Propaganda to Hate: A Multimodal Analysis of Arabic Memes with Multi-Agent LLMs
作者: Firoj Alam, Md. Rafiul Biswas, Uzair Shah, Wajdi Zaghouani, Georgios Mikros
分类: cs.CL, cs.AI
发布日期: 2024-09-11 (更新: 2024-10-06)
备注: propaganda, hate-speech, disinformation, misinformation, fake news, LLMs, GPT-4, multimodality, multimodal LLMs
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于多智能体LLM的框架,分析阿拉伯语Meme中的仇恨宣传内容
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态分析 Meme分析 仇恨言论检测 宣传检测 多智能体系统 大型语言模型 阿拉伯语 社交媒体
📋 核心要点
- 现有方法在检测Meme中的宣传或仇恨内容时,通常独立进行,忽略了二者之间的潜在关联。
- 论文提出一种基于多智能体LLM的框架,用于分析阿拉伯语Meme中的宣传和仇恨内容的交叉点。
- 通过实验验证了Meme中宣传和仇恨之间存在关联,并提供了可供未来研究参考的基线结果。
📝 摘要(中文)
在过去十年中,社交媒体平台被广泛用于信息传播和消费。虽然大部分内容旨在促进公民新闻和公众意识,但也有部分内容旨在误导用户。在文本、图像和视频等不同内容类型中,Meme(叠加在图像上的文本)尤其流行,并且可以作为宣传、仇恨和幽默的强大载体。目前的研究主要集中于单独检测Meme中的此类内容。然而,对其交叉点的研究非常有限。本研究采用基于多智能体LLM的方法,探索Meme中宣传和仇恨之间的交叉点。我们扩展了宣传性Meme数据集,并添加了粗粒度和细粒度的仇恨标签。我们的研究结果表明,Meme中的宣传和仇恨之间存在关联。我们提供了详细的实验结果,可以作为未来研究的基线。我们将公开实验资源,供社区使用。
🔬 方法详解
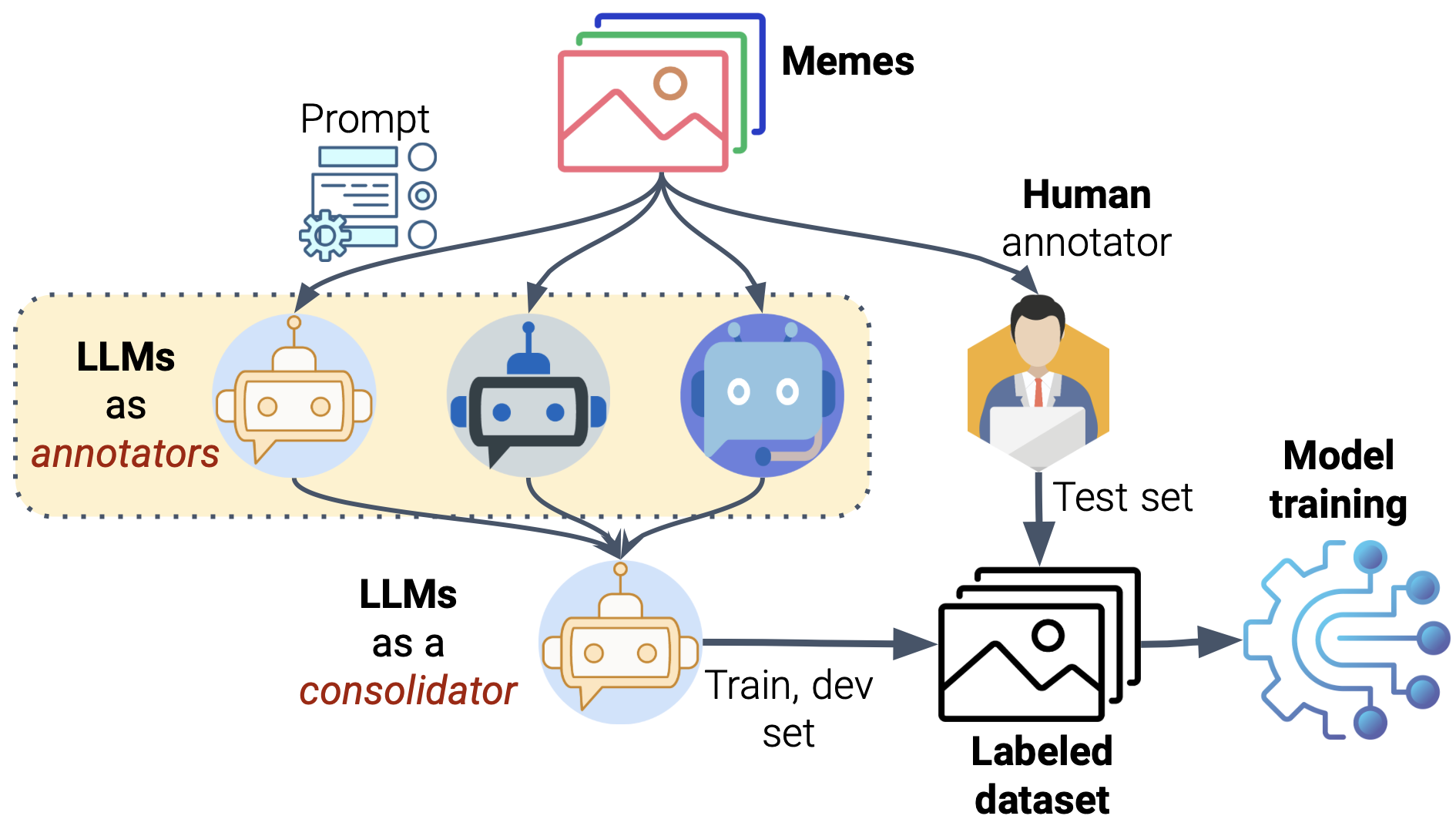
问题定义:论文旨在解决阿拉伯语Meme中宣传和仇恨内容相互关联的检测问题。现有方法通常孤立地检测宣传或仇恨内容,忽略了二者之间的潜在联系,无法有效识别同时包含这两种属性的Meme。
核心思路:论文的核心思路是利用多智能体LLM(大型语言模型)框架,模拟多个智能体协同工作,分别从不同角度分析Meme的文本和图像内容,并综合判断其是否包含宣传和仇恨信息。这种方法能够更好地捕捉二者之间的复杂关系。
技术框架:整体框架包含以下几个主要模块:1) 数据集构建:扩展现有的宣传性Meme数据集,并添加粗粒度和细粒度的仇恨标签。2) 多智能体LLM:构建基于LLM的多智能体系统,每个智能体负责分析Meme的不同方面(例如,文本情感、图像语义)。3) 信息融合:设计信息融合机制,将各个智能体的分析结果进行整合,最终判断Meme是否包含宣传和仇恨内容。
关键创新:论文的关键创新在于:1) 提出了一个多智能体LLM框架,用于分析Meme中的宣传和仇恨内容,能够更好地捕捉二者之间的复杂关系。2) 构建了一个包含宣传和仇恨标签的阿拉伯语Meme数据集,为相关研究提供了宝贵资源。
