Context-Aware Membership Inference Attacks against Pre-trained Large Language Models
作者: Hongyan Chang, Ali Shahin Shamsabadi, Kleomenis Katevas, Hamed Haddadi, Reza Shokri
分类: cs.CL, cs.AI, cs.CR, cs.LG, stat.ML
发布日期: 2024-09-11 (更新: 2025-09-16)
💡 一句话要点
提出上下文感知成员推理攻击,针对预训练大语言模型的隐私风险
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 成员推理攻击 大语言模型 隐私安全 困惑度 上下文感知
📋 核心要点
- 现有成员推理攻击方法无法有效应用于大语言模型,因为它们忽略了LLM生成文本序列的特性。
- 该论文提出一种新的攻击方法,利用数据点子序列的困惑度动态变化进行成员推理。
- 实验表明,该方法显著优于现有方法,能够有效识别LLM训练数据中的成员信息。
📝 摘要(中文)
本文提出了一种针对预训练大语言模型(LLMs)的成员推理攻击(MIAs),旨在确定某个数据点是否属于模型的训练集。由于传统为分类模型设计的MIAs忽略了LLMs在token序列上的生成特性,因此在LLMs上表现不佳。本文提出了一种新颖的攻击方法,该方法将MIA统计测试应用于数据点内子序列的困惑度动态变化。实验结果表明,该方法显著优于现有方法,揭示了预训练LLMs中与上下文相关的记忆模式。
🔬 方法详解
问题定义:论文旨在解决预训练大语言模型(LLMs)的成员推理攻击(MIA)问题。现有针对分类模型的MIA方法无法有效应用于LLMs,因为它们忽略了LLMs生成文本序列的特性,即LLMs的生成过程是基于上下文的,不同位置的token对模型的影响不同。因此,如何设计一种能够有效利用LLMs生成特性的MIA方法是本文要解决的核心问题。
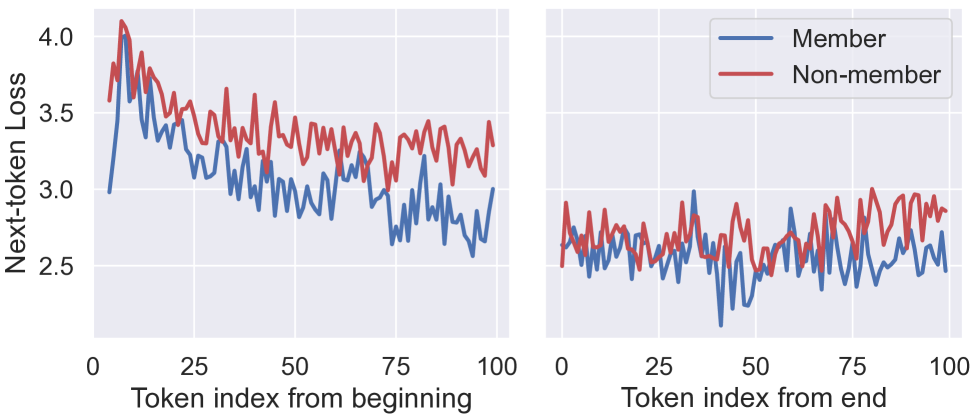
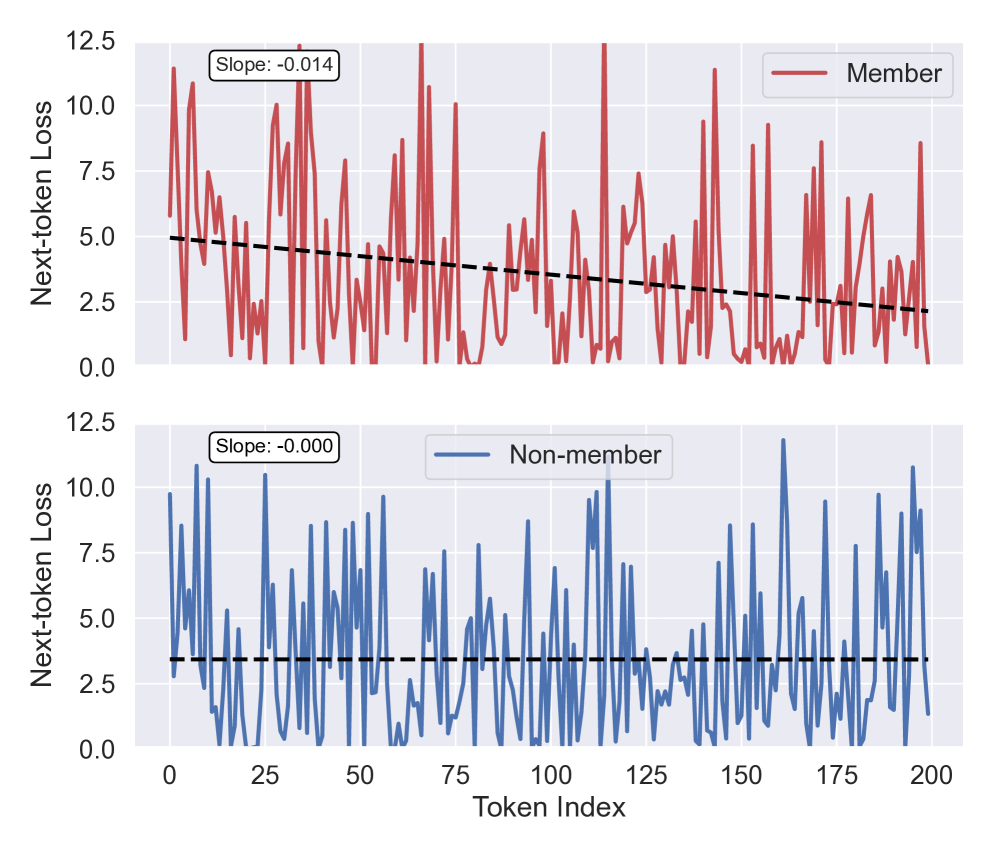
核心思路:论文的核心思路是利用数据点内部子序列的困惑度动态变化来判断该数据点是否属于训练集。具体来说,如果一个数据点属于训练集,那么模型对该数据点内部不同子序列的困惑度变化应该与不属于训练集的数据点有所不同。通过分析这种困惑度动态变化,可以推断出该数据点是否为训练集成员。
技术框架:该攻击方法主要包含以下几个阶段:1) 数据准备:准备用于攻击的候选数据点,包括训练集数据和非训练集数据。2) 子序列划分:将每个数据点划分为多个子序列。3) 困惑度计算:使用目标LLM计算每个子序列的困惑度。4) 统计测试:对训练集和非训练集数据点的困惑度动态变化进行统计测试,例如使用t检验或卡方检验等。5) 成员推断:根据统计测试的结果,判断该数据点是否为训练集成员。
