When Context Leads but Parametric Memory Follows in Large Language Models
作者: Yufei Tao, Adam Hiatt, Erik Haake, Antonie J. Jetter, Ameeta Agrawal
分类: cs.CL, cs.AI
发布日期: 2024-09-13 (更新: 2024-11-21)
备注: Accepted by EMNLP 2024 Main Conference
💡 一句话要点
研究大型语言模型在知识一致场景下上下文与参数记忆的知识分配策略
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 知识分配 上下文学习 参数记忆 幻觉现象
📋 核心要点
- 大型语言模型在利用多样化知识源方面取得了显著进展,但其知识来源分配机制尚不明确。
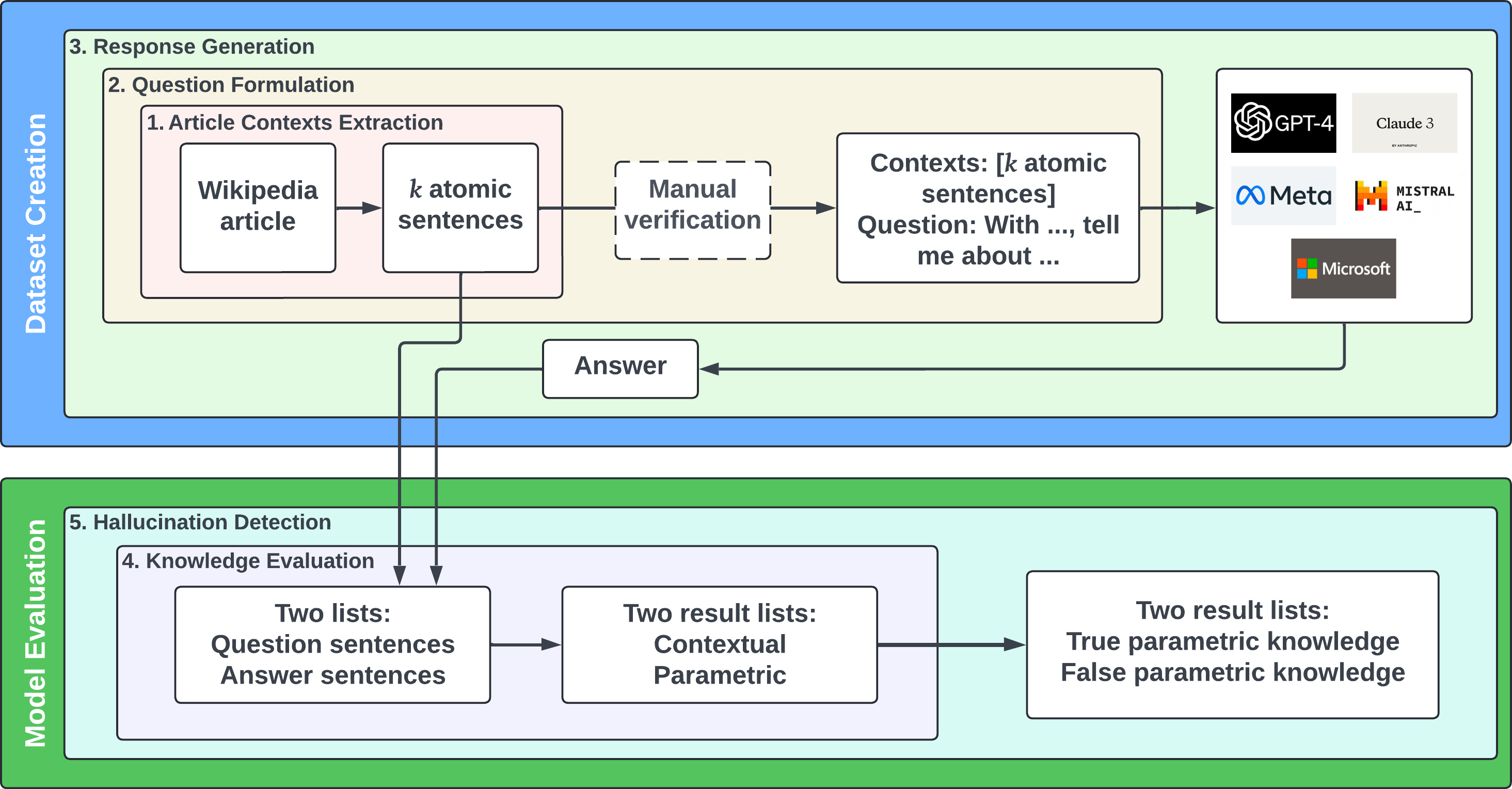
- 论文通过构建WikiAtomic数据集,系统地分析了LLM在知识一致场景下对上下文和参数知识的依赖程度。
- 实验结果表明,LLM同时依赖上下文和参数知识,且增加上下文可以减少幻觉现象。
📝 摘要(中文)
本研究探讨了九个广泛使用的大型语言模型(LLM)在知识一致场景中回答开放性问题时,如何在局部上下文和全局参数之间分配知识。我们引入了一个名为WikiAtomic的新数据集,并通过系统地改变上下文大小,分析了LLM在知识一致场景中如何优先利用所提供的信息和它们的参数知识。此外,我们还研究了它们在不同上下文大小下产生幻觉的倾向。我们的发现揭示了模型之间的一致模式,包括对上下文知识(约70%)和参数知识(约30%)的一致依赖,以及随着上下文增加幻觉的减少。这些见解突出了更有效的上下文组织以及开发更确定性地使用输入的模型以实现稳健性能的重要性。
🔬 方法详解
问题定义:现有大型语言模型在处理知识密集型任务时,如何有效利用上下文信息和自身参数中存储的知识是一个关键问题。现有方法缺乏对这两种知识来源的细致分析,难以理解模型决策过程,并且模型容易产生幻觉。
核心思路:本研究的核心思路是通过构建一个可控的知识一致性测试环境,系统性地改变输入上下文的大小,观察LLM对上下文知识和参数知识的依赖程度,以及幻觉现象的变化。通过这种方式,揭示LLM的知识分配策略。
技术框架:该研究主要包含以下几个阶段:1) 构建WikiAtomic数据集,该数据集包含一系列知识一致的开放性问题。2) 选择九个广泛使用的大型语言模型进行测试。3) 系统性地改变输入上下文的大小。4) 分析模型对上下文知识和参数知识的依赖程度,以及幻觉现象的变化。5) 对实验结果进行统计分析,总结模型之间的共性与差异。
关键创新:本研究的关键创新在于:1) 提出了WikiAtomic数据集,该数据集专门用于评估LLM在知识一致场景下的知识分配策略。2) 系统性地分析了LLM对上下文知识和参数知识的依赖程度,以及幻觉现象的变化,揭示了模型内部的知识分配机制。3) 发现了LLM在知识一致场景下对上下文知识和参数知识的依赖比例,以及增加上下文可以减少幻觉的现象。
