IW-Bench: Evaluating Large Multimodal Models for Converting Image-to-Web
作者: Hongcheng Guo, Wei Zhang, Junhao Chen, Yaonan Gu, Jian Yang, Junjia Du, Shaosheng Cao, Binyuan Hui, Tianyu Liu, Jianxin Ma, Chang Zhou, Zhoujun Li
分类: cs.CL, cs.AI, cs.CV
发布日期: 2024-09-14 (更新: 2025-12-03)
💡 一句话要点
提出IW-Bench基准,评估大型多模态模型在图像到Web转换任务中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像到Web转换 多模态模型 基准数据集 评估指标 思维链提示
📋 核心要点
- 现有方法在评估图像到Web转换任务时,忽略了Web元素完整性(尤其是不可见元素)和布局信息,导致评估结果不准确。
- 论文提出IW-Bench基准,包含图像和对应的Web代码,并设计了元素准确率和布局准确率来评估模型性能。
- 通过五跳多模态思维链提示,模型性能得到提升。实验结果揭示了现有模型在图像到Web转换领域的性能瓶颈。
📝 摘要(中文)
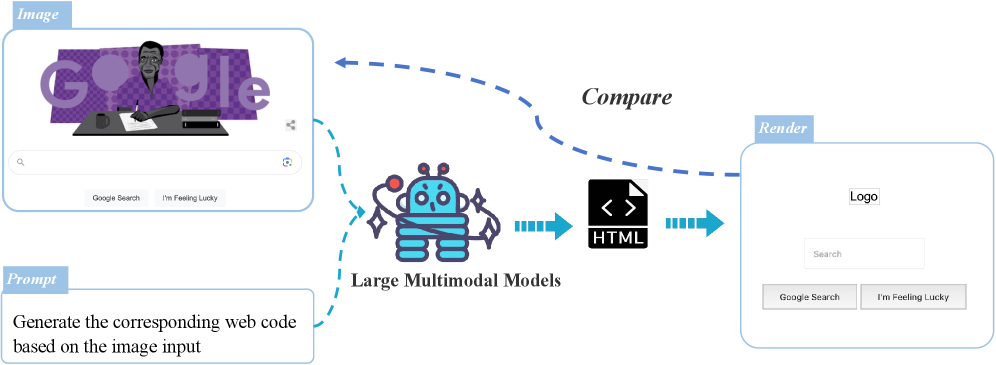
近年来,大型多模态模型在图像理解能力方面取得了显著进展。然而,目前缺乏专门用于评估这些大型模型在图像到Web转换任务中能力的可靠基准。确保生成的Web元素完整性至关重要,这些元素包含可见和不可见类别。以往的评估方法(如BLEU)容易受到Web中不可见元素的影响而产生显著偏差。此外,测量网页的布局信息(即元素之间的位置关系)至关重要,而以往的工作忽略了这一点。为了解决这些挑战,我们整理并对齐了一个图像和相应Web代码的基准(IW-BENCH)。具体来说,我们提出了元素准确率(Element Accuracy),通过解析文档对象模型(DOM)树来测试元素的完整性。还提出了布局准确率(Layout Accuracy),通过将DOM树转换为公共子序列来分析元素的位置关系。此外,我们设计了一个五跳多模态思维链提示(Chain-of-Thought Prompting)以获得更好的性能,包含五个步骤:1) SoM提示注入;2) 推断元素;3) 推断布局;4) 推断Web代码;5) 反思。我们的基准包含1200对具有不同难度级别的图像和Web代码。我们对现有的大型多模态模型进行了广泛的实验,从而深入了解了它们在图像到Web领域的性能和改进方向。
🔬 方法详解
问题定义:论文旨在解决大型多模态模型在图像到Web转换任务中缺乏有效评估基准的问题。现有评估方法,如BLEU,对Web代码中不可见元素敏感,且忽略了网页布局信息,无法准确反映模型的转换能力。因此,需要一个能够全面评估模型生成Web代码质量的基准。
核心思路:论文的核心思路是构建一个包含图像和对应Web代码的基准数据集IW-Bench,并设计新的评估指标来衡量生成Web代码的元素完整性和布局准确性。通过分析DOM树结构,提取元素信息和位置关系,从而更全面地评估模型的性能。
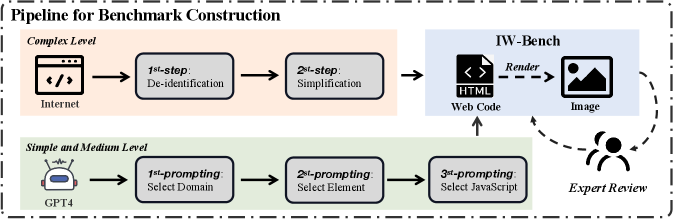
技术框架:IW-Bench基准包含1200对图像和Web代码。评估流程包括:1) 模型生成Web代码;2) 解析生成的Web代码和ground truth Web代码的DOM树;3) 使用元素准确率评估元素完整性;4) 使用布局准确率评估布局准确性;5) 使用五跳多模态思维链提示提升模型性能。
关键创新:论文的关键创新在于:1) 构建了专门用于图像到Web转换任务的基准数据集IW-Bench;2) 提出了元素准确率和布局准确率两个新的评估指标,能够更全面地评估模型生成的Web代码质量;3) 设计了五跳多模态思维链提示,提升了模型性能。
关键设计:元素准确率通过比较生成Web代码和ground truth Web代码的DOM树中的元素数量来计算。布局准确率通过将DOM树转换为公共子序列,并计算公共子序列的长度来评估布局的相似度。五跳多模态思维链提示包含SoM提示注入、推断元素、推断布局、推断Web代码和反思五个步骤,引导模型逐步生成高质量的Web代码。
🖼️ 关键图片

