Keeping Humans in the Loop: Human-Centered Automated Annotation with Generative AI
作者: Nicholas Pangakis, Samuel Wolken
分类: cs.CL
发布日期: 2024-09-14 (更新: 2024-09-21)
备注: Accepted at Proceedings of the International AAAI Conference on Web and Social Media. Vol. 19. 2025
💡 一句话要点
提出以人为本的框架,评估生成式AI在社交媒体文本自动标注中的应用,强调人工验证的重要性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动标注 大语言模型 人机协作 社交媒体研究 文本分类
📋 核心要点
- 现有LLM自动标注研究依赖少量任务和公共数据集,可能存在污染,缺乏严谨评估。
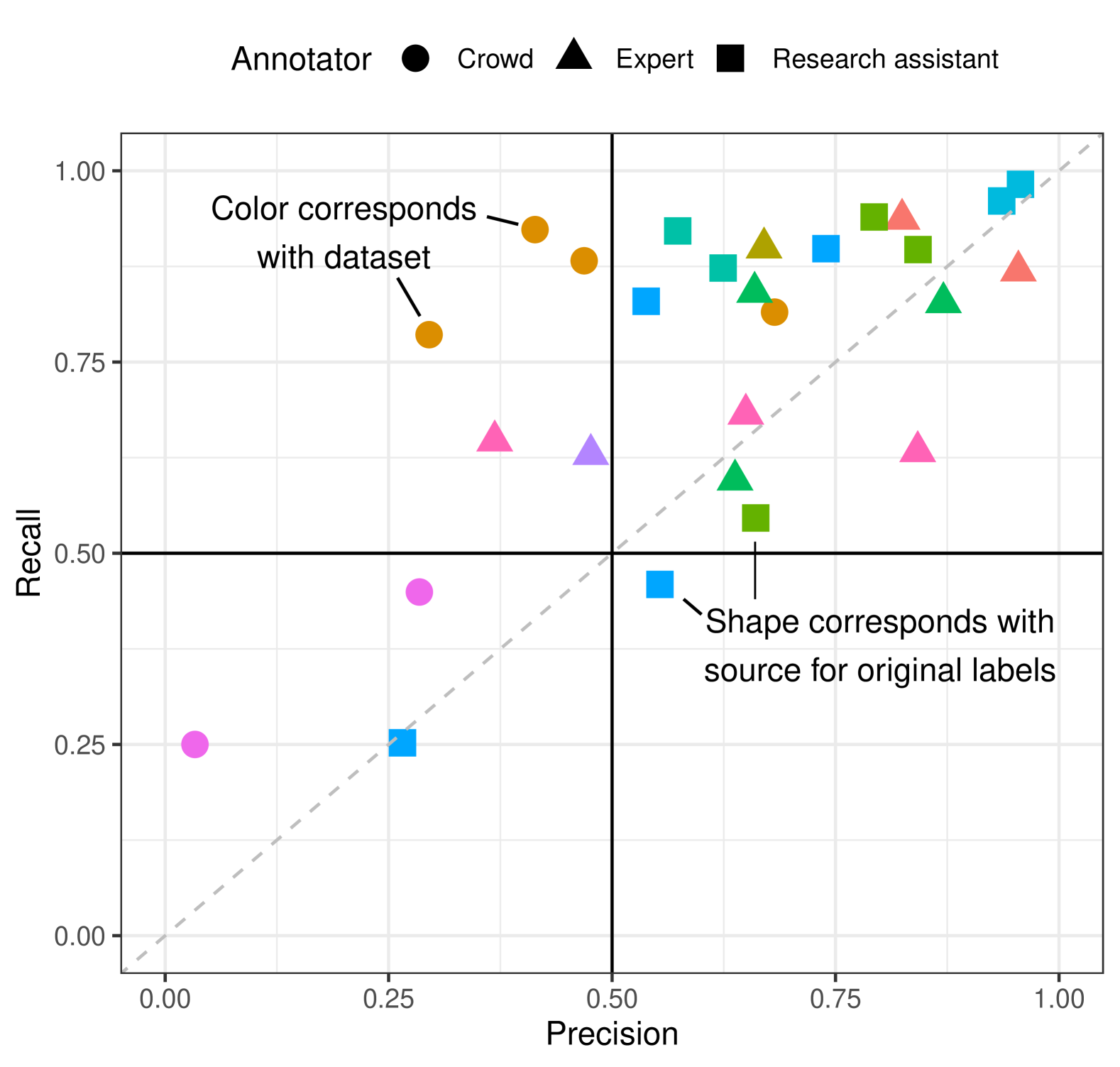
- 提出以人为本的评估框架,对比GPT-4标注、人工标注和监督模型,强调人工验证。
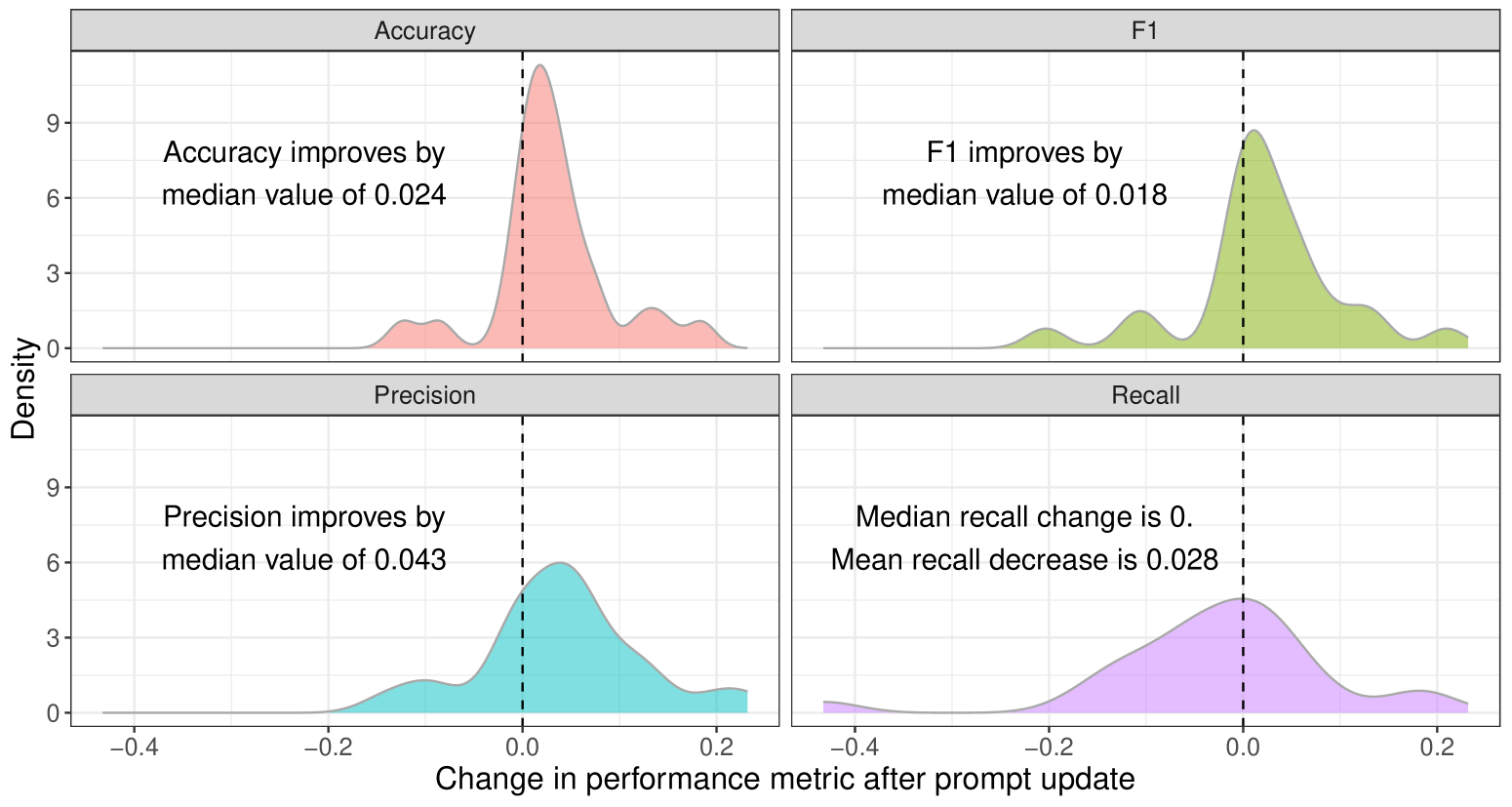
- 实验表明,LLM标注质量存在任务差异,自动标注与人类判断有显著偏差,需人工验证。
📝 摘要(中文)
本文研究了生成式大语言模型(LLMs)在社交媒体研究中自动文本标注的应用。尽管LLMs在标注任务中表现出潜力,但现有研究通常基于少量任务和可能存在污染的公共基准数据集。本文提出了一种以人为本的框架,用于负责任地评估自动标注中的人工智能工具。使用GPT-4复制了来自高影响力期刊的计算社会科学文章中11个密码保护数据集的27个标注任务。将GPT-4的标注结果与人工标注的ground-truth标签以及在人工生成标签上微调的监督分类模型的标注结果进行比较。结果表明,尽管LLM标签的质量通常较高,但LLM在不同任务中的表现存在显著差异,即使在同一数据集内也是如此。研究强调了以人为本的工作流程和谨慎评估标准的重要性:尽管采用了提示调优等优化策略,但自动标注在许多情况下与人类判断存在显著差异。因此,基于人类生成的验证标签进行自动标注的评估至关重要。
🔬 方法详解
问题定义:论文旨在解决社交媒体文本自动标注中,现有大语言模型(LLMs)评估方法不够严谨的问题。现有方法依赖于少量任务和可能存在数据污染的公共数据集,无法准确评估LLMs在实际应用中的性能,并且忽略了自动标注结果与人类判断之间的差异。