关键设计:WikiAtomic数据集的设计保证了问题答案既可以从提供的上下文中获取,也可以从模型的参数知识中获取。实验中,通过控制上下文的大小,观察模型生成答案的来源。幻觉现象的评估通过人工评估或自动评估方法进行。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM在知识一致场景下,大约70%的知识来源于上下文,30%来源于参数知识。此外,随着上下文大小的增加,LLM产生幻觉的倾向明显降低。这些发现为优化LLM的知识利用策略提供了重要依据。
🎯 应用场景
该研究成果可应用于提升大型语言模型在知识密集型任务中的性能,例如问答系统、知识图谱推理等。通过优化上下文组织方式,并鼓励模型更确定性地利用输入信息,可以提高模型的准确性和可靠性,减少幻觉现象,从而提升用户体验。
📄 摘要(原文)
Large language models (LLMs) have demonstrated remarkable progress in leveraging diverse knowledge sources. This study investigates how nine widely used LLMs allocate knowledge between local context and global parameters when answering open-ended questions in knowledge-consistent scenarios. We introduce a novel dataset, WikiAtomic, and systematically vary context sizes to analyze how LLMs prioritize and utilize the provided information and their parametric knowledge in knowledge-consistent scenarios. Additionally, we also study their tendency to hallucinate under varying context sizes. Our findings reveal consistent patterns across models, including a consistent reliance on both contextual (around 70%) and parametric (around 30%) knowledge, and a decrease in hallucinations with increasing context. These insights highlight the importance of more effective context organization and developing models that use input more deterministically for robust performance.