RNR: Teaching Large Language Models to Follow Roles and Rules
作者: Kuan Wang, Alexander Bukharin, Haoming Jiang, Qingyu Yin, Zhengyang Wang, Tuo Zhao, Jingbo Shang, Chao Zhang, Bing Yin, Xian Li, Jianshu Chen, Shiyang Li
分类: cs.CL, cs.AI, cs.HC
发布日期: 2024-09-10
💡 一句话要点
提出RNR以提升大语言模型的角色与规则遵循能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令微调 角色遵循 规则遵循 自动化数据生成 大型语言模型 系统提示 自然语言处理
📋 核心要点
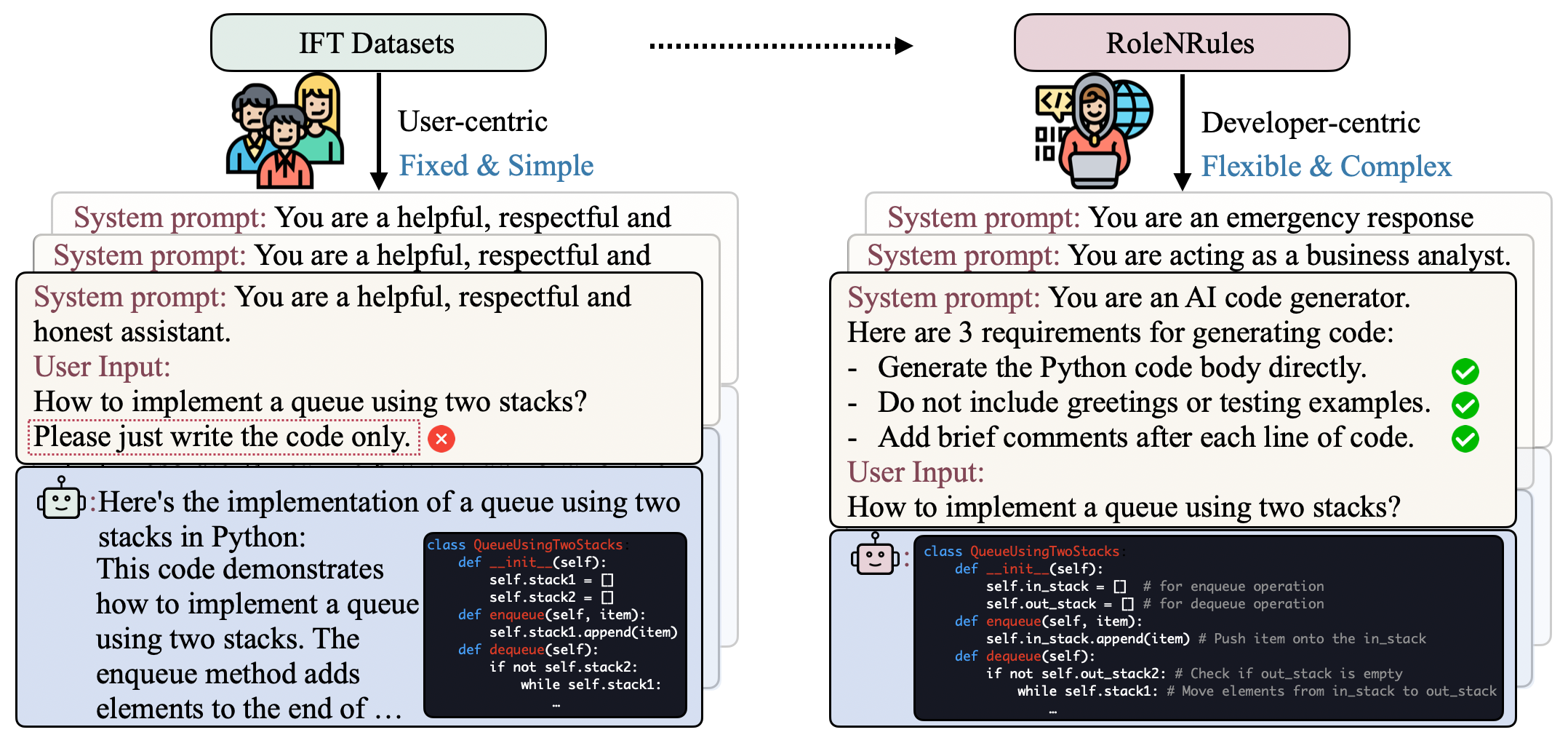
- 现有的指令微调模型在遵循开发者设定的复杂角色和规则方面表现不佳,限制了其实际应用。
- 本文提出RNR,通过自动化生成多样化的角色和规则数据,增强模型对复杂系统提示的遵循能力。
- 实验结果显示,RNR在Alpaca和Ultrachat数据集上,规则遵循的通过率提高超过25%,且未对常规指令遵循基准造成回归。
📝 摘要(中文)
指令微调(IFT)能够通过监督学习引导大型语言模型(LLMs)遵循用户指令。然而,现有模型在遵循开发者指定的复杂角色和规则方面存在不足,这对于安全交互至关重要。为此,本文提出了RNR,一个自动化数据生成管道,能够从现有IFT指令中生成多样化的角色和规则及其对应响应。这些数据可用于训练遵循复杂系统提示的模型。实验结果表明,RNR显著提升了LLMs的角色和规则遵循能力,尤其在规则遵循的通过率上提高了超过25%。
🔬 方法详解
问题定义:本文旨在解决现有大型语言模型在遵循开发者设定的复杂角色和规则方面的不足。现有方法主要依赖于用户指令,缺乏对系统提示的有效响应能力。
核心思路:RNR通过自动化生成多样化的角色和规则数据,结合相应的响应,来训练模型以提高其遵循复杂系统提示的能力。这种方法旨在丰富模型的训练数据,使其能够更好地理解和执行复杂指令。
技术框架:RNR的整体架构包括数据生成模块和模型训练模块。数据生成模块从现有IFT指令中提取信息,生成多样化的角色和规则;模型训练模块则利用生成的数据对模型进行训练,以提升其遵循能力。
关键创新:RNR的主要创新在于其自动化的数据生成管道,能够从现有指令中提取并生成新的角色和规则。这一方法与传统的手动标注数据方式相比,显著提高了数据的多样性和覆盖面。
关键设计:在模型训练过程中,RNR采用了特定的损失函数来优化模型对角色和规则的遵循能力,同时确保在常规指令遵循基准上不出现性能回退。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RNR在Alpaca和Ultrachat数据集上,模型在规则遵循能力上提高超过25%,且在常规指令遵循基准上未出现性能回退,显示出其有效性和可靠性。
🎯 应用场景
该研究的潜在应用场景包括智能客服、虚拟助手和教育领域等,能够使大型语言模型在遵循复杂指令和规则时表现更为出色,从而提升用户体验和安全性。未来,RNR的技术框架可扩展至更多领域,推动人机交互的智能化进程。
📄 摘要(原文)
Instruction fine-tuning (IFT) elicits instruction following capabilities and steers the behavior of large language models (LLMs) via supervised learning. However, existing models trained on open-source IFT datasets only have the ability to follow instructions from users, and often fail to follow complex role and rules specified by developers, a.k.a. system prompts. The ability to follow these roles and rules is essential for deployment, as it ensures that the model safely interacts with users within developer defined guidelines. To improve such role and rule following ability, we propose \model, an automated data generation pipeline that generates diverse roles and rules from existing IFT instructions, along with corresponding responses. This data can then be used to train models that follow complex system prompts. The models are evaluated on our newly created benchmarks for role and rule following ability, as well as standard instruction-following benchmarks and general NLP tasks. Our framework significantly improves role and rule following capability in LLMs, as evidenced by over 25% increase in pass-rate on rule adherence, i.e. following all requirements, in our experiments with the Alpaca and Ultrachat datasets. Moreover, our models achieves this increase without any regression on popular instruction following benchmarks.