NovAScore: A New Automated Metric for Evaluating Document Level Novelty
作者: Lin Ai, Ziwei Gong, Harshsaiprasad Deshpande, Alexander Johnson, Emmy Phung, Ahmad Emami, Julia Hirschberg
分类: cs.CL
发布日期: 2024-09-14 (更新: 2024-09-18)
💡 一句话要点
提出NovAScore,一种自动化的文档级新颖性评估指标。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 新颖性检测 自动化评估 文档级别 原子信息 动态权重
📋 核心要点
- 现有新颖性检测方法依赖人工标注,成本高昂且难以扩展到大规模文档比较。
- NovAScore通过聚合原子信息的新颖性和显著性得分,实现文档级新颖性的自动评估。
- 实验表明NovAScore与人类判断高度相关,在两个数据集上均取得了显著的性能。
📝 摘要(中文)
在线内容的快速增长加剧了信息冗余问题,因此需要能够识别真正新信息的解决方案。尽管存在这一挑战,但研究界对新颖性检测的关注有所下降,尤其是在大型语言模型(LLM)兴起之后。此外,以往的方法严重依赖人工标注,这既耗时又昂贵,而且当标注者必须将目标文档与大量历史文档进行比较时,尤其具有挑战性。在这项工作中,我们介绍 NovAScore(原子性评分中的新颖性评估),这是一种用于评估文档级新颖性的自动化指标。NovAScore 聚合原子信息的新颖性和显着性得分,从而提供高度的可解释性和对文档新颖性的详细分析。凭借其动态权重调整方案,NovAScore 提供了增强的灵活性和额外的维度,以评估文档中的新颖性水平和信息的重要性。我们的实验表明,NovAScore 与人类对新颖性的判断高度相关,在 TAP-DLND 1.0 数据集上实现了 0.626 的 Point-Biserial 相关性,在内部人工标注的数据集上实现了 0.920 的 Pearson 相关性。
