Real or Robotic? Assessing Whether LLMs Accurately Simulate Qualities of Human Responses in Dialogue
作者: Jonathan Ivey, Shivani Kumar, Jiayu Liu, Hua Shen, Sushrita Rakshit, Rohan Raju, Haotian Zhang, Aparna Ananthasubramaniam, Junghwan Kim, Bowen Yi, Dustin Wright, Abraham Israeli, Anders Giovanni Møller, Lechen Zhang, David Jurgens
分类: cs.CL, cs.CY, cs.HC
发布日期: 2024-09-12 (更新: 2024-09-16)
💡 一句话要点
评估LLM在对话中模拟人类反应的准确性,揭示其与真实对话的差异
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对话模拟 人机交互 真实性评估 文本属性分析
📋 核心要点
- 对话数据集构建成本高昂,现有方法依赖LLM模拟,但其真实性有待考量。
- 通过大规模对比LLM模拟对话与真实人机对话,评估LLM模拟的准确性。
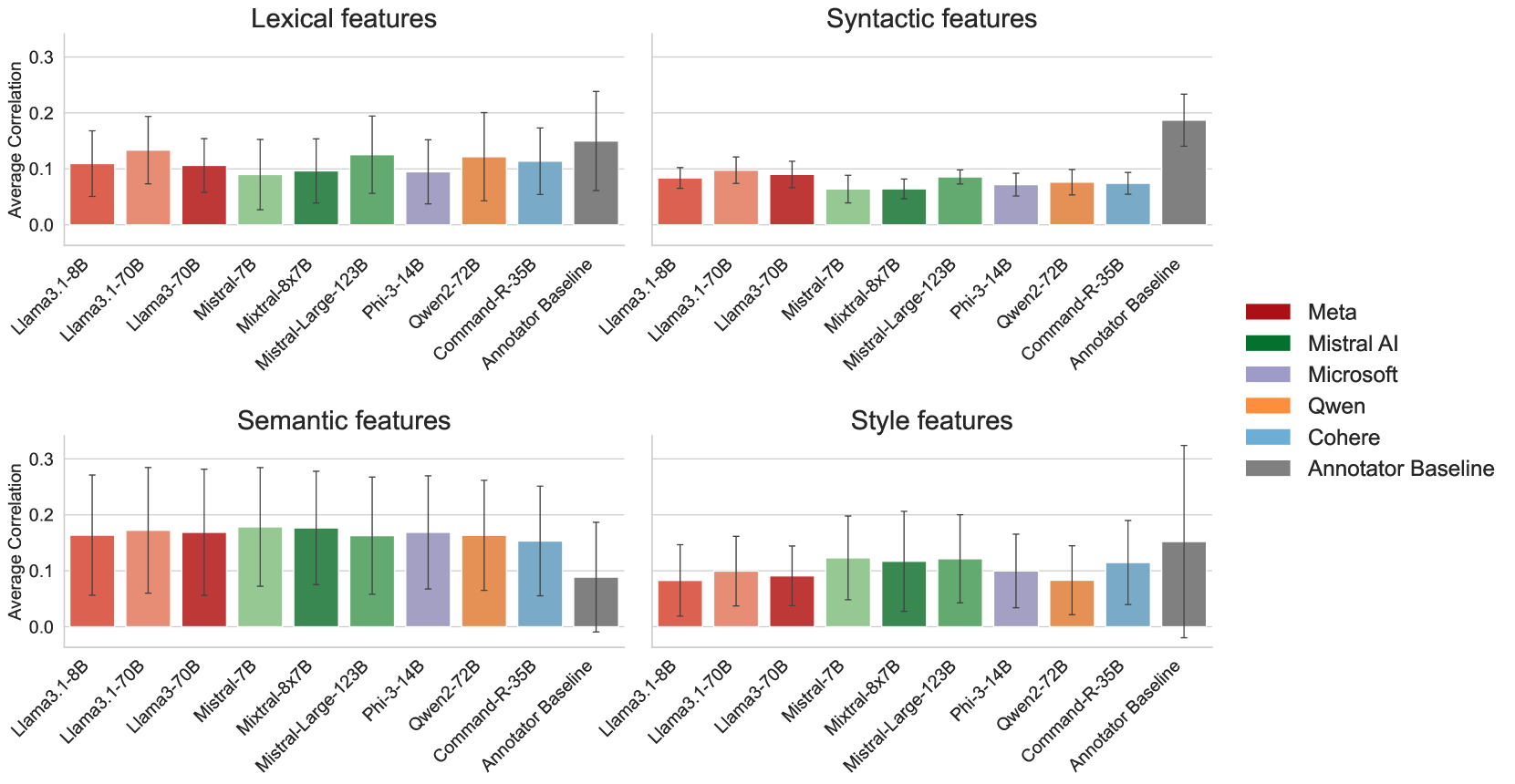
- 研究发现LLM模拟与真实对话存在显著差异,尤其在风格和内容上,且多语言模型表现相似。
📝 摘要(中文)
由于招募、培训和收集研究参与者的数据既昂贵又耗时,对话任务的数据集构建面临挑战。为了解决这个问题,最近的研究开始使用大型语言模型(LLM)来模拟人与人以及人与LLM的互动,因为它们在许多情况下都能生成令人信服的类人文本。然而,基于LLM的模拟在多大程度上 extit{真正}反映了人类对话?本文通过生成一个包含来自WildChat数据集的10万对LLM-LLM和人-LLM对话的大规模数据集,并量化LLM模拟与人类对话的对齐程度来回答这个问题。总体而言,我们发现模拟和人类互动之间的对齐程度相对较低,表明在包括风格和内容在内的多个文本属性上存在系统性差异。此外,在英语、中文和俄语对话的比较中,我们发现模型的表现相似。我们的结果表明,当人类以更类似于LLM自身风格的方式写作时,LLM通常表现更好。
🔬 方法详解
问题定义:现有对话数据集的构建依赖于人工收集,成本高昂且耗时。为了降低成本,研究者尝试使用大型语言模型(LLM)来模拟人与人或人与LLM的对话。然而,这种模拟的真实性,即LLM生成的对话在多大程度上能反映真实人类对话,是一个关键问题。现有方法缺乏对LLM模拟对话真实性的系统性评估。
核心思路:本研究的核心思路是通过大规模对比LLM生成的模拟对话和真实的人类对话,来评估LLM模拟的准确性。通过量化LLM模拟对话与真实对话在多个文本属性上的差异,揭示LLM模拟的局限性。研究假设LLM的风格和内容与人类存在差异,从而导致模拟对话的偏差。
技术框架:研究主要包含以下几个阶段: 1. 数据收集:从WildChat数据集中选取数据,构建大规模的LLM-LLM和人-LLM对话数据集,总共包含10万对对话。 2. 对话生成:使用LLM生成模拟对话,包括LLM-LLM对话和人-LLM对话。 3. 特征提取:从生成的对话和真实对话中提取多个文本属性特征,包括风格特征(如词汇多样性、句子长度)和内容特征(如主题分布、情感极性)。 4. 对比分析:对比LLM模拟对话和真实对话在这些特征上的差异,使用统计方法量化差异的显著性。 5. 多语言分析:在英语、中文和俄语三种语言上进行对比分析,评估LLM在不同语言环境下的模拟能力。
关键创新:本研究的关键创新在于对LLM模拟对话的真实性进行了大规模、系统性的评估。以往的研究主要关注LLM生成文本的流畅性和连贯性,而忽略了其与真实人类对话的差异。本研究通过量化LLM模拟对话与真实对话在多个文本属性上的差异,揭示了LLM模拟的局限性,为后续研究提供了重要的参考。
