or hallucinated. This difficulty increases for contexts that are long or contain distracting information, which can divert LLMs from fully capturing essential evidence. To address this issue, many works use prompting to help LLMs utilize contextual information more faithfully. For instance, iterative prompting highlights key information in two steps that first ask the LLM to identify important pieces of context and then derive answers accordingly. However, prompting methods are constrained to highlighting key information implicitly in token space, which is often insufficient to fully steer the model's attention. To improve model faithfulness more reliably, we propose AutoPASTA, a method that automatically identifies key contextual information and explicitly highlights it by steering an LLM's attention scores. Like prompting, AutoPASTA is applied at inference time and does not require changing any model parameters. Our experiments on open-book QA demonstrate that AutoPASTA effectively enables models to grasp essential contextual information, leading to substantially improved model faithfulness and performance, e.g., an average improvement of 7.95% for LLAMA3-70B-Instruct. Code will be publicly available at https://github.com/QingruZhang/AutoPASTA .