Can Large Language Models Unlock Novel Scientific Research Ideas?
作者: Sandeep Kumar, Tirthankar Ghosal, Vinayak Goyal, Asif Ekbal
分类: cs.CL, cs.AI, cs.CY, cs.HC, cs.LG
发布日期: 2024-09-10 (更新: 2025-10-27)
备注: EMNLP 2025 (Main)
💡 一句话要点
评估大语言模型生成科研新思路能力,并提出自动评估指标IAScore和Idea Distinctness Index
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 科研思路生成 自动评估指标 自然语言处理 人工智能
📋 核心要点
- 现有方法在评估LLM生成科研思路时依赖人工评估,但人工评估成本高昂、耗时且难以扩展。
- 论文提出两种自动评估指标:Idea Alignment Score (IAScore) 和 Idea Distinctness Index,以解决人工评估的局限性。
- 通过人工评估验证了自动评估指标的有效性,并分析了LLM在科研思路生成方面的能力和局限性。
📝 摘要(中文)
大型语言模型(LLMs)的广泛应用,特别是ChatGPT的出现,标志着人工智能(AI)融入人们日常生活的一个重要转折点。本研究探讨了大型语言模型(LLMs)从科学论文中生成未来研究思路的能力。与摘要或翻译等任务不同,思路生成缺乏明确定义的参考集或结构,使得人工评估成为默认标准。然而,在这种情况下的人工评估极具挑战性,即:它需要大量的领域专业知识、对论文的上下文理解以及对当前研究格局的了解。这使得它耗时、成本高且从根本上不可扩展,尤其是在新型LLM快速发布的情况下。目前,没有专门为此任务设计的自动评估指标。为了解决这个差距,我们提出了两个自动评估指标:思路对齐分数(IAScore)和思路区分度指数。我们还进行了人工评估,以评估生成的未来研究思路的新颖性、相关性和可行性。这项调查深入了解了LLM在思路生成中不断变化的角色,突出了它的能力和局限性。我们的工作有助于评估和利用语言模型生成未来研究思路的持续努力。我们将公开提供我们的数据集和代码。
🔬 方法详解
问题定义:论文旨在解决如何有效评估大型语言模型(LLMs)生成科研新思路的能力。现有方法主要依赖人工评估,但人工评估需要大量的领域知识、上下文理解,并且耗时耗力,难以规模化应用。因此,亟需一种自动化的评估方法来衡量LLM生成科研思路的质量。
核心思路:论文的核心思路是设计自动化的评估指标,从对齐性和区分度两个方面来衡量LLM生成的科研思路的质量。对齐性是指生成的思路与原始论文的相关程度,区分度是指生成的思路与其他思路的差异程度。通过这两个指标,可以较为全面地评估LLM生成科研思路的优劣。
技术框架:论文的技术框架主要包括以下几个部分:1)使用LLM生成科研思路;2)提出Idea Alignment Score (IAScore) 和 Idea Distinctness Index两种自动评估指标;3)进行人工评估,验证自动评估指标的有效性;4)分析LLM在科研思路生成方面的能力和局限性。
关键创新:论文的关键创新在于提出了两种新的自动评估指标:IAScore和Idea Distinctness Index。IAScore通过计算生成思路与原始论文之间的语义相似度来衡量对齐性。Idea Distinctness Index通过计算生成思路之间的语义差异来衡量区分度。这两种指标能够有效地评估LLM生成科研思路的质量,并且可以自动化地进行评估,大大降低了评估成本。
关键设计:IAScore的具体计算方法是:首先将生成思路和原始论文分别编码成向量表示,然后计算两个向量之间的余弦相似度。Idea Distinctness Index的具体计算方法是:首先将所有生成思路编码成向量表示,然后计算每两个向量之间的余弦相似度,最后计算所有相似度的平均值。
🖼️ 关键图片

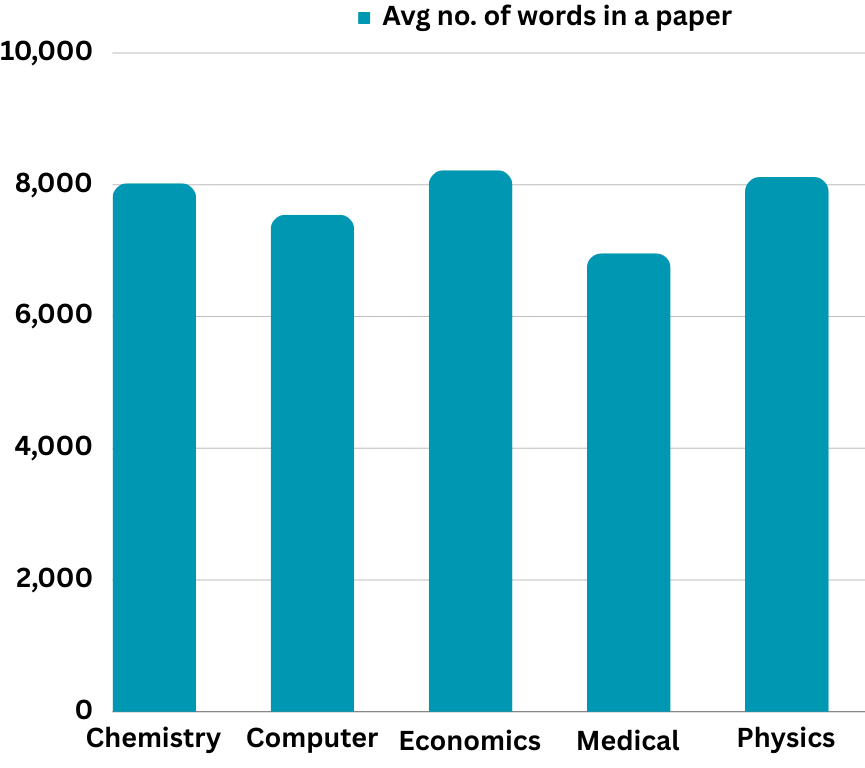
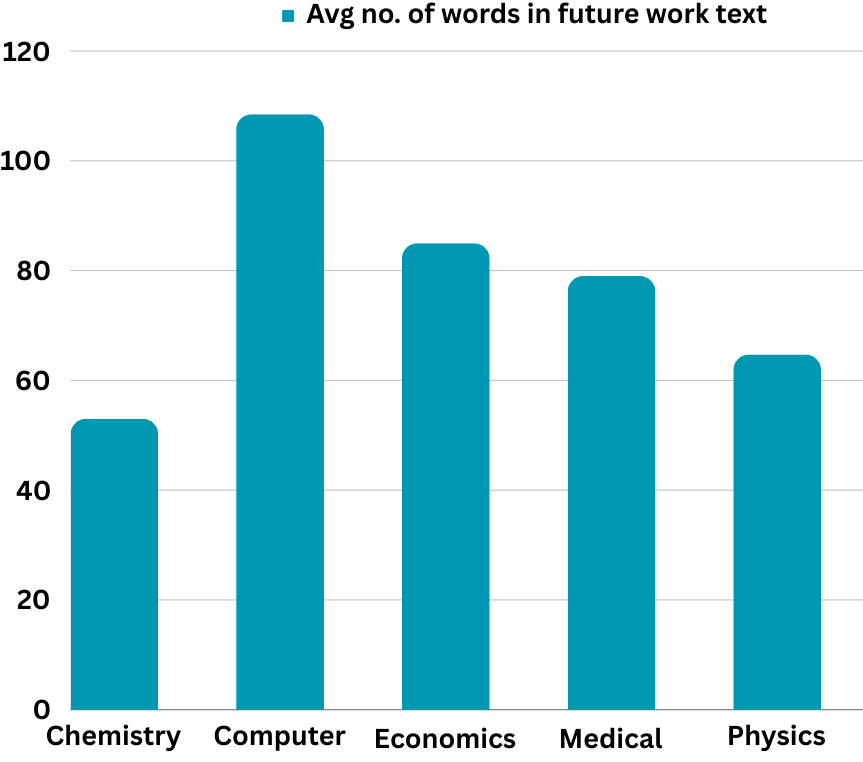
