AIPO: Improving Training Objective for Iterative Preference Optimization
作者: Yaojie Shen, Xinyao Wang, Yulei Niu, Ying Zhou, Lexin Tang, Libo Zhang, Fan Chen, Longyin Wen
分类: cs.CL
发布日期: 2024-09-13
🔗 代码/项目: GITHUB
💡 一句话要点
提出AIPO,通过改进训练目标解决迭代偏好优化中的长度利用问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 偏好优化 大型语言模型 迭代训练 长度利用 对齐 AIPO 合成数据 奖励模型
📋 核心要点
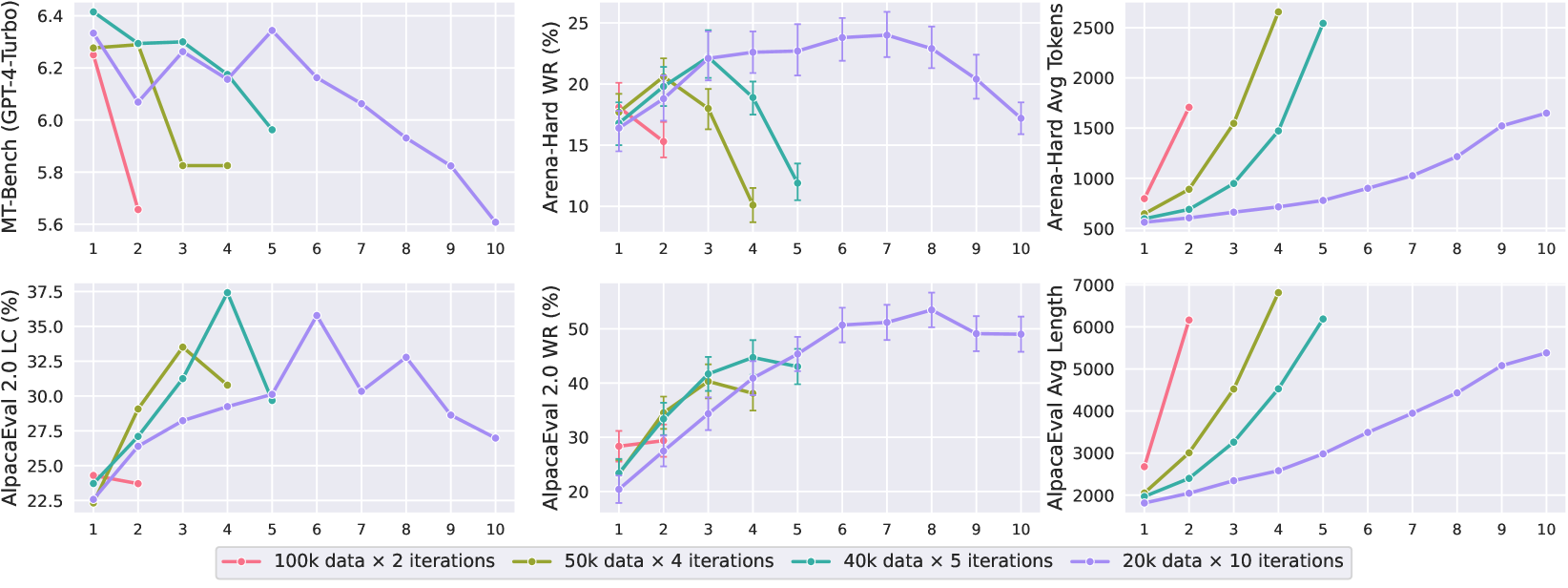
- 迭代偏好优化(IPO)在对齐LLM时面临长度利用问题,导致模型倾向于生成过长但质量不高的回复。
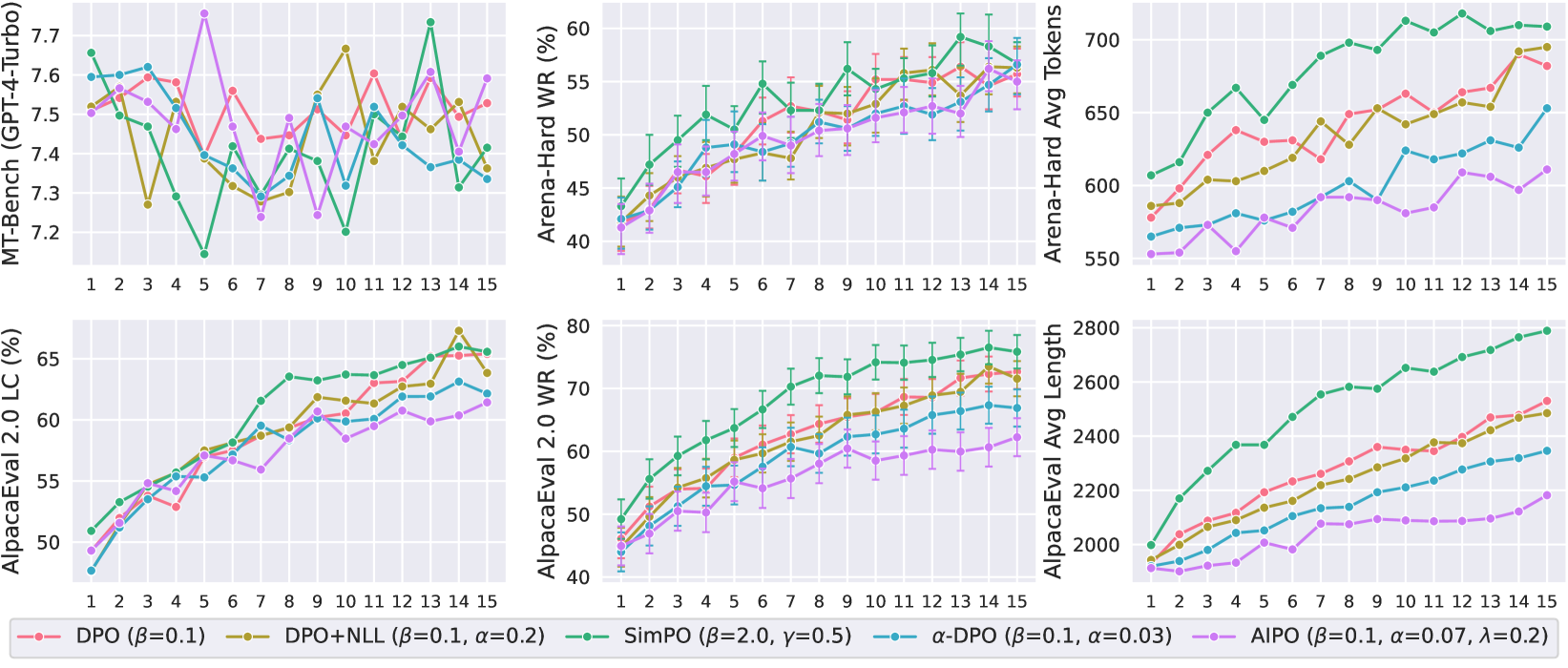
- 提出Agreement-aware Iterative Preference Optimization (AIPO),通过改进训练目标来缓解IPO中的长度利用问题。
- 实验表明,AIPO在MT-Bench、AlpacaEval 2.0和Arena-Hard等基准测试中取得了SOTA性能,验证了其有效性。
📝 摘要(中文)
偏好优化(PO)作为近端策略优化(PPO)的替代方案,在对齐大型语言模型(LLMs)方面越来越受欢迎。最近关于使用合成或部分合成数据迭代对齐LLMs的研究表明,在学术环境和专有训练模型(如Llama3)中扩展PO训练具有良好的前景。尽管如此,我们的研究表明,由于迭代过程的性质,PO中存在的长度利用问题在迭代偏好优化(IPO)中更加严重。在这项工作中,我们研究了使用合成数据的迭代偏好优化。