ASR Error Correction using Large Language Models
作者: Rao Ma, Mengjie Qian, Mark Gales, Kate Knill
分类: cs.CL, cs.SD, eess.AS
发布日期: 2024-09-14 (更新: 2025-01-18)
备注: This work has been submitted to the IEEE for possible publication
💡 一句话要点
利用大语言模型提升ASR纠错性能,无需访问底层代码或模型权重。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动语音识别 误差校正 大语言模型 N-best列表 约束解码
📋 核心要点
- 现有误差校正模型通常依赖于特定ASR系统,缺乏跨系统泛化能力,且在未见领域表现不佳。
- 利用大语言模型强大的上下文理解和生成能力,结合N-best列表和约束解码,提升纠错性能。
- 实验表明,该方法在多个数据集和ASR系统上有效,并可用于模型集成和零样本误差校正。
📝 摘要(中文)
误差校正(EC)模型在改进自动语音识别(ASR)转录文本方面起着关键作用,能够提高转录文本的可读性和质量。在无需访问底层代码或模型权重的情况下,EC可以提高黑盒ASR系统的性能并提供领域自适应。本文研究了使用大型语言模型(LLM)在各种场景下进行误差校正。通常,EC模型的输入是ASR的1-best假设。我们提出使用ASR N-best列表构建高性能EC模型,这应为校正过程提供更多的上下文信息。此外,标准EC模型的生成过程是不受限制的,可以生成任何输出序列。对于某些场景,例如未见过的领域,这种灵活性可能会影响性能。为了解决这个问题,我们引入了一种基于N-best列表或ASR lattice的约束解码方法。最后,大多数EC模型都是针对特定的ASR系统进行训练的,每当底层ASR系统发生变化时都需要重新训练。本文探讨了EC模型在不同ASR系统输出上运行的能力。这种概念进一步扩展到使用LLM(如ChatGPT)进行零样本误差校正。在三个标准数据集上的实验证明了我们提出的方法对于Transducer和基于注意力机制的编码器-解码器ASR系统的有效性。此外,所提出的方法可以作为一种有效的模型集成方法。
🔬 方法详解
问题定义:论文旨在解决自动语音识别(ASR)系统产生的转录错误问题。现有误差校正(EC)模型通常针对特定ASR系统训练,当底层ASR系统改变时需要重新训练,泛化能力较弱。此外,在面对未见过的领域时,现有EC模型的性能也会下降。现有方法的痛点在于缺乏跨系统和跨领域的适应性。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的语言理解和生成能力,结合ASR N-best列表提供的上下文信息,进行更准确的误差校正。通过约束解码,限制LLM的生成空间,避免生成不合理的输出,从而提高在未见领域上的性能。同时,探索LLM在不同ASR系统输出上的泛化能力,实现零样本误差校正。
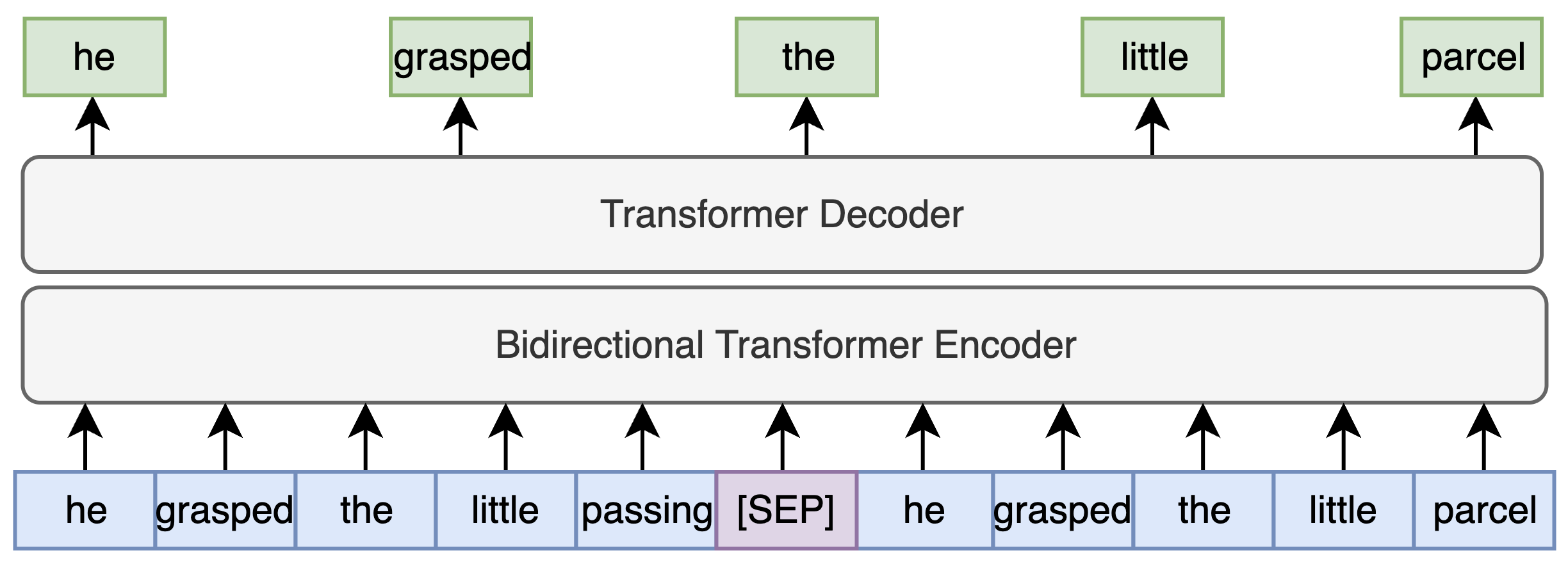
技术框架:整体框架包括以下几个主要阶段:1) ASR系统生成N-best列表或lattice;2) 将N-best列表或lattice作为LLM的输入;3) 使用约束解码方法,根据N-best列表或lattice限制LLM的生成空间;4) LLM生成校正后的文本。
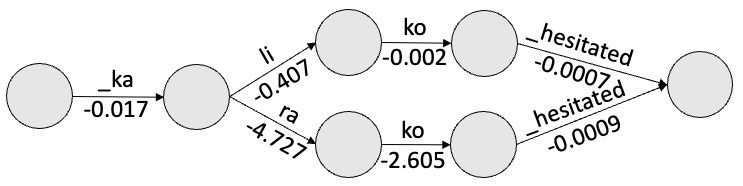
关键创新:论文的关键创新点在于:1) 利用ASR N-best列表作为EC模型的输入,提供更丰富的上下文信息;2) 提出基于N-best列表或ASR lattice的约束解码方法,提高在未见领域上的性能;3) 探索LLM在不同ASR系统输出上的泛化能力,实现零样本误差校正。