📊 实验亮点
论文提出了两种自动评估指标IAScore和Idea Distinctness Index,并通过人工评估验证了其有效性。实验结果表明,这些指标能够较好地反映LLM生成科研思路的质量。此外,论文还分析了LLM在科研思路生成方面的优势和不足,为未来研究提供了有价值的参考。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型在科研领域的应用,例如辅助科研人员进行文献调研、生成新的研究假设、加速科研创新过程。自动评估指标的提出,降低了评估成本,使得大规模评估LLM生成科研思路的能力成为可能,从而推动LLM在科研领域的更广泛应用。
📄 摘要(原文)
The widespread adoption of Large Language Models (LLMs) and publicly available ChatGPT have marked a significant turning point in the integration of Artificial Intelligence (AI) into people's everyday lives. This study examines the ability of Large Language Models (LLMs) to generate future research ideas from scientific papers. Unlike tasks such as summarization or translation, idea generation lacks a clearly defined reference set or structure, making manual evaluation the default standard. However, human evaluation in this setting is extremely challenging ie: it requires substantial domain expertise, contextual understanding of the paper, and awareness of the current research landscape. This makes it time-consuming, costly, and fundamentally non-scalable, particularly as new LLMs are being released at a rapid pace. Currently, there is no automated evaluation metric specifically designed for this task. To address this gap, we propose two automated evaluation metrics: Idea Alignment Score (IAScore) and Idea Distinctness Index. We further conducted human evaluation to assess the novelty, relevance, and feasibility of the generated future research ideas. This investigation offers insights into the evolving role of LLMs in idea generation, highlighting both its capability and limitations. Our work contributes to the ongoing efforts in evaluating and utilizing language models for generating future research ideas. We make our datasets and codes publicly available