关键设计:论文中关于LLM的具体选择、智能体的数量和角色分配、信息融合机制的设计等技术细节未知。数据集的构建过程,包括仇恨标签的标注标准和方法,也未详细说明。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了阿拉伯语Meme中宣传和仇恨之间存在关联。虽然具体的性能数据和对比基线未知,但该研究提供了详细的实验结果,可以作为未来研究的基线。公开的实验资源也将促进相关领域的研究进展。
🎯 应用场景
该研究成果可应用于社交媒体内容审核、舆情监控和虚假信息检测等领域。通过自动识别包含宣传和仇恨信息的Meme,可以帮助平台更好地管理内容,减少有害信息的传播,维护健康的在线环境。未来,该方法可以扩展到其他语言和模态,提升跨文化和跨媒体内容分析能力。
📄 摘要(原文)
In the past decade, social media platforms have been used for information dissemination and consumption. While a major portion of the content is posted to promote citizen journalism and public awareness, some content is posted to mislead users. Among different content types such as text, images, and videos, memes (text overlaid on images) are particularly prevalent and can serve as powerful vehicles for propaganda, hate, and humor. In the current literature, there have been efforts to individually detect such content in memes. However, the study of their intersection is very limited. In this study, we explore the intersection between propaganda and hate in memes using a multi-agent LLM-based approach. We extend the propagandistic meme dataset with coarse and fine-grained hate labels. Our finding suggests that there is an association between propaganda and hate in memes. We provide detailed experimental results that can serve as a baseline for future studies. We will make the experimental resources publicly available to the community (https://github.com/firojalam/propaganda-and-hateful-memes).