Knowledge Tagging with Large Language Model based Multi-Agent System
作者: Hang Li, Tianlong Xu, Ethan Chang, Qingsong Wen
分类: cs.CL, cs.AI
发布日期: 2024-09-12 (更新: 2024-12-19)
备注: Accepted by AAAI 2025 (AAAI/IAAI 2025 Innovative Application Award)
💡 一句话要点
提出基于大语言模型的多智能体系统,用于自动化知识点标注。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识点标注 大语言模型 多智能体系统 智能教育 自然语言处理
📋 核心要点
- 现有知识点标注方法难以处理复杂知识定义和数值约束问题,标注质量受限。
- 提出基于大语言模型的多智能体系统,模拟专家标注过程,提升标注准确性。
- 实验表明,该系统在MathKnowCT数据集上表现优异,验证了其在教育领域的潜力。
📝 摘要(中文)
针对问题进行知识点标注在现代智能教育应用中至关重要,包括学习进度诊断、练习题推荐和课程内容组织。传统上,这些标注由教学专家完成,因为该任务不仅需要对问题干和知识定义有深刻的语义理解,还需要将解决问题的逻辑与相关知识概念联系起来的强大能力。随着预训练语言模型和大语言模型(LLM)等先进自然语言处理(NLP)算法的出现,开创性的研究已经探索了使用各种机器学习模型来自动化知识点标注过程。在本文中,我们研究了使用多智能体系统来解决先前算法的局限性,特别是在处理涉及复杂知识定义和严格数值约束的复杂案例时。通过展示其在公开的数学问题知识点标注数据集MathKnowCT上的卓越性能,我们强调了基于LLM的多智能体系统在克服先前方法遇到的挑战方面的巨大潜力。最后,通过深入讨论自动化知识点标注的意义,我们强调了在教育环境中部署基于LLM的算法的有希望的结果。
🔬 方法详解
问题定义:论文旨在解决自动化知识点标注问题,即为给定的问题自动标注其所涉及的知识点。现有方法,特别是基于传统机器学习模型的方法,在处理复杂问题(例如,涉及复杂的知识定义和严格的数值约束)时表现不佳,需要人工干预,成本高昂。
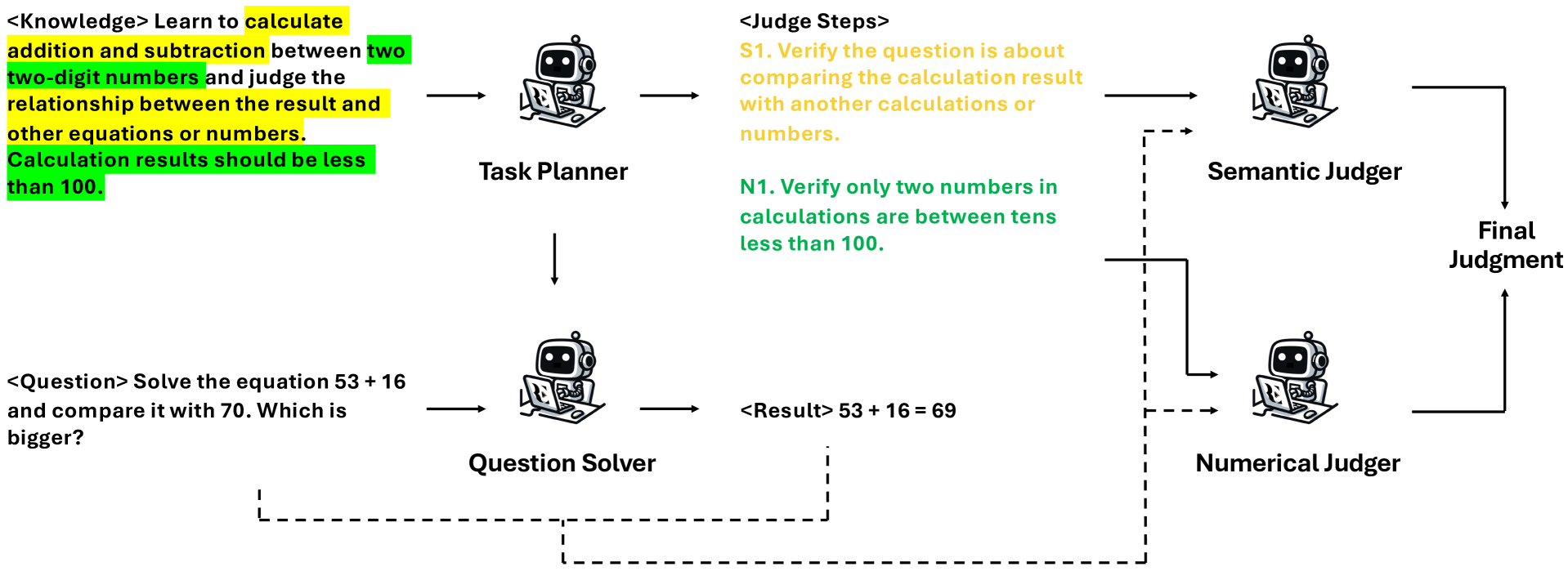
核心思路:论文的核心思路是利用大语言模型(LLM)的强大语义理解和推理能力,构建一个多智能体系统,模拟人类专家进行知识点标注的过程。每个智能体负责不同的任务,协同工作,从而提高标注的准确性和效率。
技术框架:该多智能体系统包含多个智能体,每个智能体负责不同的子任务。具体流程可能包括:问题理解智能体(负责理解问题干的语义)、知识检索智能体(负责检索相关的知识点定义)、推理智能体(负责将问题与知识点进行匹配和推理)、以及验证智能体(负责验证标注结果的正确性)。这些智能体之间通过消息传递和协作,最终确定问题的知识点标签。
关键创新:该方法的核心创新在于将大语言模型应用于多智能体系统,从而实现了更智能、更高效的知识点标注。与传统的单模型方法相比,多智能体系统能够更好地模拟人类专家的思维过程,处理更复杂的问题。
关键设计:论文可能涉及以下关键设计:1) 如何设计每个智能体的角色和功能;2) 如何定义智能体之间的通信协议和协作机制;3) 如何利用大语言模型进行知识检索、推理和验证;4) 如何训练和优化多智能体系统,例如,使用强化学习或监督学习方法。
🖼️ 关键图片

📊 实验亮点
论文在公开的数学问题知识点标注数据集MathKnowCT上进行了实验,结果表明,基于LLM的多智能体系统显著优于现有的知识点标注方法。具体的性能数据(例如,准确率、召回率、F1值)以及与基线方法的对比结果需要在论文中查找。该研究验证了LLM在教育领域的巨大潜力。
