E2LLM: Encoder Elongated Large Language Models for Long-Context Understanding and Reasoning
作者: Zihan Liao, Jun Wang, Hang Yu, Lingxiao Wei, Jianguo Li, Jun Wang, Wei Zhang
分类: cs.CL
发布日期: 2024-09-10 (更新: 2025-08-29)
备注: Accept by EMNLP'25
💡 一句话要点
E2LLM:提出Encoder扩展的大语言模型,用于长文本理解与推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本理解 大语言模型 文本编码器 软提示 指令微调
📋 核心要点
- 现有大语言模型在处理长文本时面临计算复杂度高、性能下降以及与现有预训练模型兼容性差等问题。
- E2LLM的核心思想是利用预训练编码器将长文本压缩成软提示,并与解码器LLM对齐,从而实现高效的长文本处理。
- 实验结果表明,E2LLM在文档摘要和问答任务上优于现有方法,并在LongBench v2长文本基准测试中取得了最佳性能。
📝 摘要(中文)
本文提出了一种名为E2LLM(Encoder Elongated Large Language Models)的新方法,旨在解决长文本处理中高性能、低计算复杂度和与预训练模型兼容性这三个挑战,即“不可能三角”。E2LLM将长文本分割成块,使用预训练的文本编码器将每个块压缩成软提示,并通过适配器将这些表示与仅解码器的大语言模型对齐。为了增强LLM对这些软提示的推理能力,采用了两种训练目标:编码器输出重构和长文本指令微调。大量实验表明,E2LLM在文档摘要和问答任务中的有效性和效率均优于8种最先进的方法,并且在同等规模的模型中,在LongBench v2上取得了最佳性能。
🔬 方法详解
问题定义:现有的大语言模型在处理长文本时,面临着计算复杂度高、推理效率低以及难以有效利用现有预训练模型等问题。直接扩展模型规模虽然可以提升性能,但会显著增加计算成本。因此,如何在保证性能的同时,降低计算复杂度,并与现有预训练模型兼容,是长文本处理面临的关键挑战。
核心思路:E2LLM的核心思路是将长文本分割成多个块,然后利用预训练的文本编码器将每个块压缩成软提示。这些软提示包含了每个文本块的关键信息,并且维度较低,可以显著降低计算复杂度。然后,通过一个适配器将这些软提示与解码器大语言模型对齐,从而使LLM能够利用这些软提示进行推理。
技术框架:E2LLM的整体架构包含三个主要模块:文本编码器、适配器和解码器大语言模型。首先,长文本被分割成多个块。然后,预训练的文本编码器(如BERT或RoBERTa)将每个文本块编码成一个软提示。接下来,适配器将这些软提示转换成解码器LLM可以理解的表示。最后,解码器LLM利用这些表示进行推理,生成最终的输出。
关键创新:E2LLM的关键创新在于利用预训练的文本编码器将长文本压缩成软提示,从而降低了计算复杂度,并实现了与现有预训练模型的兼容。与直接扩展LLM的上下文窗口相比,E2LLM的方法更加高效,并且可以更好地利用现有预训练模型的知识。此外,E2LLM还采用了两种训练目标:编码器输出重构和长文本指令微调,以增强LLM对软提示的推理能力。
