Medal Matters: Probing LLMs' Failure Cases Through Olympic Rankings
作者: Juhwan Choi, Seunguk Yu, JungMin Yun, YoungBin Kim
分类: cs.CL, cs.AI
发布日期: 2024-09-10 (更新: 2026-01-22)
备注: COLM 2025 ORIGen Workshop
💡 一句话要点
通过奥运奖牌榜探究大语言模型在排序推理上的失败案例
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 知识推理 排序学习 奥运奖牌榜 知识表示
📋 核心要点
- 现有大语言模型在知识推理方面存在不足,尤其是在需要排序和比较的任务中。
- 该研究利用奥运奖牌榜作为知识探针,评估LLMs在奖牌数量检索和排名识别上的能力。
- 实验表明,LLMs擅长奖牌数量回忆,但在排名识别上表现不佳,揭示了其知识整合的局限性。
📝 摘要(中文)
大型语言模型(LLMs)在自然语言处理任务中取得了显著成功,但其内部知识结构仍然知之甚少。本研究通过历史奥运奖牌榜来检验这些结构,评估LLMs在两项任务上的表现:(1)检索特定队伍的奖牌数量;(2)识别每个队伍的排名。虽然最先进的LLMs在回忆奖牌数量方面表现出色,但它们在提供排名方面表现不佳,突出了它们的知识组织与人类推理之间的关键差异。这些发现揭示了LLMs内部知识整合的局限性,并为改进方向提供了建议。为了方便进一步研究,我们发布了我们的代码、数据集和模型输出。
🔬 方法详解
问题定义:论文旨在探究大型语言模型(LLMs)在知识推理方面的局限性,特别是它们在处理需要排序和比较信息的任务时的表现。现有方法虽然在知识检索方面表现良好,但在进行更复杂的推理(例如排名)时,其内部知识表示和推理机制的不足之处就会暴露出来。奥运奖牌榜提供了一个结构化的知识来源,可以用来系统地评估LLMs的推理能力。
核心思路:论文的核心思路是利用奥运奖牌榜的结构化数据,通过设计特定的任务来评估LLMs的知识表示和推理能力。具体来说,通过考察LLMs在检索奖牌数量和进行排名推理时的表现,来揭示其内部知识组织方式与人类推理之间的差异。这种方法能够更清晰地诊断LLMs在知识整合和推理方面的弱点。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 构建包含奥运奖牌榜的数据集;2) 设计两个评估任务:奖牌数量检索和排名识别;3) 使用多个LLMs(包括最先进的模型)进行实验;4) 分析LLMs在两个任务上的表现差异,并从中推断其内部知识结构的特点。没有涉及复杂的模型训练或微调。
关键创新:该研究的关键创新在于使用奥运奖牌榜作为一种新颖的知识探针,来评估LLMs的知识推理能力。与以往的研究不同,该研究侧重于考察LLMs在排序推理方面的表现,并揭示了其在知识整合方面的局限性。这种方法为理解LLMs的内部知识结构提供了一种新的视角。
