Ontology-Free General-Domain Knowledge Graph-to-Text Generation Dataset Synthesis using Large Language Model
作者: Daehee Kim, Deokhyung Kang, Sangwon Ryu, Gary Geunbae Lee
分类: cs.CL, cs.AI
发布日期: 2024-09-11
备注: 18 pages, 9 figures
💡 一句话要点
提出WikiOFGraph:利用大语言模型合成通用领域知识图谱到文本生成数据集,提升图文一致性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱到文本生成 大型语言模型 数据合成 通用领域 图文一致性 自然语言生成 预训练语言模型
📋 核心要点
- 现有G2T数据集规模小、质量不高,且依赖本体,限制了通用领域G2T生成研究的进展。
- 利用大语言模型和Data-QuestEval,自动生成大规模、高质量、无本体依赖的G2T数据集WikiOFGraph。
- 实验表明,在WikiOFGraph上微调的PLM在多个指标上优于其他数据集训练的模型,验证了数据集的有效性。
📝 摘要(中文)
知识图谱到文本(G2T)生成涉及将结构化知识图谱转化为自然语言文本。预训练语言模型(PLM)的最新进展提高了G2T性能,但其有效性取决于具有精确图文对齐的数据集。然而,高质量的通用领域G2T生成数据集的稀缺性限制了通用领域G2T生成研究的进展。为了解决这个问题,我们引入了Wikipedia Ontology-Free Graph-text dataset (WikiOFGraph),这是一个新的大规模G2T数据集,它使用了一种利用大型语言模型(LLM)和Data-QuestEval的新方法生成。我们的新数据集包含585万个通用领域图文对,在不依赖外部本体的情况下提供了高度的图文一致性。实验结果表明,在WikiOFGraph上微调的PLM在各种评估指标上优于在其他数据集上训练的PLM。我们的方法被证明是生成高质量G2T数据的可扩展且有效的解决方案,显著推进了G2T生成领域。
🔬 方法详解
问题定义:论文旨在解决通用领域知识图谱到文本生成(G2T)任务中,高质量训练数据匮乏的问题。现有G2T数据集通常规模较小,图文对齐质量不高,并且往往依赖于特定的知识本体,限制了模型在通用领域的泛化能力。因此,需要一种能够自动生成大规模、高质量、无本体依赖的G2T数据集的方法。
