A Simplified Retriever to Improve Accuracy of Phenotype Normalizations by Large Language Models
作者: Daniel B. Hier, Thanh Son Do, Tayo Obafemi-Ajayi
分类: cs.CL, cs.AI, cs.IR
发布日期: 2024-09-11 (更新: 2025-03-04)
备注: Published by Frontiers in Digital Health
期刊: Frontiers in Digital Health 7, (2025): 1495040. Accessed March 4, 2025
DOI: 10.3389/fdgth.2025.1495040
💡 一句话要点
提出一种简化的检索器,通过大语言模型提升表型标准化的准确性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表型标准化 大语言模型 检索增强 BioBERT 人类表型本体
📋 核心要点
- 现有表型标准化方法依赖术语定义,检索效率和准确性有待提升。
- 论文提出利用BioBERT上下文嵌入的简化检索器,无需显式术语定义。
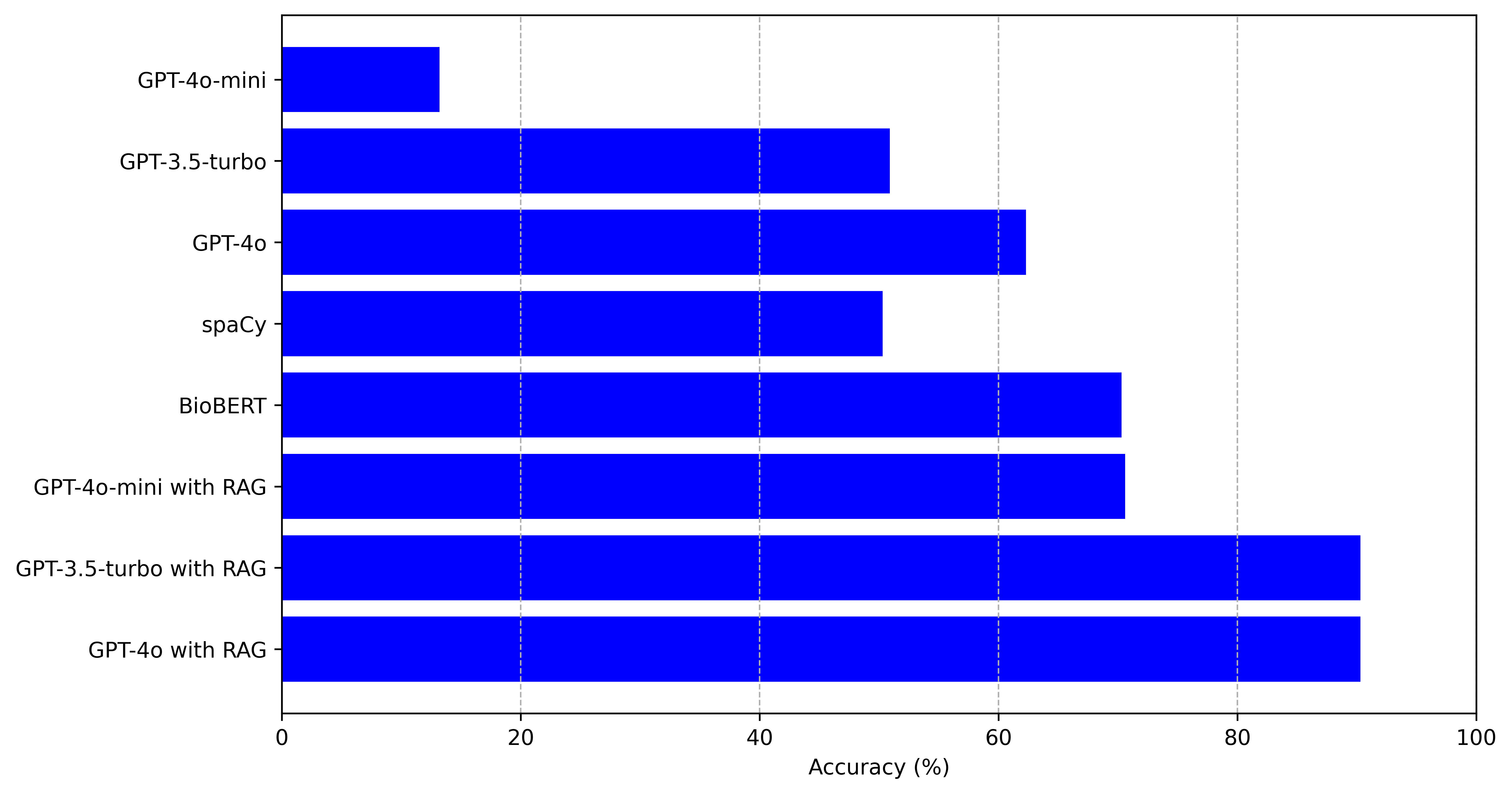
- 实验表明,该方法将LLM的标准化准确率从62.3%提升至90.3%。
📝 摘要(中文)
本文介绍了一种简化的检索器,它通过使用BioBERT的上下文词嵌入在人类表型本体(HPO)中搜索候选匹配项,从而提高大语言模型(LLM)在表型术语标准化任务中的准确性,而无需显式的术语定义。通过对来自人类孟德尔遗传在线(OMIM)临床概要的术语进行测试,结果表明,在不进行增强的情况下,最先进的LLM的标准化准确率基线为62.3%,而使用检索器增强后,准确率提高到90.3%。该方法可能推广到其他生物医学术语标准化任务,并为更复杂的检索方法提供了一种有效的替代方案。