🔬 方法详解
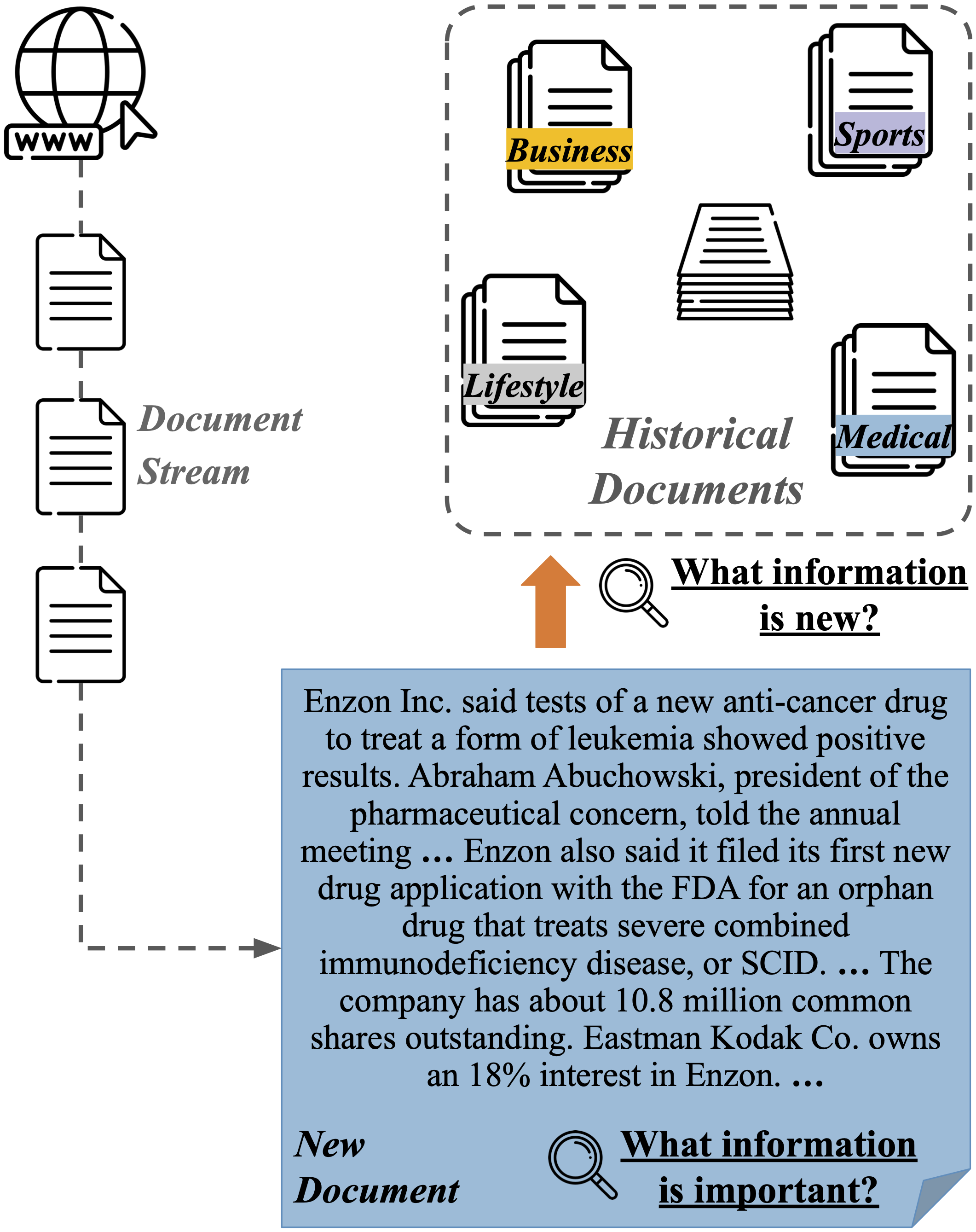
问题定义:论文旨在解决文档级别的新颖性评估问题。现有方法主要依赖于人工标注,这使得评估过程耗时、成本高昂,并且难以扩展到大规模文档的评估。此外,标注者需要将目标文档与大量的历史文档进行比较,进一步增加了标注的难度。因此,需要一种自动化的、可解释的、且能够有效评估文档新颖性的方法。
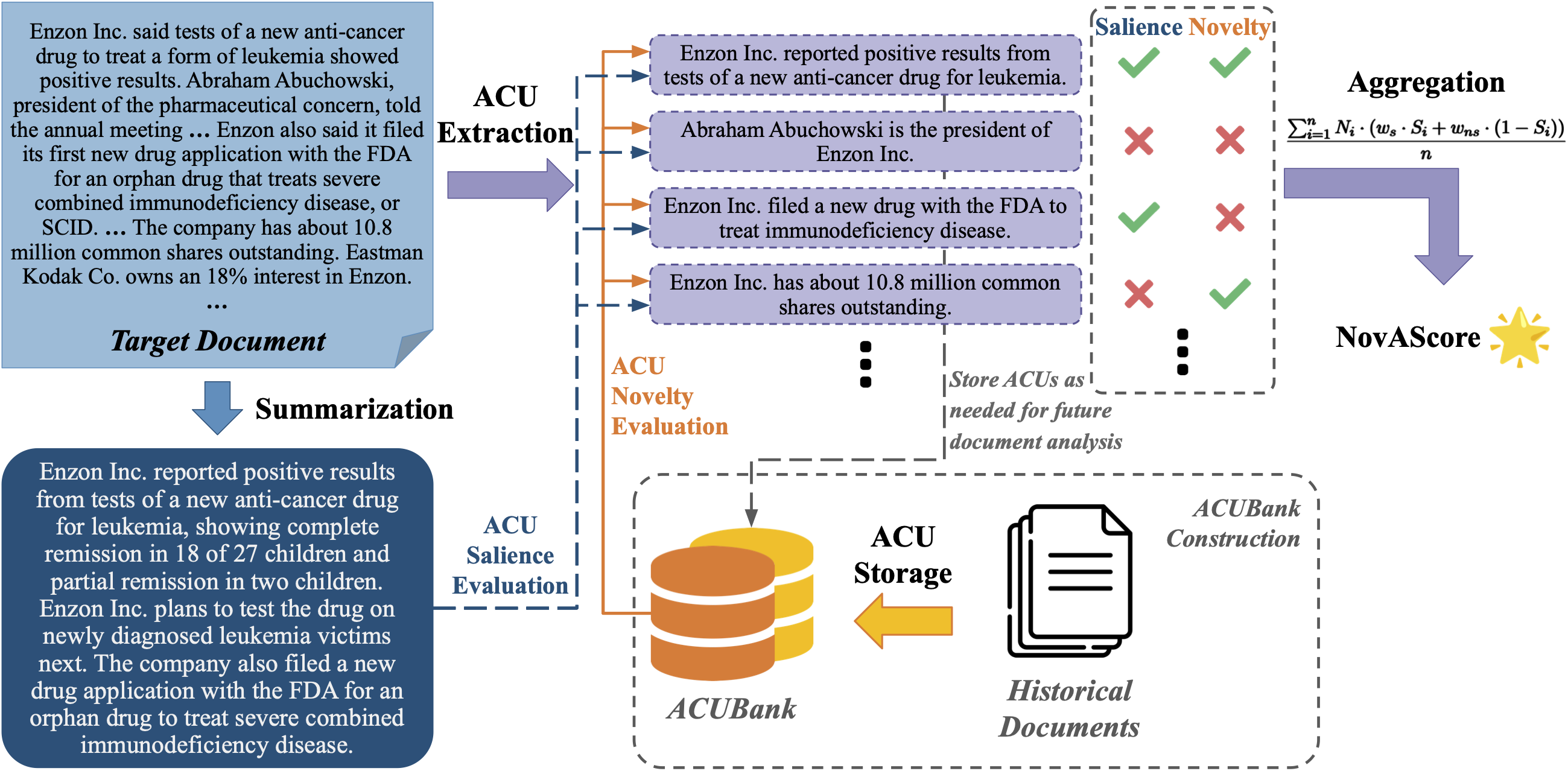
核心思路:NovAScore的核心思路是将文档分解为更小的“原子信息”单元,然后分别评估每个原子信息的新颖性和显著性,最后将这些得分聚合起来,得到整个文档的新颖性得分。通过这种方式,NovAScore不仅可以评估文档的新颖性,还可以提供关于文档中哪些信息是新的,以及这些信息的重要程度的详细分析。
技术框架:NovAScore的整体框架包括以下几个主要步骤:1. 文档分割:将文档分割成原子信息单元。具体如何分割论文中未明确说明,未知。2. 新颖性评估:评估每个原子信息单元的新颖性。具体方法未知。3. 显著性评估:评估每个原子信息单元的显著性。具体方法未知。4. 动态权重调整:根据原子信息单元的新颖性和显著性,动态调整其权重。5. 得分聚合:将所有原子信息单元的加权得分聚合起来,得到整个文档的新颖性得分。
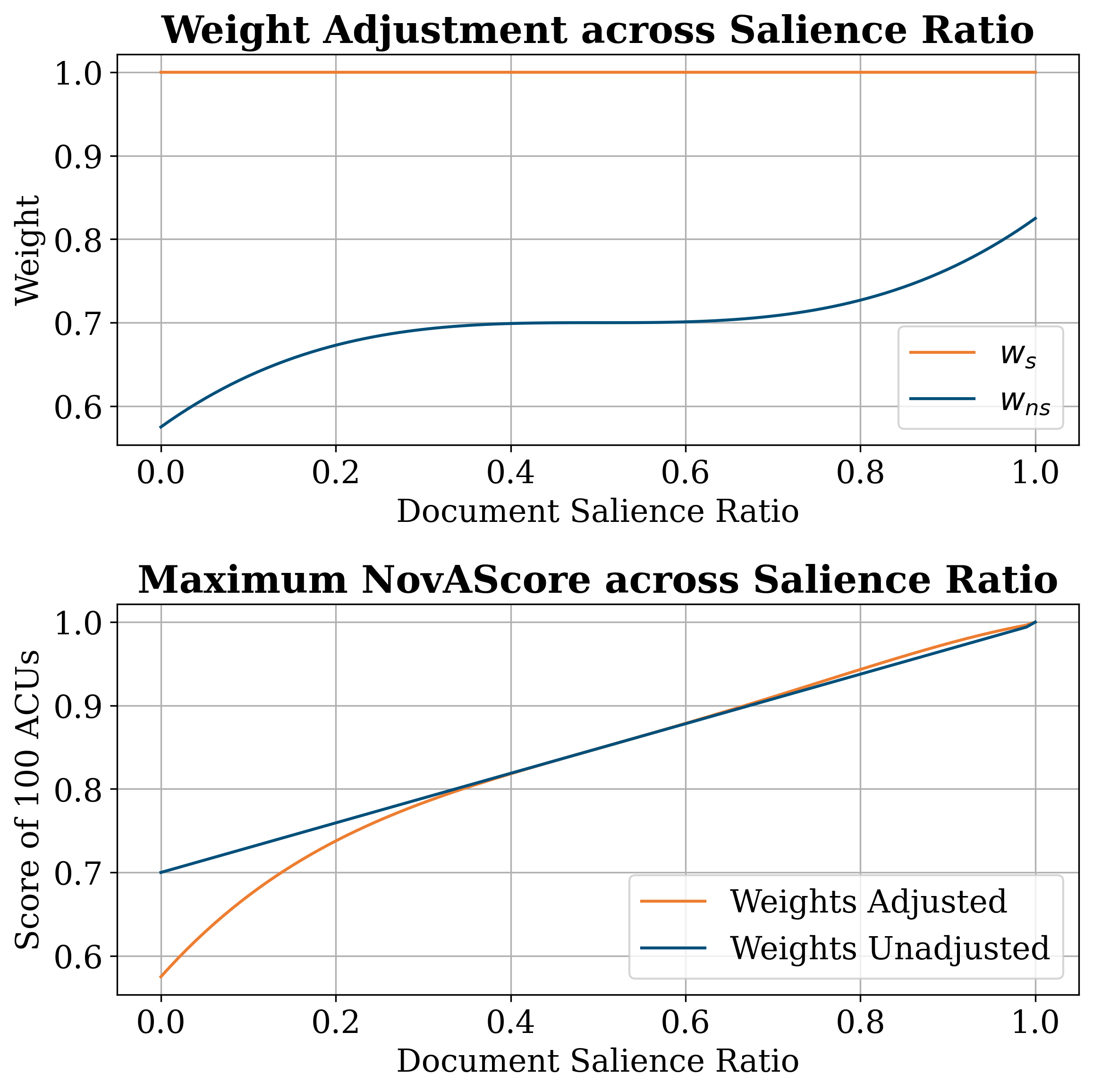
关键创新:NovAScore的关键创新在于其原子化的评估方法和动态权重调整方案。通过将文档分解为更小的单元进行评估,NovAScore可以提供更细粒度的分析结果,并且可以更好地捕捉文档中的新颖性信息。动态权重调整方案则允许NovAScore根据原子信息单元的新颖性和显著性,灵活地调整其在最终得分中的贡献,从而提高评估的准确性。