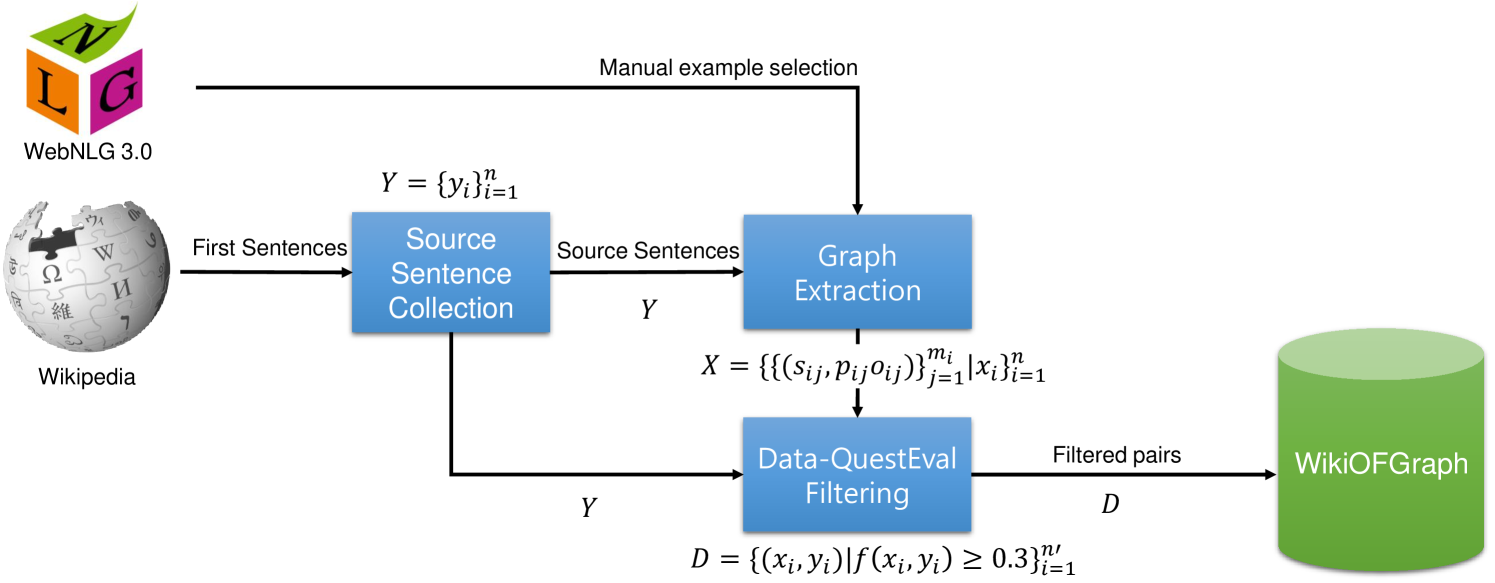
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大生成能力,结合Data-QuestEval评估指标,自动合成高质量的G2T数据。通过LLM将知识图谱转化为自然语言文本,并使用Data-QuestEval评估生成文本与知识图谱的一致性,从而筛选和优化生成的数据。这种方法避免了人工标注的成本,并能够生成大规模的训练数据。
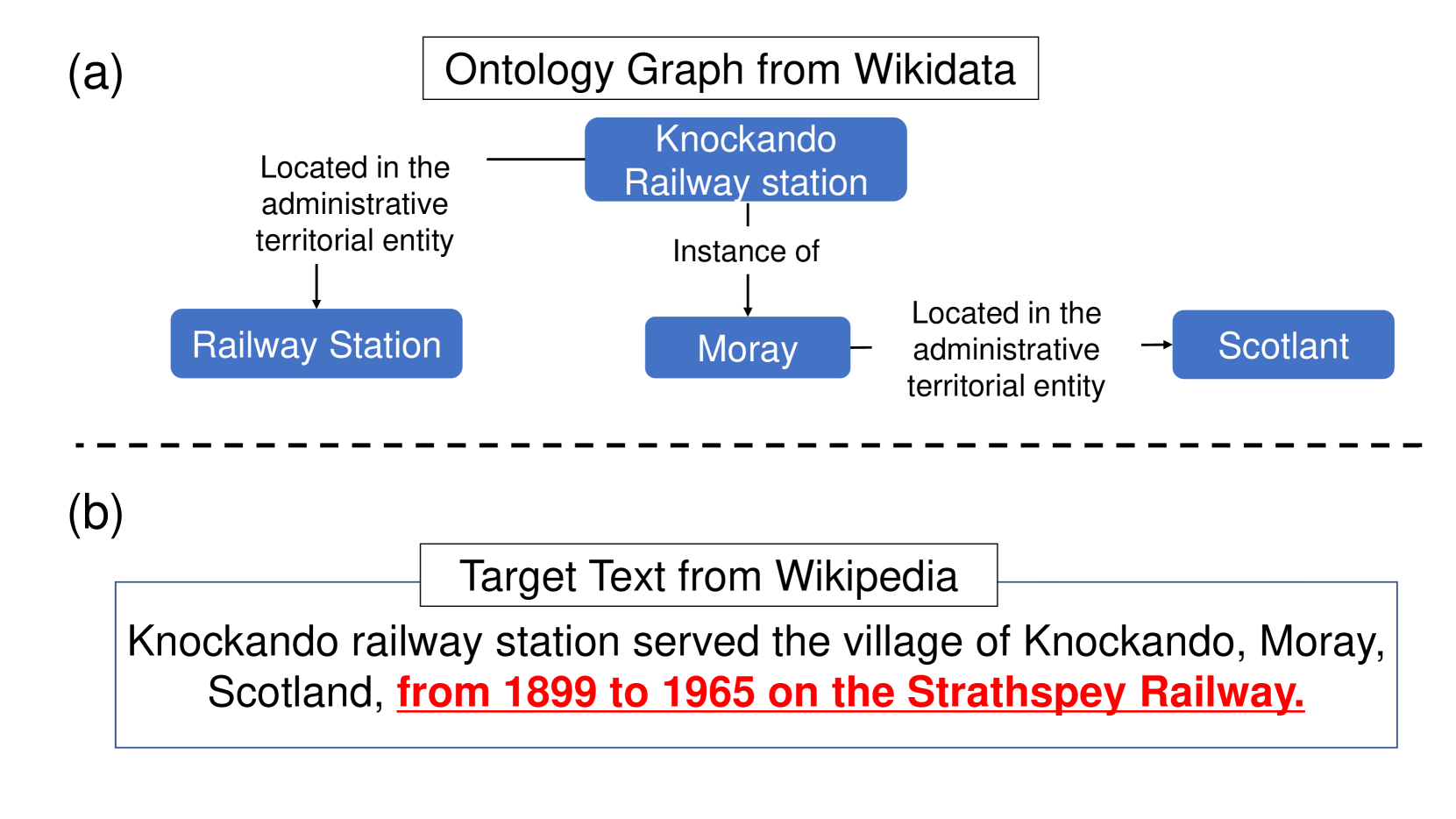
技术框架:该方法主要包含以下几个阶段:1) 从Wikipedia中提取知识图谱数据;2) 使用LLM将知识图谱转化为自然语言文本;3) 使用Data-QuestEval评估生成文本与知识图谱的一致性;4) 根据Data-QuestEval的评分,筛选和优化生成的数据,构建最终的WikiOFGraph数据集。
关键创新:该方法最重要的创新点在于利用LLM和Data-QuestEval自动合成G2T数据,无需人工标注,从而能够生成大规模、高质量、无本体依赖的训练数据。与传统的G2T数据集构建方法相比,该方法具有更高的效率和可扩展性。
关键设计:在利用LLM生成文本时,论文可能采用了特定的prompt工程技术,以引导LLM生成更符合要求的文本。Data-QuestEval的评分阈值是影响数据集质量的关键参数,需要根据实际情况进行调整。此外,论文可能还采用了数据增强等技术,以进一步提高数据集的多样性和鲁棒性。
🖼️ 关键图片
📊 实验亮点
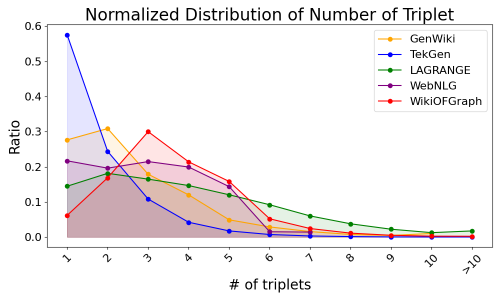
实验结果表明,在WikiOFGraph数据集上微调的PLM在多个G2T评估指标上都取得了显著的提升,例如BLEU、ROUGE和METEOR等。与在其他数据集上训练的模型相比,该模型在图文一致性方面表现更佳,验证了WikiOFGraph数据集的有效性和优越性。
🎯 应用场景
该研究成果可广泛应用于知识图谱相关的自然语言生成任务,例如自动生成产品描述、新闻摘要、人物传记等。高质量的G2T数据集能够提升相关应用的性能和用户体验,并促进知识图谱在自然语言处理领域的应用。
📄 摘要(原文)
Knowledge Graph-to-Text (G2T) generation involves verbalizing structured knowledge graphs into natural language text. Recent advancements in Pretrained Language Models (PLMs) have improved G2T performance, but their effectiveness depends on datasets with precise graph-text alignment. However, the scarcity of high-quality, general-domain G2T generation datasets restricts progress in the general-domain G2T generation research. To address this issue, we introduce Wikipedia Ontology-Free Graph-text dataset (WikiOFGraph), a new large-scale G2T dataset generated using a novel method that leverages Large Language Model (LLM) and Data-QuestEval. Our new dataset, which contains 5.85M general-domain graph-text pairs, offers high graph-text consistency without relying on external ontologies. Experimental results demonstrate that PLM fine-tuned on WikiOFGraph outperforms those trained on other datasets across various evaluation metrics. Our method proves to be a scalable and effective solution for generating high-quality G2T data, significantly advancing the field of G2T generation.