关键设计:论文的关键设计包括:1) 使用N-best列表,而非仅使用1-best假设,作为LLM的输入;2) 设计约束解码算法,例如,强制LLM的输出必须是N-best列表中的某个候选;3) 使用标准数据集进行实验,评估不同LLM(如ChatGPT)的性能;4) 探索不同的模型集成方法,将EC模型与ASR系统结合。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用ASR N-best列表和约束解码方法可以显著提高误差校正的性能。该方法在Transducer和基于注意力机制的编码器-解码器ASR系统上均有效。此外,该方法可以作为一种有效的模型集成方法,进一步提升ASR系统的整体性能。零样本误差校正实验也显示出LLM在跨系统泛化方面的潜力。
🎯 应用场景
该研究成果可广泛应用于语音助手、语音搜索、自动字幕生成等领域,提高语音交互的准确性和用户体验。通过零样本误差校正,可以降低模型训练成本,加速新领域的应用部署。该技术还有助于提升语音转录在噪声环境下的鲁棒性,具有重要的实际应用价值。
📄 摘要(原文)
Error correction (EC) models play a crucial role in refining Automatic Speech Recognition (ASR) transcriptions, enhancing the readability and quality of transcriptions. Without requiring access to the underlying code or model weights, EC can improve performance and provide domain adaptation for black-box ASR systems. This work investigates the use of large language models (LLMs) for error correction across diverse scenarios. 1-best ASR hypotheses are commonly used as the input to EC models. We propose building high-performance EC models using ASR N-best lists which should provide more contextual information for the correction process. Additionally, the generation process of a standard EC model is unrestricted in the sense that any output sequence can be generated. For some scenarios, such as unseen domains, this flexibility may impact performance. To address this, we introduce a constrained decoding approach based on the N-best list or an ASR lattice. Finally, most EC models are trained for a specific ASR system requiring retraining whenever the underlying ASR system is changed. This paper explores the ability of EC models to operate on the output of different ASR systems. This concept is further extended to zero-shot error correction using LLMs, such as ChatGPT. Experiments on three standard datasets demonstrate the efficacy of our proposed methods for both Transducer and attention-based encoder-decoder ASR systems. In addition, the proposed method can serve as an effective method for model ensembling.