LLaMA-Omni: Seamless Speech Interaction with Large Language Models
作者: Qingkai Fang, Shoutao Guo, Yan Zhou, Zhengrui Ma, Shaolei Zhang, Yang Feng
分类: cs.CL, cs.AI, cs.SD, eess.AS
发布日期: 2024-09-10 (更新: 2025-03-01)
备注: ICLR 2025
💡 一句话要点
LLaMA-Omni:基于开源LLM的无缝语音交互模型,实现低延迟高质量语音对话。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音交互 大型语言模型 端到端模型 低延迟 语音适配器 流式语音解码 开源模型 Llama-3
📋 核心要点
- 现有语音交互模型依赖闭源LLM,且语音交互质量和效率有待提升。
- LLaMA-Omni通过集成语音编码器、适配器、LLM和流式解码器,直接从语音生成语音和文本响应。
- 实验表明,LLaMA-Omni在内容和风格上优于现有模型,响应延迟仅为226ms,训练成本低。
📝 摘要(中文)
本文提出了LLaMA-Omni,一种用于大型语言模型(LLM)低延迟、高质量语音交互的新型模型架构。与传统的基于文本的交互相比,像GPT-4o这样的模型通过语音实现与LLM的实时交互,显著提升了用户体验。然而,如何基于开源LLM构建语音交互模型的研究仍然不足。LLaMA-Omni集成了预训练的语音编码器、语音适配器、LLM和流式语音解码器,无需语音转录,可以直接从语音指令同时生成文本和语音响应,且延迟极低。该模型基于最新的Llama-3.1-8B-Instruct模型构建。为了使模型与语音交互场景对齐,构建了一个名为InstructS2S-200K的数据集,包含20万条语音指令和相应的语音响应。实验结果表明,与之前的语音语言模型相比,LLaMA-Omni在内容和风格上都提供了更好的响应,响应延迟低至226毫秒。此外,LLaMA-Omni的训练仅需4个GPU,耗时不到3天,为未来高效开发语音语言模型铺平了道路。
🔬 方法详解
问题定义:现有语音交互系统通常依赖于闭源的大型语言模型,这限制了研究的开放性和可扩展性。此外,现有的语音交互模型在响应质量、风格以及延迟方面仍有改进空间,尤其是在实时交互场景下,低延迟至关重要。
核心思路:LLaMA-Omni的核心思路是构建一个端到端的语音交互系统,直接从语音输入生成语音和文本输出,避免了中间的语音转录步骤,从而降低延迟。通过引入语音适配器,将语音特征与LLM的文本表示空间对齐,使得LLM能够理解和处理语音指令。
技术框架:LLaMA-Omni的整体架构包括四个主要模块:预训练的语音编码器(Speech Encoder)、语音适配器(Speech Adaptor)、大型语言模型(LLM)和流式语音解码器(Streaming Speech Decoder)。语音编码器负责提取语音特征,语音适配器将语音特征映射到LLM的文本表示空间,LLM根据语音指令生成文本响应,流式语音解码器将文本响应转换为语音输出。整个流程是端到端的,支持低延迟的实时交互。
关键创新:LLaMA-Omni的关键创新在于其端到端的语音交互架构,以及语音适配器的设计。通过直接从语音生成语音和文本,避免了语音转录带来的延迟和错误。语音适配器能够有效地将语音特征与LLM的文本表示空间对齐,使得LLM能够更好地理解和处理语音指令。此外,流式语音解码器的使用进一步降低了延迟,提高了实时交互的性能。
关键设计:LLaMA-Omni基于Llama-3.1-8B-Instruct模型构建,并使用InstructS2S-200K数据集进行训练,该数据集包含20万条语音指令和相应的语音响应。语音适配器的具体结构未知,但其目标是最小化语音特征和LLM文本表示之间的距离。流式语音解码器采用流式处理技术,以降低延迟。损失函数的设计未知,但可能包括文本生成损失和语音合成损失。
