A Practice of Post-Training on Llama-3 70B with Optimal Selection of Additional Language Mixture Ratio
作者: Ningyuan Xi, Yetao Wu, Kun Fan, Teng Chen, Qingqing Gu, Luo Ji
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-09-10 (更新: 2025-08-09)
备注: 12 pages, 2 figures
💡 一句话要点
针对Llama-3 70B,通过优化语言混合比例进行后训练,提升中文能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 持续预训练 语言混合比例 中文能力提升 超参数优化
📋 核心要点
- 持续预训练(CPT)是提升LLM在特定语言或领域能力的关键,但其高昂的计算成本限制了超参数的探索。
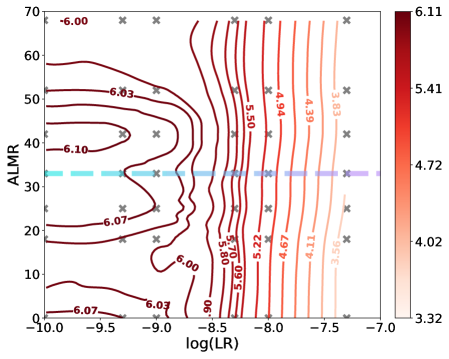
- 该论文通过在较小模型上探索额外语言混合比例(ALMR)与学习率(LR)的最佳关系,指导大型模型的训练。
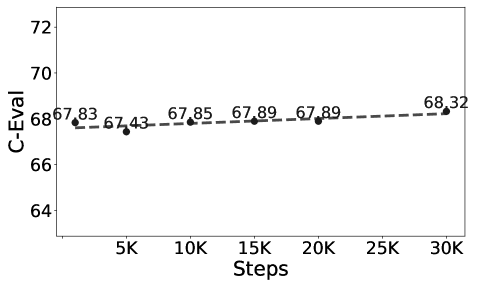
- 实验表明,优化后的模型在中文基准测试以及数学、编码和情商等领域均有提升,并在实际聊天系统中表现良好。
📝 摘要(中文)
大型语言模型(LLM)通常需要持续预训练(CPT)以获得不熟悉的语言技能或适应新的领域。CPT的巨大训练成本通常需要谨慎选择关键超参数,例如额外语言或领域语料库的混合比例。然而,目前还没有系统的研究能够弥合最佳混合比例与实际模型性能之间的差距,以及实验缩放定律与完整模型尺寸的实际部署之间的差距。在本文中,我们对Llama-3 8B和70B进行CPT,以增强其中文能力。我们研究了8B尺寸上额外语言混合比例(ALMR)与学习率(LR)之间的最佳相关性,这直接指示了最佳实验设置。通过彻底选择超参数和后续的微调,模型的能力不仅在中文相关基准上得到提高,而且在包括数学、编码和情商在内的一些特定领域也得到了提高。我们将最终的70B版本的LLM部署在实际的聊天系统中,获得了令人满意的性能。
🔬 方法详解
问题定义:现有的大型语言模型在特定语言(如中文)或领域上的能力不足,需要通过持续预训练(CPT)来提升。然而,CPT的计算成本很高,尤其是对于大型模型,因此如何有效地选择训练数据混合比例(如额外语言的比例)是一个关键问题。现有方法缺乏对混合比例与模型性能之间关系的系统研究,以及从小规模实验到大规模部署的有效迁移策略。
核心思路:该论文的核心思路是在较小的模型(Llama-3 8B)上进行实验,探索额外语言混合比例(ALMR)与学习率(LR)之间的最佳关系。通过找到最佳的超参数设置,并将这些设置迁移到更大的模型(Llama-3 70B)上进行训练,从而在降低计算成本的同时,提升模型的性能。这种方法旨在弥合实验缩放定律与实际部署之间的差距。
技术框架:该论文的技术框架主要包括以下几个阶段:1) 在Llama-3 8B上进行CPT实验,探索ALMR和LR的不同组合,并评估模型在中文相关任务上的性能。2) 基于8B模型的实验结果,选择最佳的ALMR和LR组合。3) 将最佳的超参数设置应用于Llama-3 70B的CPT。4) 对CPT后的70B模型进行微调,进一步提升其性能。5) 将最终的70B模型部署到实际的聊天系统中进行评估。
关键创新:该论文的关键创新在于系统地研究了额外语言混合比例(ALMR)与学习率(LR)之间的关系,并提出了从小规模实验到大规模部署的迁移策略。通过在较小模型上进行充分的实验,找到最佳的超参数设置,然后将其应用于更大的模型,从而在降低计算成本的同时,提升模型的性能。此外,该论文还关注了模型在多个领域的性能,包括数学、编码和情商等。
关键设计:论文的关键设计包括:1) 对ALMR和LR进行网格搜索,探索不同的组合。2) 使用中文相关的基准测试来评估模型的性能。3) 在多个领域(包括数学、编码和情商)上评估模型的性能。4) 将最终的70B模型部署到实际的聊天系统中进行评估。具体的参数设置和损失函数等技术细节在论文中可能没有详细描述,需要参考相关的文献。
🖼️ 关键图片
📊 实验亮点
该研究通过优化额外语言混合比例和学习率,成功提升了Llama-3 70B的中文能力,并在数学、编码和情商等领域也取得了显著的性能提升。最终的70B模型在实际聊天系统中获得了令人满意的性能,验证了该方法的有效性。
🎯 应用场景
该研究成果可应用于各种需要提升特定语言或领域能力的大型语言模型。例如,可以用于构建更智能的中文聊天机器人、提升机器翻译的质量、以及开发在特定领域(如医疗、金融)具有专业知识的AI助手。通过优化训练数据的混合比例,可以更有效地利用计算资源,提升模型的性能和泛化能力。
📄 摘要(原文)
Large Language Models (LLM) often need to be Continual Pre-Trained (CPT) to obtain unfamiliar language skills or adapt to new domains. The huge training cost of CPT often asks for cautious choice of key hyper-parameters such as the mixture ratio of extra language or domain corpus. However, there is no systematic study that bridges the gap between the optimal mixture ratio and the actual model performance, and the gap between experimental scaling law and the actual deployment in the full model size. In this paper, we perform CPT on Llama-3 8B and 70B to enhance its Chinese ability. We study the optimal correlation between the Additional Language Mixture Ratio (ALMR) and the Learning Rate (LR) on the 8B size which directly indicates the optimal experimental setup. By thorough choice of hyper-parameter, and subsequent fine-tuning, the model capability is improved not only on the Chinese-related benchmark but also in some specific domains including math, coding, and emotional intelligence. We deploy the final 70B version of LLM on a real-life chat system which obtains satisfying performance.