📊 实验亮点
论文构建了包含1200对图像和Web代码的IW-Bench基准,并提出了元素准确率和布局准确率两个新的评估指标。实验结果表明,现有大型多模态模型在IW-Bench上表现仍有提升空间,表明该基准能够有效评估模型的图像到Web转换能力。五跳多模态思维链提示能够有效提升模型性能。
🎯 应用场景
该研究成果可应用于自动化网页生成、UI设计辅助、无障碍网页开发等领域。通过提高图像到Web转换的准确性和效率,可以降低网页开发成本,提升用户体验,并为视觉障碍人士提供更好的网页浏览体验。未来,该技术有望应用于更广泛的跨模态内容生成任务。
📄 摘要(原文)
Recently advancements in large multimodal models have led to significant strides in image comprehension capabilities. Despite these advancements, there is a lack of the robust benchmark specifically for assessing the Image-to-Web conversion proficiency of these large models. Primarily, it is essential to ensure the integrity of the web elements generated. These elements comprise visible and invisible categories. Previous evaluation methods (e.g.,BLEU) are notably susceptible to significant alterations due to the presence of invisible elements in Web. Furthermore, it is crucial to measure the layout information of web pages, referring to the positional relationships between elements, which is overlooked by previous work. To address challenges, we have curated and aligned a benchmark of images and corresponding web codes (IW-BENCH). Specifically, we propose the Element Accuracy, which tests the completeness of the elements by parsing the Document Object Model (DOM) tree. Layout Accuracy is also proposed to analyze the positional relationships of elements by converting DOM tree into a common subsequence. Besides, we design a five-hop multimodal Chain-of-Thought Prompting for better performance, which contains five hop: 1) SoM prompt injection. 2) Inferring Elements. 3) Inferring Layout. 4) Inferring Web code. 5) Reflection. Our benchmark comprises 1200 pairs of images and web codes with varying levels of difficulty. We have conducted extensive experiments on existing large multimodal models, offering insights into their performance and areas for improvement in image-to-web domain.