🖼️ 关键图片


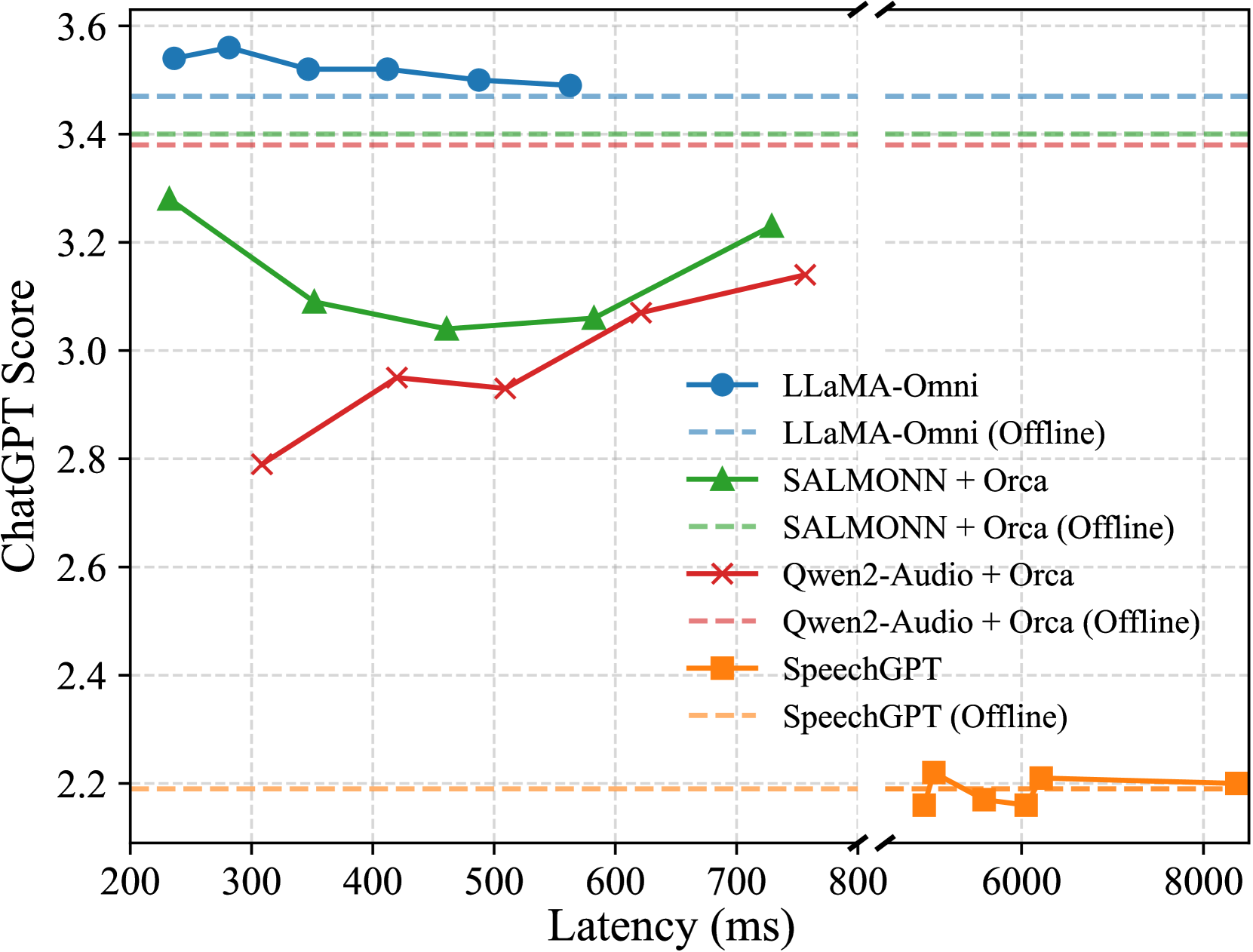
📊 实验亮点
实验结果表明,LLaMA-Omni在语音交互的响应质量和风格上优于现有的语音语言模型。更重要的是,LLaMA-Omni实现了极低的响应延迟,仅为226毫秒,这使得它非常适合实时交互场景。此外,LLaMA-Omni的训练成本相对较低,仅需4个GPU,耗时不到3天,这为未来高效开发语音语言模型铺平了道路。
🎯 应用场景
LLaMA-Omni具有广泛的应用前景,包括智能助手、语音搜索、实时翻译、教育辅导等。它可以应用于各种设备,如智能手机、智能音箱、车载系统等,为用户提供更加自然、便捷的语音交互体验。该研究有助于推动开源语音交互技术的发展,降低语音交互系统的开发成本,促进语音交互技术的普及。
📄 摘要(原文)
Models like GPT-4o enable real-time interaction with large language models (LLMs) through speech, significantly enhancing user experience compared to traditional text-based interaction. However, there is still a lack of exploration on how to build speech interaction models based on open-source LLMs. To address this, we propose LLaMA-Omni, a novel model architecture designed for low-latency and high-quality speech interaction with LLMs. LLaMA-Omni integrates a pretrained speech encoder, a speech adaptor, an LLM, and a streaming speech decoder. It eliminates the need for speech transcription, and can simultaneously generate text and speech responses directly from speech instructions with extremely low latency. We build our model based on the latest Llama-3.1-8B-Instruct model. To align the model with speech interaction scenarios, we construct a dataset named InstructS2S-200K, which includes 200K speech instructions and corresponding speech responses. Experimental results show that compared to previous speech-language models, LLaMA-Omni provides better responses in both content and style, with a response latency as low as 226ms. Additionally, training LLaMA-Omni takes less than 3 days on just 4 GPUs, paving the way for the efficient development of speech-language models in the future.