关键创新:该方法最重要的技术创新点在于其上下文感知特性。与以往的MIA方法不同,该方法没有将整个数据点作为一个整体进行分析,而是关注数据点内部子序列的困惑度动态变化。这种上下文感知特性使得该方法能够更有效地利用LLMs的生成特性,从而提高攻击的成功率。
关键设计:论文的关键设计包括:1) 子序列的划分方式:如何选择合适的子序列长度和划分方式,以最大程度地捕捉困惑度动态变化。2) 困惑度计算方法:如何选择合适的困惑度计算方法,以准确反映模型对不同子序列的预测能力。3) 统计测试的选择:如何选择合适的统计测试方法,以有效区分训练集和非训练集数据点的困惑度动态变化。
🖼️ 关键图片
📊 实验亮点
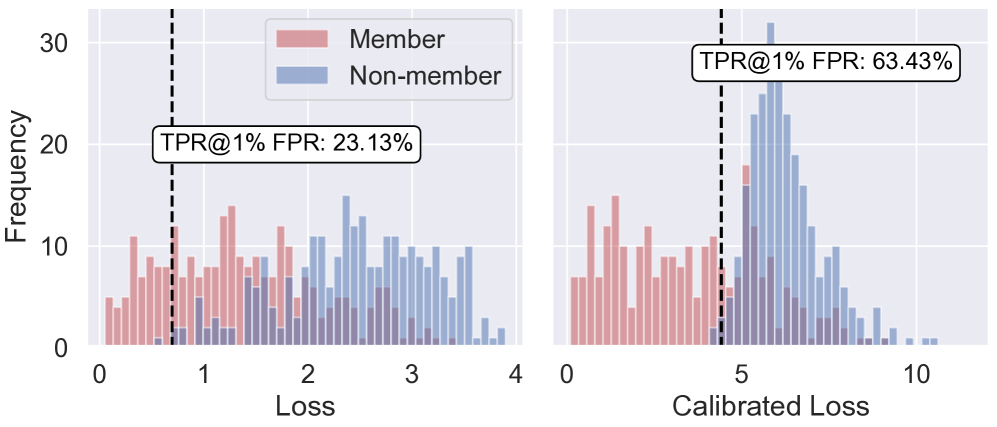
实验结果表明,该方法在多个预训练大语言模型上显著优于现有的成员推理攻击方法。具体来说,该方法在某些数据集上可以将攻击成功率提高10%以上,表明其能够更有效地识别LLM训练数据中的成员信息。此外,实验还揭示了预训练LLMs中与上下文相关的记忆模式,为理解LLMs的内部机制提供了新的视角。
🎯 应用场景
该研究成果可应用于评估和提升预训练大语言模型的隐私安全性。通过使用该攻击方法,可以发现模型中存在的潜在隐私漏洞,并采取相应的防御措施,例如差分隐私训练、数据增强等,以保护用户数据的隐私。此外,该研究还可以帮助开发者更好地理解LLMs的记忆机制,从而设计出更加安全可靠的模型。
📄 摘要(原文)
Membership Inference Attacks (MIAs) on pre-trained Large Language Models (LLMs) aim at determining if a data point was part of the model's training set. Prior MIAs that are built for classification models fail at LLMs, due to ignoring the generative nature of LLMs across token sequences. In this paper, we present a novel attack on pre-trained LLMs that adapts MIA statistical tests to the perplexity dynamics of subsequences within a data point. Our method significantly outperforms prior approaches, revealing context-dependent memorization patterns in pre-trained LLMs.