我们分享了构建迭代偏好优化管道过程中的发现和分析。更具体地说,我们讨论了迭代偏好优化期间的长度利用问题,并提出了我们的迭代偏好优化训练目标,即Agreement-aware Iterative Preference Optimization (AIPO)。为了证明我们方法的有效性,我们进行了全面的实验,并在MT-Bench、AlpacaEval 2.0和Arena-Hard上取得了最先进的性能。我们的实现和模型检查点将在https://github.com/bytedance/AIPO上提供。
🔬 方法详解
问题定义:论文旨在解决迭代偏好优化(IPO)中存在的长度利用问题。现有的偏好优化方法,尤其是迭代式的偏好优化,容易使模型过度生成长文本,而这些长文本的质量可能并不高,从而影响模型的整体性能。这种现象在迭代训练过程中会被放大。
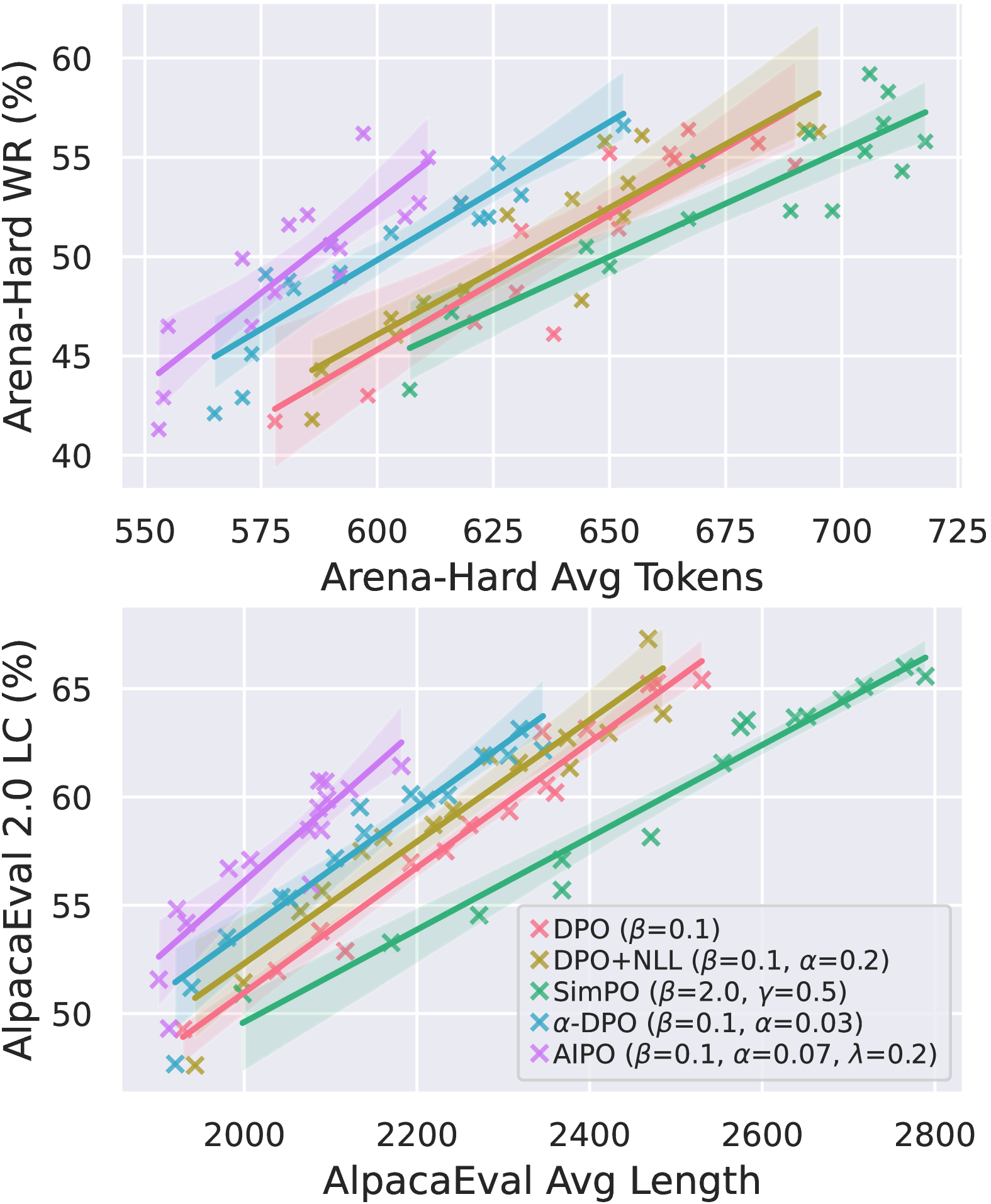
核心思路:AIPO的核心思路是引入一个协议感知(Agreement-aware)的训练目标,该目标能够衡量模型生成文本与人类偏好之间的对齐程度,并惩罚那些仅仅通过增加文本长度来迎合偏好的行为。通过这种方式,AIPO鼓励模型生成更简洁、更符合人类偏好的文本。
技术框架:AIPO的整体框架仍然基于迭代偏好优化,但在训练目标上进行了改进。具体来说,它包括以下几个主要阶段:1) 使用合成数据或部分合成数据进行初始偏好模型的训练;2) 使用偏好模型生成回复,并根据人类反馈或奖励信号进行排序;3) 使用AIPO训练目标更新偏好模型,该目标考虑了模型生成文本与人类偏好之间的协议程度;4) 迭代上述过程,不断优化偏好模型。
关键创新:AIPO的关键创新在于其Agreement-aware的训练目标。传统的偏好优化方法通常只关注模型生成文本的得分,而忽略了模型生成文本与人类偏好之间的对齐程度。AIPO通过引入一个额外的协议项,能够更准确地衡量模型的性能,并引导模型生成更符合人类偏好的文本。