关键设计:研究使用了WildChat数据集,该数据集包含真实的人类对话。研究者使用了多种文本属性特征来量化LLM模拟对话和真实对话的差异,包括词汇多样性、句子长度、主题分布和情感极性等。研究者还使用了统计方法,如t检验和卡方检验,来评估差异的显著性。此外,研究者还在英语、中文和俄语三种语言上进行了对比分析,以评估LLM在不同语言环境下的模拟能力。
🖼️ 关键图片


📊 实验亮点
研究发现LLM模拟对话与真实对话在多个文本属性上存在显著差异,包括风格和内容。在英语、中文和俄语三种语言的对比中,LLM的表现相似,表明这种差异具有普遍性。研究还发现,当人类以更类似于LLM自身风格的方式写作时,LLM通常表现更好。这些结果表明,LLM在模拟人类对话方面仍存在局限性,需要进一步改进。
🎯 应用场景
该研究成果可应用于对话系统开发、人机交互设计和LLM评估等领域。通过了解LLM模拟对话的局限性,可以更好地利用LLM生成数据,并设计更真实、自然的对话系统。此外,该研究还可以帮助评估不同LLM的对话能力,为选择合适的LLM提供依据。未来的研究可以进一步探索如何提高LLM模拟对话的真实性,例如通过引入人类反馈或使用更复杂的模型结构。
📄 摘要(原文)
Studying and building datasets for dialogue tasks is both expensive and time-consuming due to the need to recruit, train, and collect data from study participants. In response, much recent work has sought to use large language models (LLMs) to simulate both human-human and human-LLM interactions, as they have been shown to generate convincingly human-like text in many settings. However, to what extent do LLM-based simulations \textit{actually} reflect human dialogues? In this work, we answer this question by generating a large-scale dataset of 100,000 paired LLM-LLM and human-LLM dialogues from the WildChat dataset and quantifying how well the LLM simulations align with their human counterparts. Overall, we find relatively low alignment between simulations and human interactions, demonstrating a systematic divergence along the multiple textual properties, including style and content. Further, in comparisons of English, Chinese, and Russian dialogues, we find that models perform similarly. Our results suggest that LLMs generally perform better when the human themself writes in a way that is more similar to the LLM's own style.