🎯 应用场景
该研究成果可广泛应用于智能教育领域,例如,自动学习进度诊断、个性化练习题推荐、智能课程内容组织等。通过自动化知识点标注,可以降低教育成本,提高教学效率,并为学生提供更个性化的学习体验。未来,该技术还可以应用于其他需要知识点标注的领域,例如,医学、法律等。
📄 摘要(原文)
Knowledge tagging for questions is vital in modern intelligent educational applications, including learning progress diagnosis, practice question recommendations, and course content organization. Traditionally, these annotations have been performed by pedagogical experts, as the task demands not only a deep semantic understanding of question stems and knowledge definitions but also a strong ability to link problem-solving logic with relevant knowledge concepts. With the advent of advanced natural language processing (NLP) algorithms, such as pre-trained language models and large language models (LLMs), pioneering studies have explored automating the knowledge tagging process using various machine learning models. In this paper, we investigate the use of a multi-agent system to address the limitations of previous algorithms, particularly in handling complex cases involving intricate knowledge definitions and strict numerical constraints. By demonstrating its superior performance on the publicly available math question knowledge tagging dataset, MathKnowCT, we highlight the significant potential of an LLM-based multi-agent system in overcoming the challenges that previous methods have encountered. Finally, through an in-depth discussion of the implications of automating knowledge tagging, we underscore the promising results of deploying LLM-based algorithms in educational contexts.