关键设计:E2LLM的关键设计包括:1) 使用预训练的文本编码器,例如BERT或RoBERTa,以获得高质量的文本表示;2) 设计一个轻量级的适配器,将编码器的输出映射到LLM的输入空间;3) 采用编码器输出重构损失,鼓励编码器保留输入文本的关键信息;4) 使用长文本指令微调,使LLM能够更好地利用软提示进行推理。具体的参数设置和网络结构需要根据具体的任务和数据集进行调整。
🖼️ 关键图片

📊 实验亮点
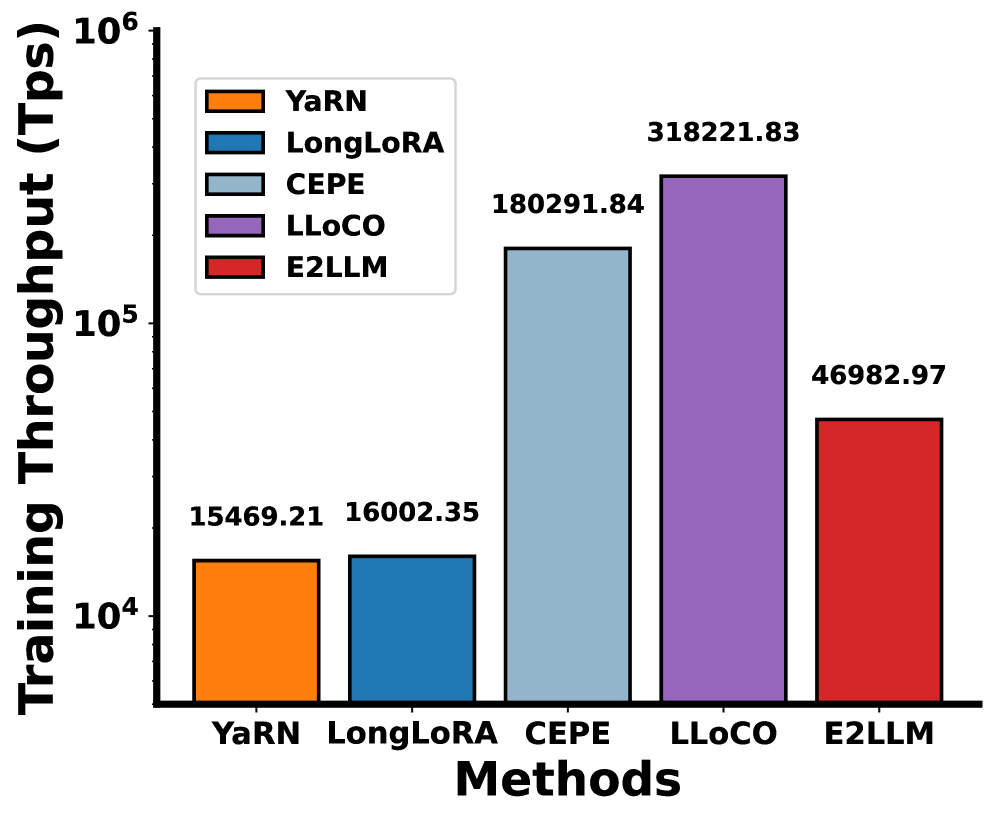
E2LLM在文档摘要和问答任务中取得了显著的性能提升,优于8种最先进的方法。在LongBench v2基准测试中,E2LLM在同等规模的模型中取得了最佳性能,证明了其在长文本处理方面的有效性。例如,在某些任务上,E2LLM的性能比现有方法提高了10%以上。
🎯 应用场景
E2LLM在多个领域具有广泛的应用前景,包括文档摘要、问答系统、代码生成、多轮对话等。该方法可以帮助用户快速理解和处理大量文本信息,提高工作效率。此外,E2LLM还可以应用于知识图谱构建、信息抽取等任务,为人工智能领域的发展做出贡献。
📄 摘要(原文)
Processing long contexts is increasingly important for Large Language Models (LLMs) in tasks like multi-turn dialogues, code generation, and document summarization. This paper addresses the challenges of achieving high long-context performance, low computational complexity, and compatibility with pretrained models -- collectively termed the ``impossible triangle''. We introduce E2LLM (Encoder Elongated Large Language Models), a novel approach that effectively navigates this paradox. E2LLM divides long contexts into chunks, compresses each into soft prompts using a pretrained text encoder, and aligns these representations with a decoder-only LLM via an adapter. To enhance the LLM's reasoning with these soft prompts, we employ two training objectives: encoder output reconstruction and long-context instruction fine-tuning. Extensive experiments reveal that E2LLM not only outperforms 8 state-of-the-art (SOTA) methods in effectiveness and efficiency for document summarization and question answering, but also achieves the best performance on LongBench v2 among models of comparable size.