Fine-tuning Large Language Models for Entity Matching
作者: Aaron Steiner, Ralph Peeters, Christian Bizer
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-09-12 (更新: 2025-05-21)
备注: 8 pages, 4 figures. For related code and data, see this https://github.com/wbsg-uni-mannheim/TailorMatch
💡 一句话要点
通过微调大型语言模型提升实体匹配性能并研究其泛化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 实体匹配 大型语言模型 微调 泛化能力 训练样本表示
📋 核心要点
- 现有实体匹配方法依赖于提示工程和上下文学习,缺乏对LLM微调的深入研究,限制了模型性能的进一步提升。
- 本文探索了通过微调LLM来提升实体匹配性能的方法,重点关注训练样本表示和训练样本选择/生成两个维度。
- 实验结果表明,微调能显著提升较小模型的性能,并改善领域内泛化能力,但可能损害跨领域迁移能力。
📝 摘要(中文)
本文探讨了微调大型语言模型(LLMs)在实体匹配任务中的潜力,作为预训练语言模型的一个有前景的替代方案,因为LLMs具有较高的零样本性能和泛化到未见实体的能力。现有研究主要集中在提示工程和上下文学习上。本文从两个维度分析了微调:1)训练样本的表示,实验中向训练集添加不同类型的LLM生成的解释;2)使用LLM选择和生成训练样本。除了源数据集上的匹配性能外,我们还研究了微调如何影响模型泛化到其他领域内数据集以及跨主题领域的能力。实验表明,微调显著提高了较小模型的性能,而较大模型的结果好坏参半。微调还提高了对领域内数据集的泛化能力,但损害了跨领域迁移。我们发现,向训练集添加结构化解释对四个LLM中的三个产生了积极影响,而所提出的示例选择和生成方法仅提高了Llama 3.1 8B的性能,同时降低了GPT-4o-mini的性能。
🔬 方法详解
问题定义:实体匹配旨在识别不同数据源中指向同一现实世界实体的记录。现有方法,如基于预训练语言模型的提示工程和上下文学习,虽然有效,但可能无法充分利用LLM的潜力。痛点在于缺乏针对特定实体匹配任务的微调策略,以及对微调后模型泛化能力的深入理解。
核心思路:本文的核心思路是通过微调LLM,使其更好地适应实体匹配任务。通过精心设计的训练数据表示和样本选择/生成策略,提升模型在目标数据集上的性能,并研究其在不同领域数据集上的泛化能力。这样设计的目的是为了克服现有方法中LLM利用不充分的问题,并探索更有效的实体匹配方法。
技术框架:本文的技术框架主要包括以下几个阶段:1)数据准备:构建包含实体对和标签的训练数据集。2)训练样本表示:实验不同的训练样本表示方法,包括添加LLM生成的解释。3)训练样本选择/生成:利用LLM选择或生成更有价值的训练样本。4)模型微调:使用准备好的训练数据微调LLM。5)性能评估:在源数据集、领域内数据集和跨领域数据集上评估微调后模型的性能。
关键创新:本文的关键创新在于:1)系统地研究了微调LLM在实体匹配任务中的潜力。2)探索了不同的训练样本表示方法,特别是添加LLM生成的解释。3)提出了基于LLM的训练样本选择和生成方法。4)深入分析了微调对模型泛化能力的影响。
关键设计:在训练样本表示方面,本文实验了添加不同类型的LLM生成的解释,例如实体描述或匹配原因。在训练样本选择/生成方面,本文利用LLM选择信息量大的样本或生成新的样本。具体参数设置和损失函数等细节未在摘要中详细说明,需要参考原文。
🖼️ 关键图片
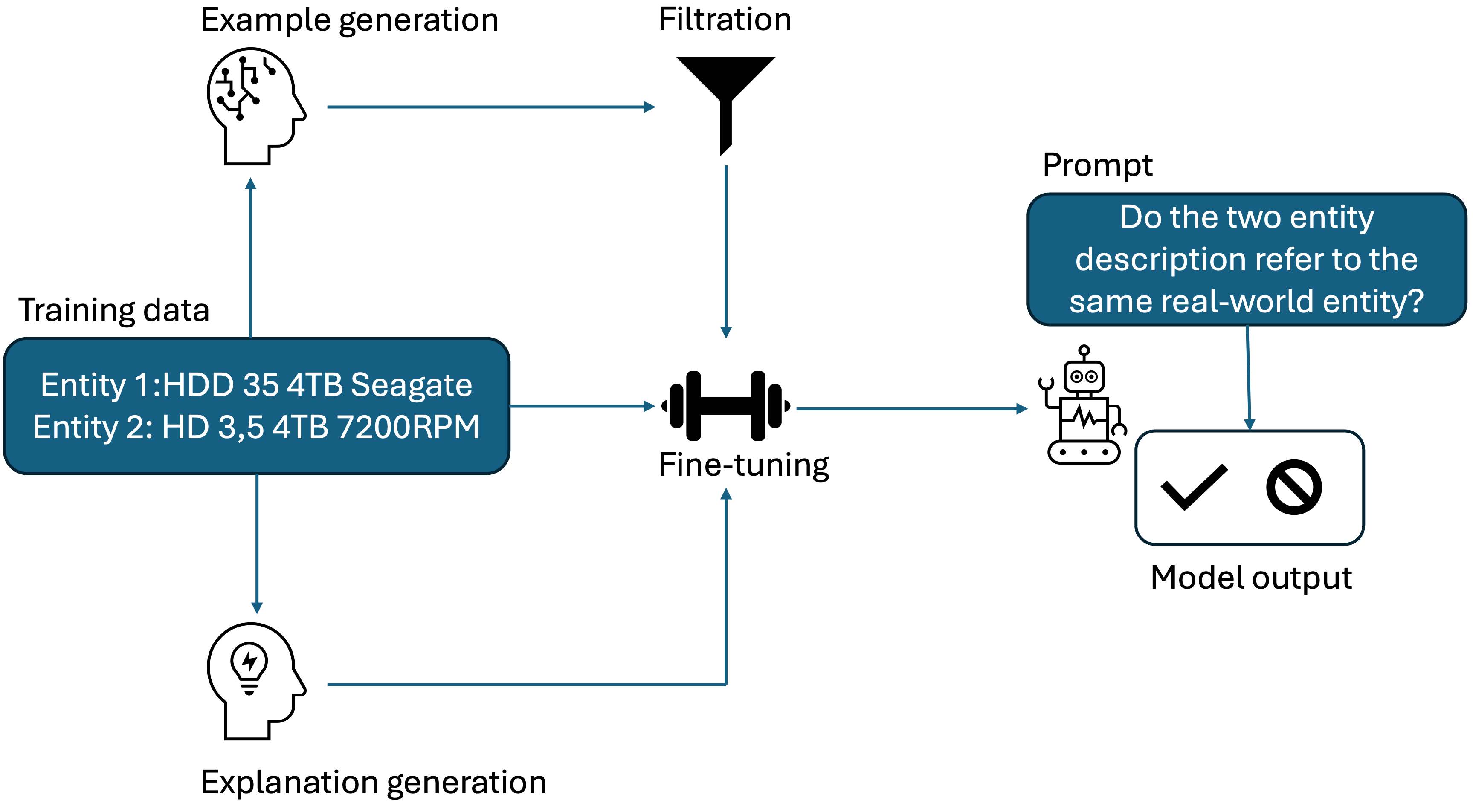


📊 实验亮点
