Improving Multi-candidate Speculative Decoding
作者: Xiaofan Lu, Yixiao Zeng, Feiyang Ma, Zixu Yu, Marco Levorato
分类: cs.CL
发布日期: 2024-09-16 (更新: 2024-12-14)
备注: Accepted by NeurIPS ENLSP 2024 Workshop
💡 一句话要点
提出目标模型引导的多候选推测解码方法,提升大语言模型推理速度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推测解码 多候选生成 大语言模型 模型加速 动态掩码
📋 核心要点
- 现有MCSD方法依赖草稿模型,易受草稿模型和目标模型输出分布差异的影响,尤其是在动态生成环境中。
- 提出一种新的MCSD方法,包含目标模型初始化的多候选生成、动态长度调整和优化提前停止的决策模型。
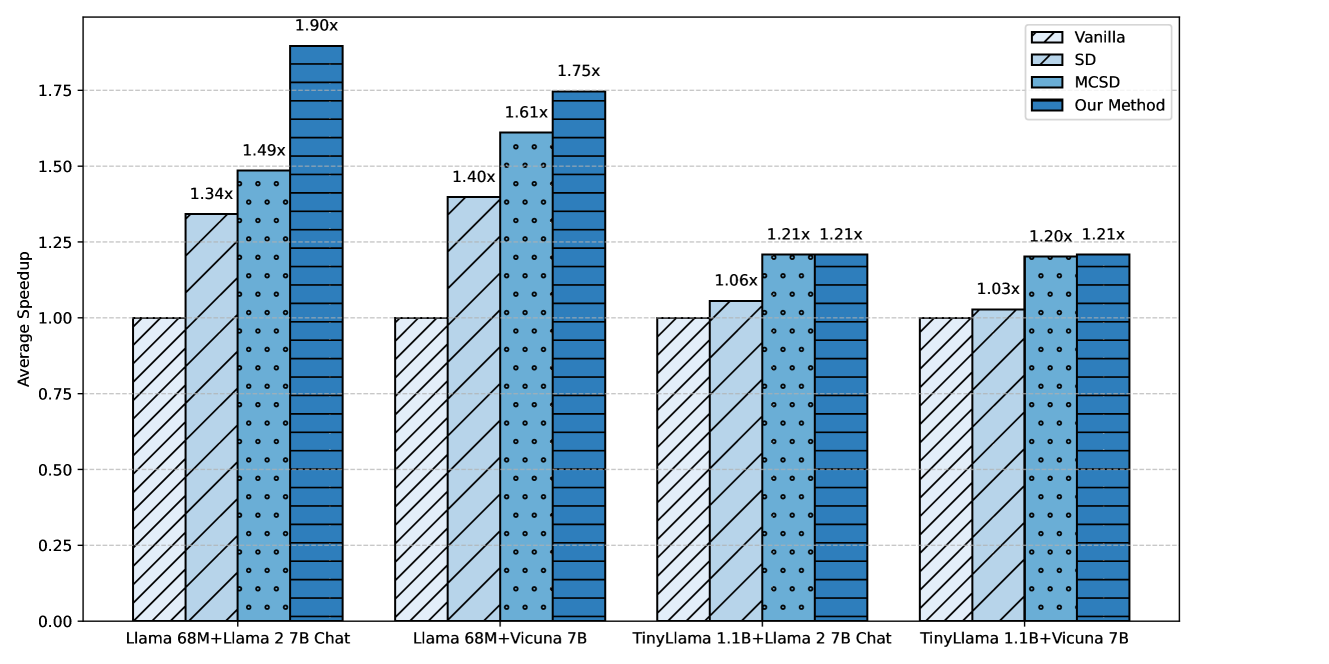
- 实验表明,该方法在Llama 2-7B及其变体上,实现了最高27.5%的加速,并评估了不同草稿模型对输出质量的影响。
📝 摘要(中文)
本文提出了一种改进的多候选推测解码(MCSD)方法,旨在加速大型语言模型(LLM)的推理过程。MCSD通过使用复杂度较低的草稿模型并行生成多个候选token,并由较大的目标模型进行验证,从而提高token接受率并减少生成时间。现有MCSD方法依赖草稿模型初始化多候选序列,并采用静态长度和树状注意力结构,但易受草稿模型和目标模型输出分布差异的影响,尤其是在动态生成环境中。本文提出的新版本MCSD包含目标模型初始化的多候选生成、动态切片拓扑感知的因果掩码以进行动态长度调整,以及优化提前停止的决策模型。实验结果表明,在Llama 2-7B及其变体上,与MCSD基线相比,该方法在三个基准测试中实现了最高27.5%的加速,目标模型为Llama 2-7B,草稿模型为JackFram 68M。此外,还评估了使用目标模型初始化的多候选过程与不同草稿模型对输出质量的影响。
🔬 方法详解
问题定义:现有的多候选推测解码(MCSD)方法在加速大型语言模型推理时,依赖于草稿模型生成多个候选token。然而,草稿模型与目标模型之间存在输出分布差异,尤其是在动态生成上下文中,这会导致候选token的质量下降,降低加速效果。此外,现有方法采用静态长度和树状注意力结构,无法灵活适应生成过程中的动态变化。
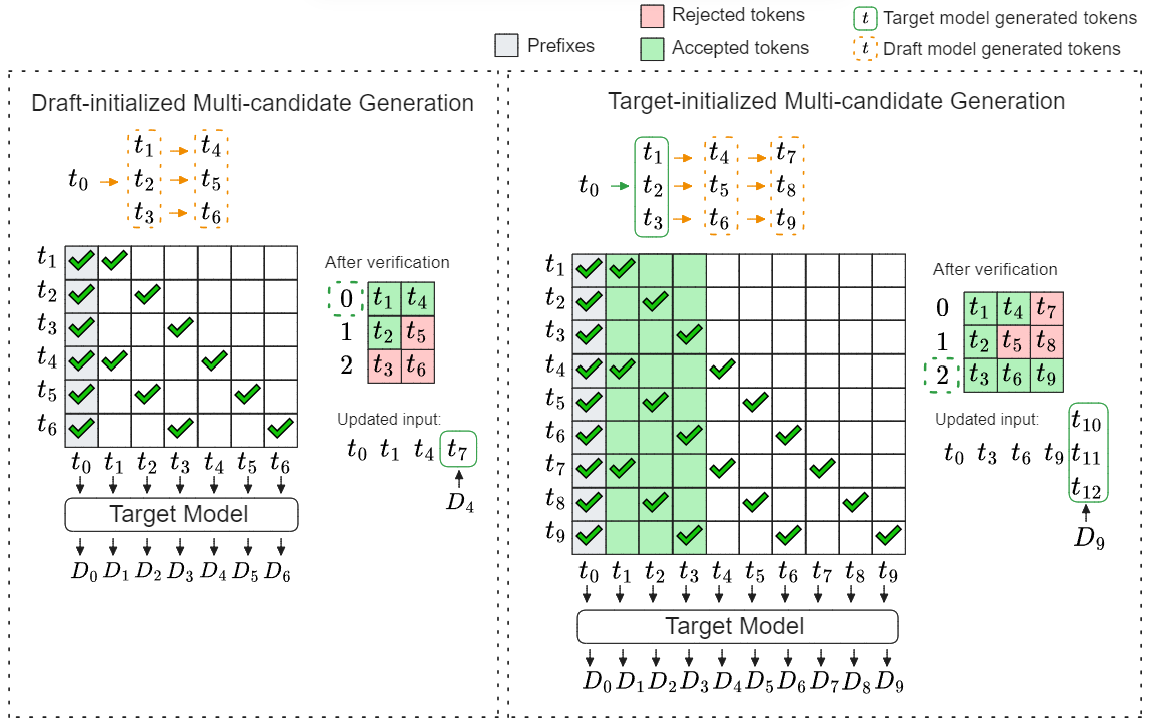
核心思路:本文的核心思路是通过引入目标模型的信息来引导多候选token的生成过程,从而减小草稿模型和目标模型之间的差距。具体来说,使用目标模型初始化多候选序列,并设计动态的因果掩码来适应不同长度的候选序列。同时,引入决策模型来优化提前停止策略,进一步提高效率。
技术框架:该方法主要包含三个关键模块:1) 目标模型初始化的多候选生成:使用目标模型对初始token进行编码,并以此为基础生成多个候选token。2) 动态切片拓扑感知的因果掩码:根据候选序列的长度动态调整因果掩码,确保每个token只能依赖于之前的token。3) 决策模型:根据当前状态判断是否提前停止生成,避免不必要的计算。
关键创新:该方法最重要的创新点在于使用目标模型的信息来引导多候选token的生成过程。与现有方法相比,该方法能够更好地利用目标模型的知识,生成更准确的候选token,从而提高加速效果。此外,动态因果掩码和决策模型的引入也进一步提升了方法的灵活性和效率。
关键设计:目标模型初始化的多候选生成过程可以使用不同的采样策略,例如top-k采样或nucleus采样。动态因果掩码的设计需要考虑计算效率和表达能力之间的平衡。决策模型可以使用强化学习或监督学习进行训练,目标是最大化加速效果。
🖼️ 关键图片

📊 实验亮点