🔬 方法详解
问题定义:论文旨在解决表型术语标准化任务中,现有方法依赖于显式术语定义,导致检索效率和准确性受限的问题。现有方法的痛点在于需要维护和更新庞大的术语定义库,并且难以处理术语的多义性和上下文相关性。
核心思路:论文的核心思路是利用预训练语言模型BioBERT的上下文词嵌入能力,直接在人类表型本体(HPO)中搜索与输入术语在语义上最相关的候选匹配项。这样可以避免对显式术语定义的依赖,并更好地捕捉术语的上下文信息。
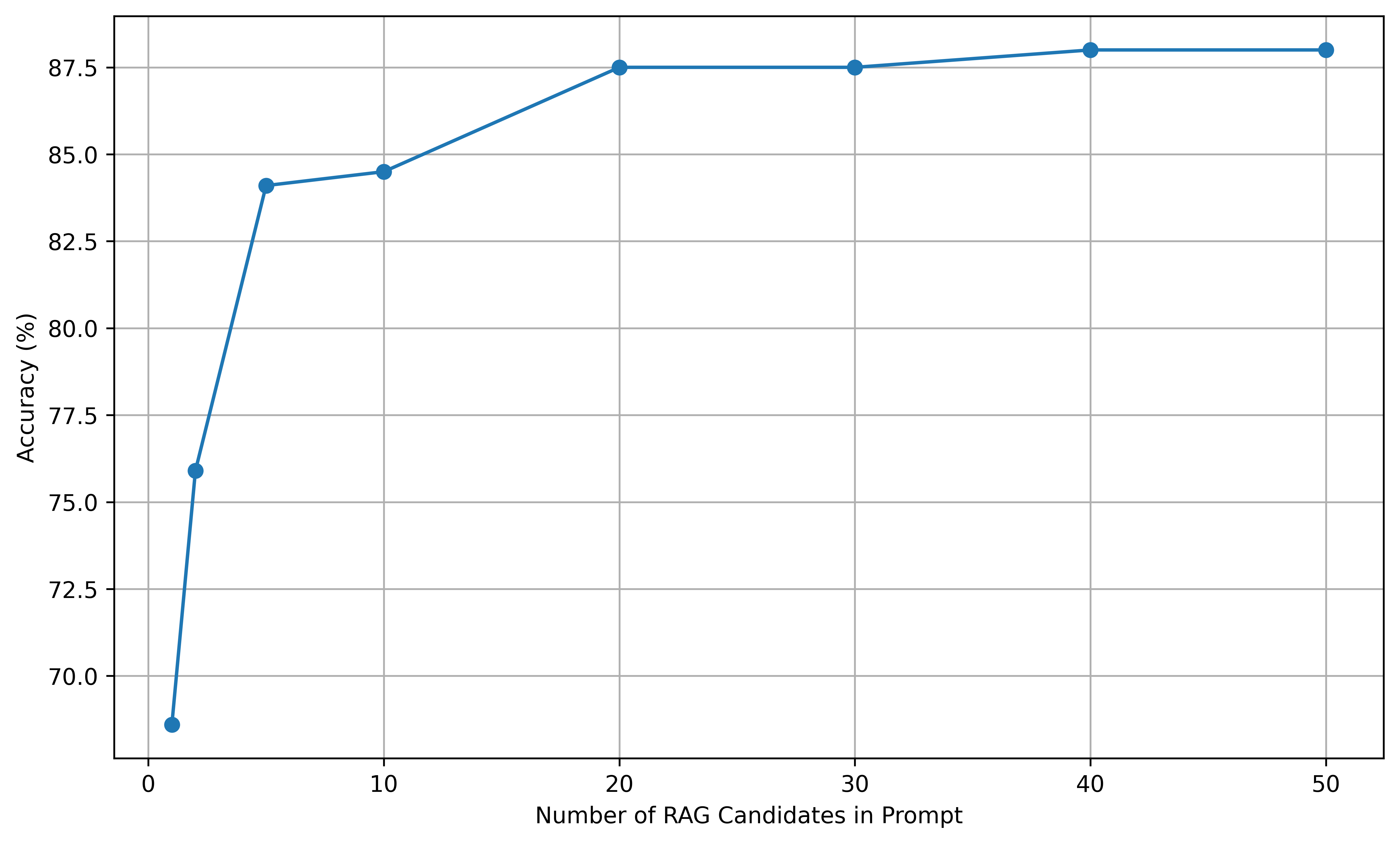
技术框架:该方法主要包含以下几个阶段:1) 使用BioBERT对输入术语和HPO中的所有术语进行编码,得到它们的上下文词嵌入表示。2) 计算输入术语的嵌入向量与HPO中每个术语的嵌入向量之间的相似度(例如,余弦相似度)。3) 选择相似度最高的若干个HPO术语作为候选匹配项。4) 将这些候选匹配项提供给LLM,由LLM最终确定正确的标准化结果。
关键创新:最重要的技术创新点在于使用上下文词嵌入进行检索,避免了对显式术语定义的依赖。与现有方法相比,该方法更加灵活和高效,能够更好地处理术语的多义性和上下文相关性。
关键设计:论文的关键设计包括:1) 使用BioBERT作为嵌入模型,因为它在生物医学领域具有良好的表现。2) 使用余弦相似度作为相似度度量,因为它简单有效。3) 将检索到的候选匹配项作为LLM的输入,利用LLM的推理能力进行最终的标准化。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用该简化检索器后,LLM在OMIM临床概要术语标准化任务中的准确率从基线62.3%显著提升至90.3%,提升幅度高达28个百分点。这表明该方法能够有效提高表型标准化的准确性,并优于不进行检索增强的LLM。
🎯 应用场景
该研究成果可应用于临床诊断、基因组学研究、药物研发等领域,提高表型数据标准化效率和准确性,从而促进医学知识发现和临床决策支持。未来可扩展到其他生物医学术语标准化任务,例如疾病、基因等。
📄 摘要(原文)
Large language models (LLMs) have shown improved accuracy in phenotype term normalization tasks when augmented with retrievers that suggest candidate normalizations based on term definitions. In this work, we introduce a simplified retriever that enhances LLM accuracy by searching the Human Phenotype Ontology (HPO) for candidate matches using contextual word embeddings from BioBERT without the need for explicit term definitions. Testing this method on terms derived from the clinical synopses of Online Mendelian Inheritance in Man (OMIM), we demonstrate that the normalization accuracy of a state-of-the-art LLM increases from a baseline of 62.3% without augmentation to 90.3% with retriever augmentation. This approach is potentially generalizable to other biomedical term normalization tasks and offers an efficient alternative to more complex retrieval methods.