实验结果表明,微调显著提高了较小模型的性能,而较大模型的结果好坏参半。添加结构化解释对四个LLM中的三个产生了积极影响。所提出的示例选择和生成方法仅提高了Llama 3.1 8B的性能,同时降低了GPT-4o-mini的性能。微调还提高了对领域内数据集的泛化能力,但损害了跨领域迁移。
🎯 应用场景
该研究成果可应用于数据集成、知识图谱构建、客户关系管理等领域。通过提升实体匹配的准确性和效率,可以改善数据质量,提高决策效率,并为用户提供更准确的信息。未来,该方法有望应用于更大规模、更复杂的数据集,并与其他技术相结合,实现更智能化的数据管理。
📄 摘要(原文)
Generative large language models (LLMs) are a promising alternative to pre-trained language models for entity matching due to their high zero-shot performance and ability to generalize to unseen entities. Existing research on using LLMs for entity matching has focused on prompt engineering and in-context learning. This paper explores the potential of fine-tuning LLMs for entity matching. We analyze fine-tuning along two dimensions: 1) the representation of training examples, where we experiment with adding different types of LLM-generated explanations to the training set, and 2) the selection and generation of training examples using LLMs. In addition to the matching performance on the source dataset, we investigate how fine-tuning affects the models ability to generalize to other in-domain datasets as well as across topical domains. Our experiments show that fine-tuning significantly improves the performance of the smaller models while the results for the larger models are mixed. Fine-tuning also improves the generalization to in-domain datasets while hurting cross-domain transfer. We show that adding structured explanations to the training set has a positive impact on the performance of three out of four LLMs, while the proposed example selection and generation methods, only improve the performance of Llama 3.1 8B while decreasing the performance of GPT-4o-mini.