核心思路:论文的核心思路是建立一个以人为本的评估框架,通过对比LLMs的自动标注结果与人工标注的ground-truth标签,以及在人工标注数据上训练的监督模型的标注结果,来全面评估LLMs的性能。强调人工验证在自动标注流程中的重要性,确保标注结果的可靠性和准确性。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择来自已发表的计算社会科学文章的密码保护数据集,避免数据污染;2) 使用GPT-4对数据集中的文本进行自动标注;3) 使用人工标注的ground-truth标签作为基准;4) 训练监督分类模型,并将其标注结果与GPT-4的标注结果进行比较;5) 分析不同标注方法之间的差异,评估GPT-4的性能。
关键创新:该研究的关键创新在于提出了一个以人为本的评估框架,强调在自动标注流程中进行人工验证的重要性。通过对比LLMs的自动标注结果与人工标注的ground-truth标签,以及在人工标注数据上训练的监督模型的标注结果,可以更全面地评估LLMs的性能,并发现自动标注结果与人类判断之间的差异。
关键设计:该研究的关键设计包括:1) 选择密码保护数据集,避免数据污染;2) 使用GPT-4进行自动标注,并采用提示调优等优化策略;3) 使用人工标注的ground-truth标签作为基准,进行准确性评估;4) 训练监督分类模型,并将其标注结果与GPT-4的标注结果进行比较,评估泛化能力;5) 分析不同标注方法之间的差异,评估LLMs的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,GPT-4在自动标注任务中表现出较高的质量,但其性能在不同任务中存在显著差异,即使在同一数据集内也是如此。研究发现,尽管采用了提示调优等优化策略,自动标注在许多情况下与人类判断存在显著差异。这些结果强调了人工验证在自动标注流程中的重要性。
🎯 应用场景
该研究成果可应用于社交媒体舆情分析、虚假信息检测、网络暴力识别等领域。通过结合LLMs的自动标注能力和人工验证,可以提高标注效率和准确性,为社会科学研究提供更可靠的数据支持。未来,该框架可推广到其他文本标注任务,并促进人机协作的标注模式发展。
📄 摘要(原文)
Automated text annotation is a compelling use case for generative large language models (LLMs) in social media research. Recent work suggests that LLMs can achieve strong performance on annotation tasks; however, these studies evaluate LLMs on a small number of tasks and likely suffer from contamination due to a reliance on public benchmark datasets. Here, we test a human-centered framework for responsibly evaluating artificial intelligence tools used in automated annotation. We use GPT-4 to replicate 27 annotation tasks across 11 password-protected datasets from recently published computational social science articles in high-impact journals. For each task, we compare GPT-4 annotations against human-annotated ground-truth labels and against annotations from separate supervised classification models fine-tuned on human-generated labels. Although the quality of LLM labels is generally high, we find significant variation in LLM performance across tasks, even within datasets. Our findings underscore the importance of a human-centered workflow and careful evaluation standards: Automated annotations significantly diverge from human judgment in numerous scenarios, despite various optimization strategies such as prompt tuning. Grounding automated annotation in validation labels generated by humans is essential for responsible evaluation.