关键设计:该研究的关键设计在于两个评估任务的设计。奖牌数量检索任务主要考察LLMs的知识记忆能力,而排名识别任务则需要LLMs进行更复杂的推理。通过比较LLMs在两个任务上的表现,可以更清晰地揭示其在知识整合和推理方面的弱点。具体参数设置和损失函数取决于所使用的LLM本身,论文侧重于评估而非训练。
🖼️ 关键图片
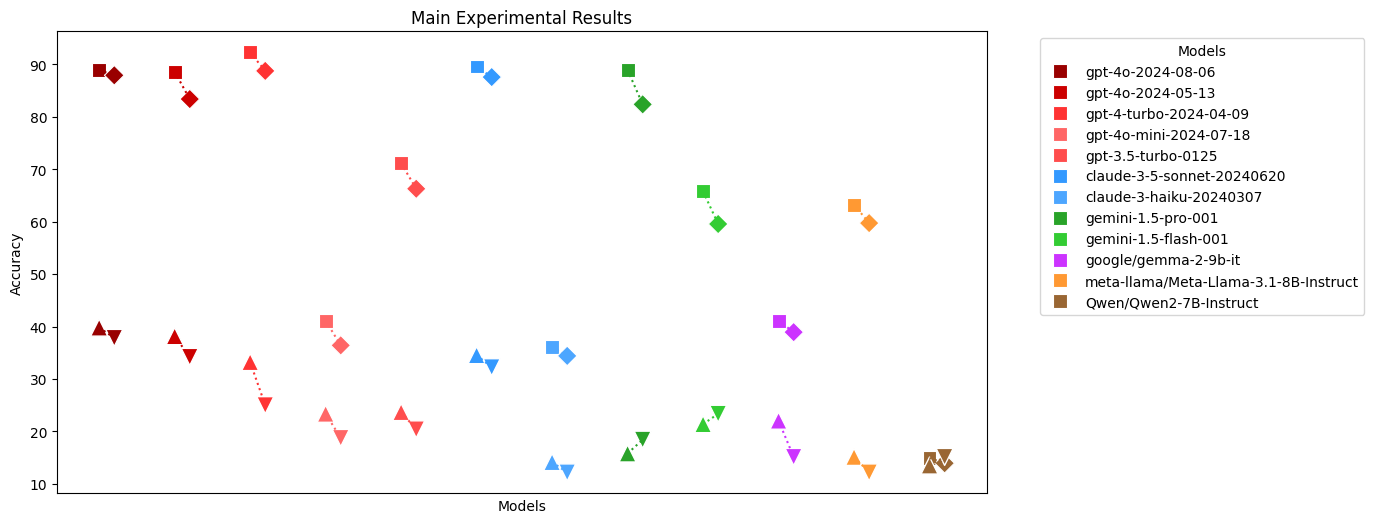
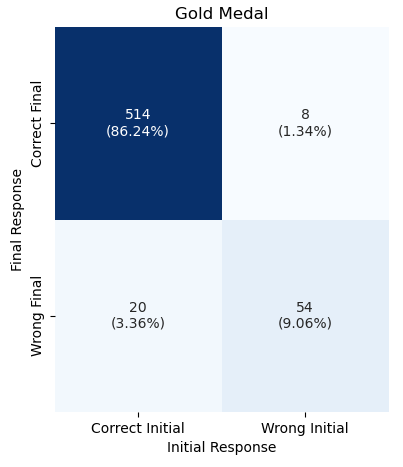

📊 实验亮点
实验结果表明,最先进的LLMs在奖牌数量检索任务上表现出色,但在排名识别任务上表现不佳。例如,LLMs可以准确地回答某个国家获得了多少枚金牌,但在确定该国家在所有参赛国家中的排名时,准确率显著下降。这表明LLMs在知识整合和排序推理方面存在明显的局限性。
🎯 应用场景
该研究的成果可以应用于改进LLMs的知识表示和推理能力,使其在需要排序和比较信息的任务中表现更好。例如,可以应用于信息检索、推荐系统、问答系统等领域,提高LLMs的准确性和可靠性。未来的研究可以探索如何利用结构化知识来增强LLMs的推理能力。
📄 摘要(原文)
Large language models (LLMs) have achieved remarkable success in natural language processing tasks, yet their internal knowledge structures remain poorly understood. This study examines these structures through the lens of historical Olympic medal tallies, evaluating LLMs on two tasks: (1) retrieving medal counts for specific teams and (2) identifying rankings of each team. While state-of-the-art LLMs excel in recalling medal counts, they struggle with providing rankings, highlighting a key difference between their knowledge organization and human reasoning. These findings shed light on the limitations of LLMs' internal knowledge integration and suggest directions for improvement. To facilitate further research, we release our code, dataset, and model outputs.