关键设计:论文中没有提供关于原子信息单元如何定义、新颖性和显著性如何评估、以及动态权重调整方案的具体技术细节。这些是需要进一步研究和探索的地方。具体参数设置、损失函数、网络结构等技术细节未知。
🖼️ 关键图片
📊 实验亮点
NovAScore在TAP-DLND 1.0数据集上实现了0.626的Point-Biserial相关性,在内部人工标注的数据集上实现了0.920的Pearson相关性。这些结果表明,NovAScore与人类对新颖性的判断高度相关,能够有效地评估文档的新颖性。
🎯 应用场景
NovAScore可应用于信息检索、新闻推荐、科研文献分析等领域。它可以帮助用户快速识别包含新信息的文档,过滤掉冗余信息,提高信息获取效率。在科研领域,NovAScore可以辅助研究人员发现新的研究方向和突破点,促进学术创新。
📄 摘要(原文)
The rapid expansion of online content has intensified the issue of information redundancy, underscoring the need for solutions that can identify genuinely new information. Despite this challenge, the research community has seen a decline in focus on novelty detection, particularly with the rise of large language models (LLMs). Additionally, previous approaches have relied heavily on human annotation, which is time-consuming, costly, and particularly challenging when annotators must compare a target document against a vast number of historical documents. In this work, we introduce NovAScore (Novelty Evaluation in Atomicity Score), an automated metric for evaluating document-level novelty. NovAScore aggregates the novelty and salience scores of atomic information, providing high interpretability and a detailed analysis of a document's novelty. With its dynamic weight adjustment scheme, NovAScore offers enhanced flexibility and an additional dimension to assess both the novelty level and the importance of information within a document. Our experiments show that NovAScore strongly correlates with human judgments of novelty, achieving a 0.626 Point-Biserial correlation on the TAP-DLND 1.0 dataset and a 0.920 Pearson correlation on an internal human-annotated dataset.