Full-text Error Correction for Chinese Speech Recognition with Large Language Model
作者: Zhiyuan Tang, Dong Wang, Shen Huang, Shidong Shang
分类: cs.CL, eess.AS
发布日期: 2024-09-12 (更新: 2024-12-23)
备注: ICASSP 2025
💡 一句话要点
提出ChFT数据集并微调LLM,用于中文语音识别长文本的纠错任务
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音识别 错误纠正 大型语言模型 长文本处理 数据集构建 中文自然语言处理
📋 核心要点
- 现有语音识别纠错主要集中于短语音,长文本纠错面临上下文理解和错误类型多样性的挑战。
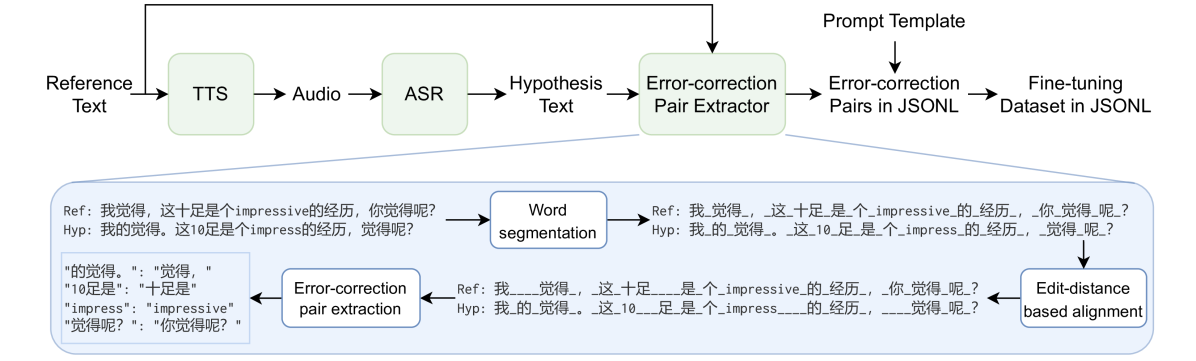
- 构建ChFT数据集,包含文本合成、语音识别和纠错对,用于训练和评估LLM在长文本纠错中的性能。
- 通过微调LLM并设计不同的prompt,在多种测试集上验证了其在长文本纠错中的有效性,并建立了基线。
📝 摘要(中文)
大型语言模型(LLMs)在自动语音识别(ASR)的错误纠正方面显示出巨大的潜力。然而,大多数研究集中于短时语音记录的语句,这是监督ASR训练的主要语音数据形式。本文研究了LLM在由ASR系统从较长语音记录(如播客、新闻广播和会议的文本记录)生成的全文中进行错误纠正的有效性。首先,我们开发了一个中文全文错误纠正数据集,名为ChFT,它利用了文本到语音合成、ASR和错误纠正对提取器的流程。该数据集使我们能够在跨上下文(包括全文和片段)纠正错误,并解决更广泛的错误类型,例如标点符号恢复和反向文本归一化,从而使纠正过程更加全面。其次,我们使用各种提示和目标格式,在构建的数据集上微调预训练的LLM,并评估其在全文错误纠正方面的性能。具体来说,我们基于全文和片段设计提示,考虑各种输出格式,例如直接纠正的文本和基于JSON的错误纠正对。通过各种测试设置,包括同质、最新和困难测试集,我们发现微调的LLM在具有不同提示的全文设置中表现良好,每种提示都呈现出自己的优势和劣势。这为进一步的研究建立了一个有希望的基线。该数据集可在网站上找到。
🔬 方法详解
问题定义:论文旨在解决中文语音识别长文本(如播客、新闻广播、会议记录等)的自动纠错问题。现有方法主要集中于短语音的纠错,无法有效处理长文本中复杂的上下文依赖关系以及标点恢复、反向文本归一化等多种错误类型。
核心思路:论文的核心思路是利用大型语言模型(LLMs)强大的语言理解和生成能力,通过在专门构建的中文长文本纠错数据集上进行微调,使LLM能够有效地纠正语音识别系统在长文本中产生的错误。通过设计不同的prompt,引导LLM生成纠正后的文本或JSON格式的错误纠正对。
技术框架:整体框架包含两个主要部分:1) ChFT数据集的构建,包括文本到语音合成、语音识别和错误纠正对提取三个阶段;2) 基于ChFT数据集的LLM微调和评估,包括prompt设计、模型微调和多种测试集上的性能评估。
关键创新:论文的关键创新在于构建了专门用于中文语音识别长文本纠错的ChFT数据集,该数据集覆盖了多种错误类型,并考虑了长文本的上下文信息。此外,论文还探索了不同的prompt设计和输出格式,以提高LLM在长文本纠错任务中的性能。
关键设计:ChFT数据集的构建过程中,使用了高质量的文本到语音合成技术,以保证合成语音的质量。在LLM微调过程中,设计了基于全文和片段的prompt,并考虑了直接纠正文本和JSON格式的错误纠正对两种输出格式。使用了同质、最新和困难三种测试集,以全面评估LLM的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,经过在ChFT数据集上微调的LLM在长文本纠错任务中表现良好。在不同的测试集上,使用不同的prompt,LLM都能够有效地纠正语音识别系统产生的错误。论文为中文语音识别长文本纠错建立了一个有希望的基线。
🎯 应用场景
该研究成果可应用于语音转录、会议记录、新闻广播等领域,提高长文本语音识别结果的准确性和可读性。通过自动纠错,可以减少人工校对的工作量,提高工作效率。未来,该技术还可以应用于智能客服、语音助手等场景,提升用户体验。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated substantial potential for error correction in Automatic Speech Recognition (ASR). However, most research focuses on utterances from short-duration speech recordings, which are the predominant form of speech data for supervised ASR training. This paper investigates the effectiveness of LLMs for error correction in full-text generated by ASR systems from longer speech recordings, such as transcripts from podcasts, news broadcasts, and meetings. First, we develop a Chinese dataset for full-text error correction, named ChFT, utilizing a pipeline that involves text-to-speech synthesis, ASR, and error-correction pair extractor. This dataset enables us to correct errors across contexts, including both full-text and segment, and to address a broader range of error types, such as punctuation restoration and inverse text normalization, thus making the correction process comprehensive. Second, we fine-tune a pre-trained LLM on the constructed dataset using a diverse set of prompts and target formats, and evaluate its performance on full-text error correction. Specifically, we design prompts based on full-text and segment, considering various output formats, such as directly corrected text and JSON-based error-correction pairs. Through various test settings, including homogeneous, up-to-date, and hard test sets, we find that the fine-tuned LLMs perform well in the full-text setting with different prompts, each presenting its own strengths and weaknesses. This establishes a promising baseline for further research. The dataset is available on the website.