CKnowEdit: A New Chinese Knowledge Editing Dataset for Linguistics, Facts, and Logic Error Correction in LLMs
作者: Jizhan Fang, Tianhe Lu, Yunzhi Yao, Ziyan Jiang, Xin Xu, Huajun Chen, Ningyu Zhang
分类: cs.CL, cs.AI, cs.IR, cs.LG
发布日期: 2024-09-09 (更新: 2025-06-01)
备注: ACL 2025; project website is available at https://zjunlp.github.io/project/CKnowEdit code and dataset are available at https://github.com/zjunlp/EasyEdit
🔗 代码/项目: GITHUB
💡 一句话要点
CKnowEdit:首个中文知识编辑数据集,用于修正LLM中的语言、事实和逻辑错误
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 中文知识编辑 大型语言模型 知识图谱 自然语言处理 数据集构建
📋 核心要点
- 现有大型语言模型在处理包含丰富文化内涵的中文知识时存在不足,例如古代诗歌和成语。
- CKnowEdit数据集旨在通过提供针对性的训练优化,评估、持续更新和逐步提高LLM的中文语言能力。
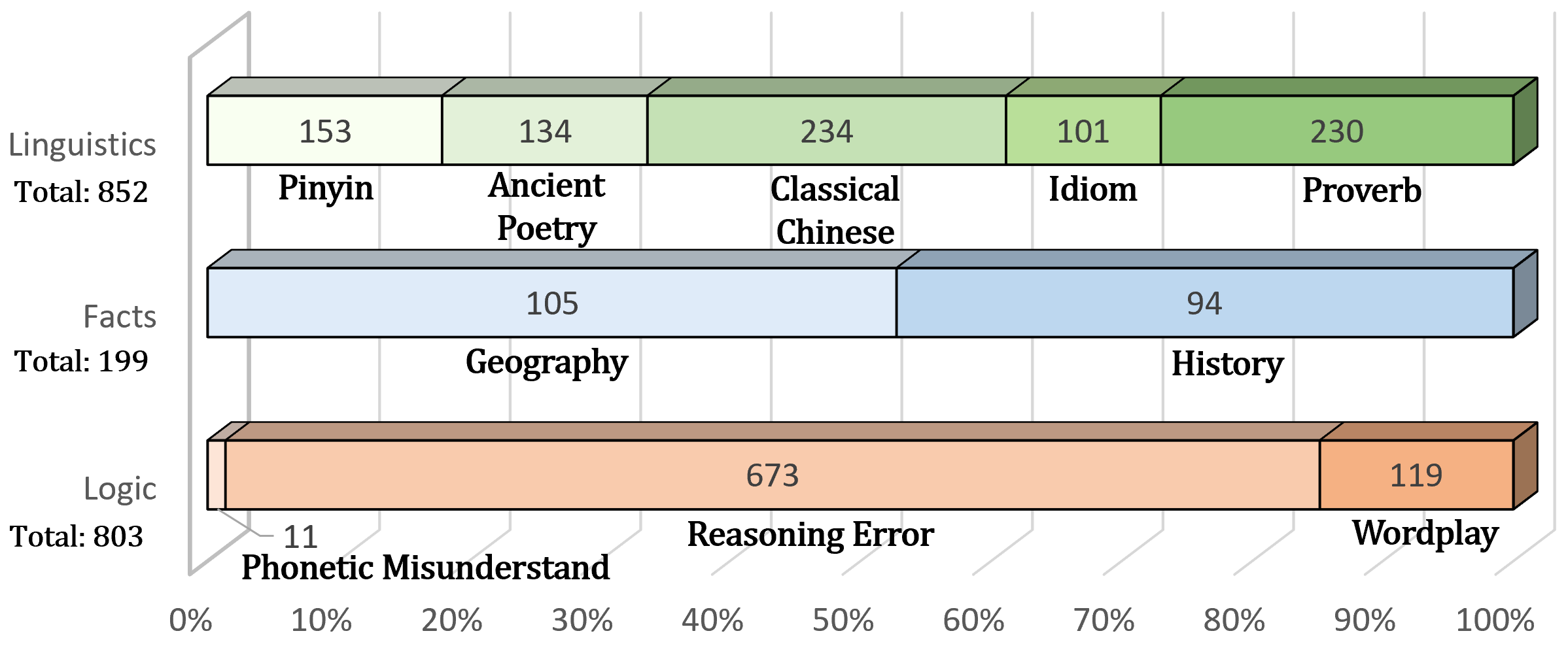
- 该数据集包含七种类型的知识,并考虑了中文特有的多音字、对仗和逻辑结构等特点。
📝 摘要(中文)
本文提出了CKnowEdit,这是首个中文知识编辑数据集,旨在修正大型语言模型(LLM)中存在的语言、事实和逻辑错误。中文作为一种具有深度和复杂性的语言系统,拥有独特的文化元素,如古代诗歌、谚语、成语等。然而,当前的LLM在这些专业领域面临局限性。CKnowEdit通过收集来自古典文本、成语和百度贴吧等广泛来源的七种类型的知识,并考虑到汉语中特有的多音字、对仗和逻辑结构,填补了这一空白。通过分析该数据集,我们强调了当前LLM在掌握中文方面面临的挑战。此外,我们对最先进的知识编辑技术的评估揭示了推进中文知识修正的机会。代码和数据集可在https://github.com/zjunlp/EasyEdit获取。
🔬 方法详解
