Comparing Retrieval-Augmentation and Parameter-Efficient Fine-Tuning for Privacy-Preserving Personalization of Large Language Models
作者: Alireza Salemi, Hamed Zamani
分类: cs.CL
发布日期: 2024-09-14 (更新: 2025-06-26)
💡 一句话要点
对比检索增强与参数高效微调,实现大语言模型隐私保护的个性化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 个性化 检索增强生成 参数高效微调 隐私保护
📋 核心要点
- 现有大语言模型个性化方法主要依赖检索增强,但忽略了参数高效微调的潜力。
- 本文探索了参数高效微调(PEFT)在LLM个性化中的应用,并与检索增强生成(RAG)进行了对比。
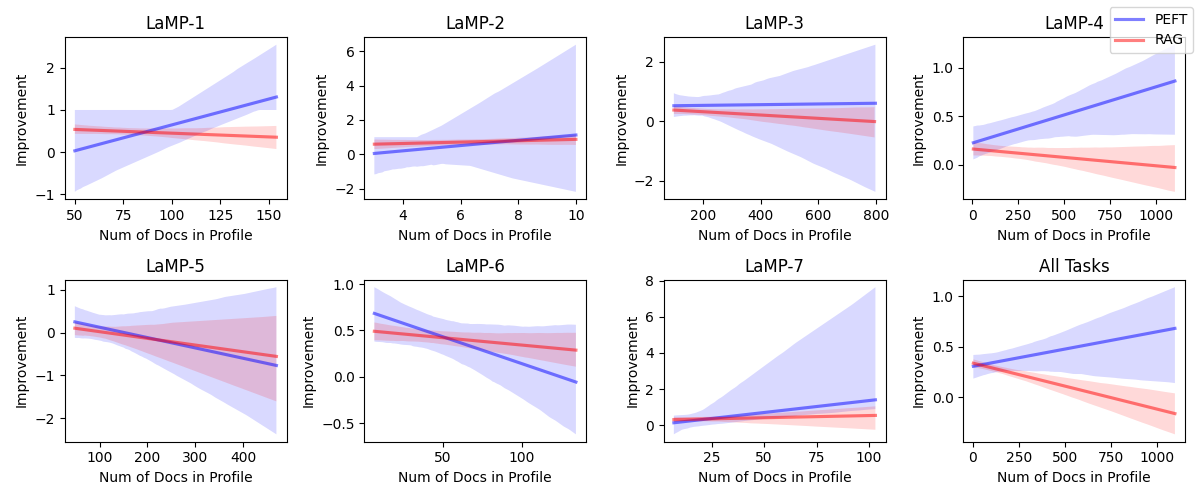
- 实验表明,RAG和PEFT均能提升个性化效果,结合使用效果更佳,且PEFT效果与用户数据量正相关。
📝 摘要(中文)
针对大语言模型(LLM)的个性化,现有研究主要集中在检索增强生成(RAG)方法上,即通过检索用户个人数据来丰富输入提示,从而生成个性化输出。本文研究了一种与RAG正交的方法:通过参数高效微调(PEFT)学习用户相关的LLM参数。本文首次系统地探索了PEFT在LLM个性化中的应用,并对基于RAG和PEFT的解决方案进行了广泛比较,使用了LaMP基准测试中的七个多样化数据集。结果表明,平均而言,基于RAG和PEFT的个性化方法分别比非个性化LLM提高了14.92%和1.07%。将RAG与PEFT结合使用时,观察到进一步的15.98%的改进,突出了它们在增强个性化文本生成方面的有效性。此外,我们发现用户可用数据量与PEFT的有效性之间存在正相关关系。这表明RAG特别有利于冷启动用户(个人数据有限的用户),而PEFT在有更多用户特定数据可用时表现更好。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)的个性化问题,即如何根据用户的个人数据定制LLM的输出,同时保护用户隐私。现有方法主要依赖检索增强生成(RAG),但RAG可能无法充分利用用户数据中的细粒度信息,且检索过程本身也可能存在隐私泄露风险。此外,直接全参数微调LLM成本高昂,不适用于大规模个性化。
核心思路:论文的核心思路是探索参数高效微调(PEFT)在LLM个性化中的应用。PEFT方法通过仅微调少量参数来实现模型个性化,降低了计算成本,并可能更好地保护用户隐私。同时,论文对比了PEFT和RAG两种方法的优劣,并探索了二者结合的可能性。
技术框架:论文的技术框架主要包括三个部分:1)基于RAG的个性化方法,即通过检索用户个人数据来丰富输入提示;2)基于PEFT的个性化方法,即通过微调LLM的部分参数来实现个性化;3)RAG与PEFT的结合,即先使用RAG生成初步的个性化输出,再使用PEFT对LLM进行微调,以进一步提升个性化效果。实验使用了LaMP基准测试中的七个数据集。
关键创新:论文的主要创新点在于:1)首次系统地研究了PEFT在LLM个性化中的应用;2)对RAG和PEFT两种个性化方法进行了全面的对比分析,揭示了它们各自的优缺点;3)提出了RAG与PEFT相结合的个性化方法,并验证了其有效性;4)发现了用户数据量与PEFT效果之间的正相关关系。
关键设计:论文中,PEFT具体采用了LoRA (Low-Rank Adaptation) 方法,只微调低秩矩阵。RAG方法使用了标准的检索流程,检索用户数据中与输入提示相关的文本片段。实验中,使用了多种LLM模型,并针对不同的数据集进行了参数调优。损失函数使用了交叉熵损失函数,优化器使用了AdamW优化器。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RAG和PEFT均能有效提升LLM的个性化效果,分别比非个性化LLM提高了14.92%和1.07%。RAG与PEFT结合使用时,个性化效果进一步提升了15.98%。此外,研究发现PEFT的效果与用户数据量呈正相关,表明RAG更适合冷启动用户,而PEFT更适合拥有大量数据的用户。
🎯 应用场景
该研究成果可应用于各种需要个性化文本生成的场景,例如个性化推荐、智能客服、内容创作等。通过结合RAG和PEFT,可以为用户提供更加精准、个性化的服务,同时保护用户隐私。未来的研究可以进一步探索更高效、更安全的PEFT方法,以及如何根据用户反馈动态调整个性化模型。
📄 摘要(原文)
Despite its substantial impact on various search, recommendation, and question answering tasks, privacy-preserving methods for personalizing large language models (LLMs) have received relatively limited exploration. There is one primary approach in this area through retrieval-augmented generation (RAG), which generates personalized outputs by enriching the input prompt with information retrieved from the user's personal data. This paper studies an orthogonal approach to RAG that involves learning user-dependent LLM parameters through parameter-efficient fine-tuning (PEFT). This paper presents the first systematic study for exploration of PEFT for LLM personalization and provides an extensive comparisons between RAG- and PEFT-based solutions, across a broad set of seven diverse datasets from the LaMP benchmark. Our results demonstrate that, on average, both RAG- and PEFT-based personalization methods yield 14.92% and 1.07% improvements over non-personalized LLMs, respectively. When combining RAG with PEFT, we observe a further improvement of 15.98%, highlighting the effectiveness of their integration in enhancing personalized text generation. Additionally, we identify a positive correlation between the amount of user data available and the effectiveness of PEFT. This finding suggests that RAG is particularly beneficial for cold-start users -- users with limited personal data -- while PEFT performs better when more user-specific data is available.