Leveraging Unstructured Text Data for Federated Instruction Tuning of Large Language Models
作者: Rui Ye, Rui Ge, Yuchi Fengting, Jingyi Chai, Yanfeng Wang, Siheng Chen
分类: cs.CL, cs.AI, cs.MA
发布日期: 2024-09-11
备注: 11 pages, work in progress
💡 一句话要点
提出FedIT-U2S框架,利用非结构化文本数据进行联邦指令调优,扩展LLM应用场景。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 指令调优 非结构化数据 少样本学习 大型语言模型 数据生成 检索式学习
📋 核心要点
- 现有联邦指令调优方法依赖结构化指令数据,需要大量人工标注,限制了其在非结构化数据场景的应用。
- FedIT-U2S框架通过少样本生成和检索式示例选择,自动将非结构化文本转换为结构化指令数据,用于联邦指令调优。
- 实验表明,FedIT-U2S在医学、知识和数学等领域均能显著提升LLM性能,扩展了联邦指令调优的应用范围。
📝 摘要(中文)
联邦指令调优允许多个客户端协作微调共享的大型语言模型(LLM),使其能够遵循人类指令,而无需直接共享原始数据。然而,现有文献不切实际地要求所有客户端都拥有指令调优数据(即,结构化的指令-响应对),这需要大量的人工标注,因为客户端的数据通常是非结构化文本。为了解决这个问题,我们提出了一种新颖而灵活的框架FedIT-U2S,它可以自动将非结构化语料库转换为结构化数据,用于联邦指令调优。FedIT-U2S包含两个关键步骤:(1)少样本指令调优数据生成,其中每个非结构化数据片段与几个示例结合,以提示LLM生成指令-响应对。为了进一步增强灵活性,提出了一种基于检索的示例选择技术,其中示例是基于客户端数据片段与示例池之间的相关性自动选择的,从而无需预先确定示例。(2)基于生成数据的典型联邦指令调优过程。总的来说,只要客户端拥有有价值的文本语料库,FedIT-U2S就可以应用于各种场景,从而扩大了联邦指令调优的应用范围。我们在三个领域(医学、知识和数学)进行了一系列实验,表明我们提出的FedIT-U2S可以持续且显著地改进基础LLM。
🔬 方法详解
问题定义:现有联邦指令调优方法需要客户端提供结构化的指令-响应对数据,这在实际应用中是一个很大的限制,因为很多客户端拥有的数据都是非结构化的文本数据,需要大量的人工标注才能转化为结构化数据。因此,如何利用客户端的非结构化文本数据进行联邦指令调优是一个亟待解决的问题。
核心思路:FedIT-U2S的核心思路是将非结构化文本数据自动转化为结构化的指令-响应对数据,然后利用这些生成的数据进行联邦指令调优。通过少样本学习和检索式示例选择,可以有效地利用LLM的生成能力,将非结构化文本转化为高质量的指令数据,从而避免了大量的人工标注。
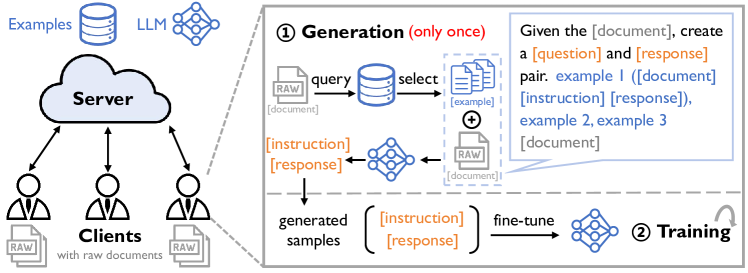
技术框架:FedIT-U2S框架主要包含两个阶段:(1)少样本指令调优数据生成阶段:该阶段利用LLM的少样本学习能力,结合非结构化文本数据和少量示例,生成指令-响应对。为了提高生成数据的质量,采用了基于检索的示例选择技术,根据非结构化文本数据与示例池之间的相关性,自动选择合适的示例。(2)联邦指令调优阶段:该阶段利用生成的数据,采用标准的联邦学习算法进行指令调优,从而得到一个能够遵循人类指令的LLM。
关键创新:FedIT-U2S的关键创新在于能够自动将非结构化文本数据转化为结构化的指令数据,从而避免了对大量人工标注的依赖。此外,基于检索的示例选择技术可以有效地提高生成数据的质量,从而提升联邦指令调优的效果。与现有方法相比,FedIT-U2S更加灵活,可以应用于更广泛的场景。
关键设计:在少样本指令调优数据生成阶段,需要选择合适的LLM作为生成模型,并设计合适的prompt模板。在基于检索的示例选择技术中,需要选择合适的相似度度量方法和检索算法。在联邦指令调优阶段,需要选择合适的联邦学习算法和超参数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,FedIT-U2S在医学、知识和数学三个领域均能显著提升LLM的性能。与基线模型相比,FedIT-U2S在这些领域取得了显著的改进,证明了该框架的有效性。具体性能数据未知,但摘要强调了“consistently and significantly brings improvement over the base LLM”。
🎯 应用场景
FedIT-U2S框架可应用于各种拥有大量非结构化文本数据的领域,例如医疗、金融、法律等。通过该框架,可以在保护用户数据隐私的前提下,利用这些数据进行LLM的指令调优,从而提升LLM在特定领域的性能,并为用户提供更加个性化的服务。该研究具有重要的实际价值和广阔的应用前景。
📄 摘要(原文)
Federated instruction tuning enables multiple clients to collaboratively fine-tune a shared large language model (LLM) that can follow humans' instructions without directly sharing raw data. However, existing literature impractically requires that all the clients readily hold instruction-tuning data (i.e., structured instruction-response pairs), which necessitates massive human annotations since clients' data is usually unstructured text instead. Addressing this, we propose a novel and flexible framework FedIT-U2S, which can automatically transform unstructured corpus into structured data for federated instruction tuning. FedIT-U2S consists two key steps: (1) few-shot instruction-tuning data generation, where each unstructured data piece together with several examples is combined to prompt an LLM in generating an instruction-response pair. To further enhance the flexibility, a retrieval-based example selection technique is proposed, where the examples are automatically selected based on the relatedness between the client's data piece and example pool, bypassing the need of determining examples in advance. (2) A typical federated instruction tuning process based on the generated data. Overall, FedIT-U2S can be applied to diverse scenarios as long as the client holds valuable text corpus, broadening the application scope of federated instruction tuning. We conduct a series of experiments on three domains (medicine, knowledge, and math), showing that our proposed FedIT-U2S can consistently and significantly brings improvement over the base LLM.