问题定义:当前的大型语言模型在处理和理解包含丰富文化背景的中文知识时表现出明显的局限性,尤其是在语言、事实和逻辑层面容易出错。现有的知识编辑方法难以有效修正这些错误,痛点在于缺乏专门针对中文语言特点和知识结构的评估和训练数据集。
核心思路:CKnowEdit的核心思路是构建一个高质量、多样化的中文知识编辑数据集,该数据集不仅覆盖了广泛的知识领域,还充分考虑了中文语言的独特性,如多音字、对仗结构和逻辑关系。通过在该数据集上训练和评估知识编辑方法,可以有效提升LLM对中文知识的掌握和运用能力。
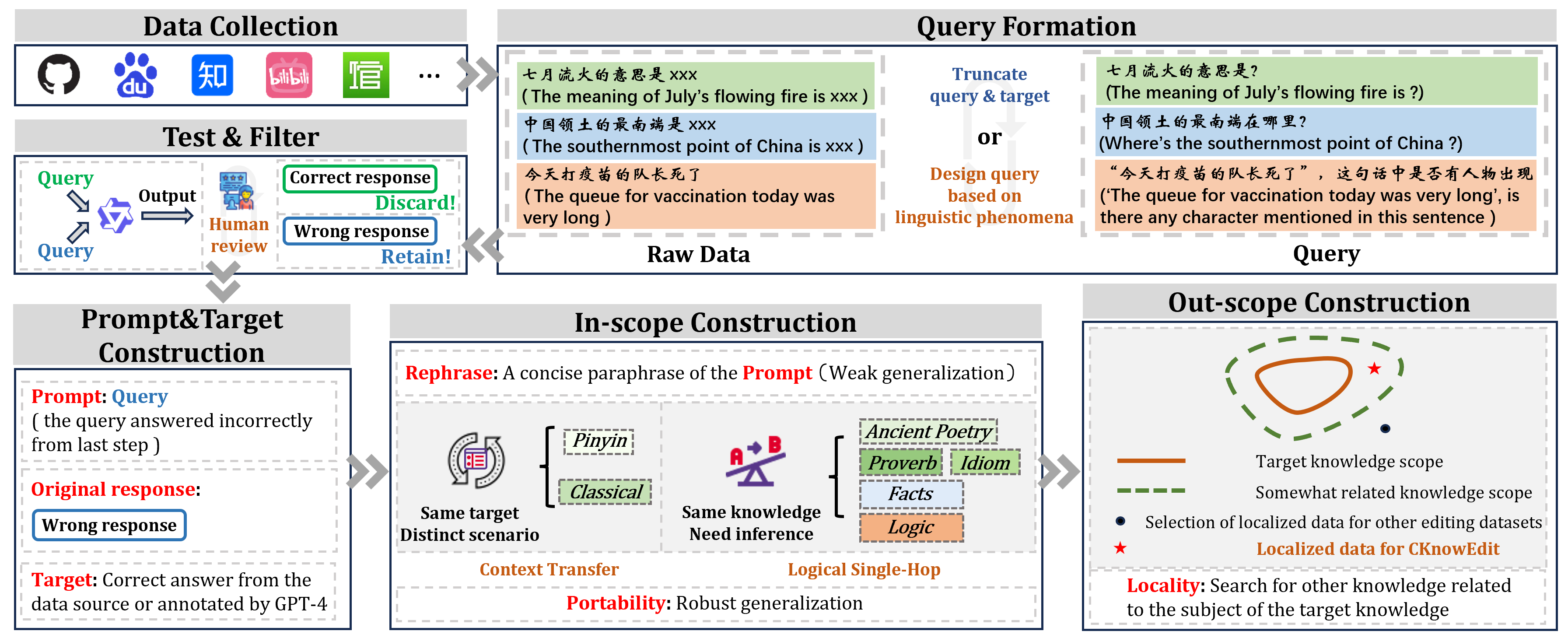
技术框架:CKnowEdit数据集的构建流程主要包括以下几个阶段:1) 知识来源选择:从古典文本、成语词典、百度贴吧等多种渠道收集知识;2) 知识类型划分:将知识分为七种类型,包括语言、事实和逻辑等;3) 数据标注与清洗:对收集到的知识进行人工标注和清洗,确保数据的准确性和一致性;4) 数据集构建与发布:将标注和清洗后的数据整理成统一的格式,并发布数据集。
关键创新:CKnowEdit最重要的技术创新点在于它是首个专门针对中文知识编辑的数据集。与现有的通用知识编辑数据集相比,CKnowEdit更加关注中文语言的特点和文化背景,能够更有效地评估和提升LLM的中文知识处理能力。
关键设计:在数据集构建过程中,作者们特别关注了以下几个关键设计:1) 知识来源的多样性,确保数据集覆盖了广泛的知识领域;2) 知识类型的细粒度划分,方便针对不同类型的错误进行修正;3) 数据标注的严格性,保证数据的准确性和可靠性;4) 数据格式的统一性,方便不同的知识编辑方法进行使用。
🖼️ 关键图片

📊 实验亮点
该论文构建了首个中文知识编辑数据集CKnowEdit,包含七种类型的知识,并考虑了中文语言的独特性。通过对现有知识编辑技术在该数据集上的评估,揭示了LLM在中文知识处理方面面临的挑战,并为未来的研究方向提供了指导。具体性能数据和对比基线在论文中进行了详细展示。
🎯 应用场景
CKnowEdit数据集可广泛应用于提升中文大型语言模型的知识掌握和推理能力,例如智能问答、知识图谱构建、机器翻译等领域。该数据集有助于开发更准确、更可靠的中文自然语言处理系统,并促进中文文化知识的传承和传播。未来,可以基于该数据集进一步研究中文知识的表示、推理和更新方法。
📄 摘要(原文)
Chinese, as a linguistic system rich in depth and complexity, is characterized by distinctive elements such as ancient poetry, proverbs, idioms, and other cultural constructs. However, current Large Language Models (LLMs) face limitations in these specialized domains, highlighting the need for the development of comprehensive datasets that can assess, continuously update, and progressively improve these culturally-grounded linguistic competencies through targeted training optimizations. To address this gap, we introduce CKnowEdit, the first-ever Chinese knowledge editing dataset designed to correct linguistic, factual, and logical errors in LLMs. We collect seven types of knowledge from a wide range of sources, including classical texts, idioms, and content from Baidu Tieba Ruozhiba, taking into account the unique polyphony, antithesis, and logical structures inherent in the Chinese language. By analyzing this dataset, we highlight the challenges current LLMs face in mastering Chinese. Furthermore, our evaluation of state-of-the-art knowledge editing techniques reveals opportunities to advance the correction of Chinese knowledge. Code and dataset are available at https://github.com/zjunlp/EasyEdit.