关键设计:AIPO的关键设计在于协议项的定义和计算方式。具体来说,协议项可以定义为模型生成文本与人类偏好之间的相似度或一致性程度。可以使用各种方法来计算协议项,例如使用余弦相似度或交叉熵损失。此外,AIPO还可以调整协议项的权重,以控制其对训练过程的影响。
🖼️ 关键图片
📊 实验亮点
AIPO在MT-Bench、AlpacaEval 2.0和Arena-Hard等基准测试中取得了SOTA性能。例如,在MT-Bench上,AIPO相较于现有方法取得了显著的提升。这些实验结果表明,AIPO能够有效地解决迭代偏好优化中的长度利用问题,并提高生成文本的质量。
🎯 应用场景
AIPO可应用于各种需要对齐大型语言模型的场景,例如对话系统、文本生成和问答系统。通过解决长度利用问题,AIPO可以提高生成文本的质量和相关性,从而提升用户体验。该研究对于开发更智能、更人性化的AI系统具有重要意义。
📄 摘要(原文)
Preference Optimization (PO), is gaining popularity as an alternative choice of Proximal Policy Optimization (PPO) for aligning Large Language Models (LLMs). Recent research on aligning LLMs iteratively with synthetic or partially synthetic data shows promising results in scaling up PO training for both academic settings and proprietary trained models such as Llama3. Despite its success, our study shows that the length exploitation issue present in PO is even more severe in Iterative Preference Optimization (IPO) due to the iterative nature of the process. In this work, we study iterative preference optimization with synthetic data. We share the findings and analysis along the way of building the iterative preference optimization pipeline. More specifically, we discuss the length exploitation issue during iterative preference optimization and propose our training objective for iterative preference optimization, namely Agreement-aware Iterative Preference Optimization (AIPO). To demonstrate the effectiveness of our method, we conduct comprehensive experiments and achieve state-of-the-art performance on MT-Bench, AlpacaEval 2.0, and Arena-Hard. Our implementation and model checkpoints will be made available at https://github.com/bytedance/AIPO.