实验结果表明,本文提出的方法在Llama 2-7B及其变体上,与MCSD基线相比,在三个基准测试中实现了最高27.5%的加速,目标模型为Llama 2-7B,草稿模型为JackFram 68M。这表明该方法能够有效提高大型语言模型的推理速度,具有显著的性能优势。此外,实验还评估了使用目标模型初始化的多候选过程与不同草稿模型对输出质量的影响,为实际应用中选择合适的草稿模型提供了参考。
🎯 应用场景
该研究成果可广泛应用于需要加速大型语言模型推理的场景,例如在线对话系统、机器翻译、文本摘要等。通过提高推理速度,可以降低计算成本,提升用户体验,并促进大型语言模型在更多实际应用中的部署。未来,该方法可以进一步扩展到其他类型的生成模型,并与其他加速技术相结合,实现更高效的推理。
📄 摘要(原文)
Speculative Decoding (SD) is a technique to accelerate the inference of Large Language Models (LLMs) by using a lower complexity draft model to propose candidate tokens verified by a larger target model. To further improve efficiency, Multi-Candidate Speculative Decoding (MCSD) improves upon this by sampling multiple candidate tokens from the draft model at each step and verifying them in parallel, thus increasing the chances of accepting a token and reducing generation time. Existing MCSD methods rely on the draft model to initialize the multi-candidate sequences and use static length and tree attention structure for draft generation. However, such an approach suffers from the draft and target model's output distribution differences, especially in a dynamic generation context. In this work, we introduce a new version of MCSD that includes a target model initialized multi-candidate generation, a dynamic sliced topology-aware causal mask for dynamic length adjustment, and decision models to optimize early stopping. We experimented with our method on Llama 2-7B and its variants and observed a maximum 27.5% speedup compared to our MCSD baseline across three benchmarks with Llama 2-7B as the target model and JackFram 68M as the draft model. Additionally, we evaluate the effects of using the target model initialized multi-candidate process with different draft models on output quality.