MemoRAG: Boosting Long Context Processing with Global Memory-Enhanced Retrieval Augmentation
作者: Hongjin Qian, Zheng Liu, Peitian Zhang, Kelong Mao, Defu Lian, Zhicheng Dou, Tiejun Huang
分类: cs.CL, cs.AI
发布日期: 2024-09-09 (更新: 2025-04-09)
备注: theWebConf 2025. Codes and models are in https://github.com/qhjqhj00/MemoRAG
💡 一句话要点
提出MemoRAG,通过全局记忆增强检索提升长文本处理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本处理 检索增强生成 全局记忆 知识检索 大型语言模型
📋 核心要点
- 大型语言模型处理长文本时面临计算成本高昂和上下文信息不足的挑战。
- MemoRAG通过构建全局记忆并利用草稿答案提供检索线索,增强RAG在长文本中的检索能力。
- 实验表明,MemoRAG在多种长文本任务中表现优异,超越了传统RAG方法。
📝 摘要(中文)
处理长文本对大型语言模型(LLMs)提出了重大挑战。尽管最近的进展使LLMs能够处理比以前更长的上下文(例如,32K或128K tokens),但这在计算上是昂贵的,并且对于许多应用来说仍然可能不足。检索增强生成(RAG)被认为是解决这个问题的一个有希望的策略。然而,传统的RAG方法由于两个基本要求而面临固有的局限性:1)明确陈述的查询,以及2)结构良好的知识。然而,这些条件在一般的长文本处理任务中并不成立。在这项工作中,我们提出了MemoRAG,一种由全局记忆增强检索提供支持的新型RAG框架。MemoRAG具有双系统架构。首先,它采用一个轻量但长程的系统来创建长文本的全局记忆。一旦出现任务,它会生成草稿答案,为检索工具提供有用的线索,以在长文本中定位相关信息。其次,它利用一个昂贵但富有表现力的系统,该系统基于检索到的信息生成最终答案。在此基本框架的基础上,我们以KV压缩的形式实现记忆模块,并通过生成质量的反馈(也称为RLGF)来增强其记忆和线索能力。在我们的实验中,MemoRAG在各种长文本评估任务中取得了优异的性能,不仅在传统RAG方法难以应对的复杂场景中,而且在通常应用RAG的更简单场景中也是如此。
🔬 方法详解
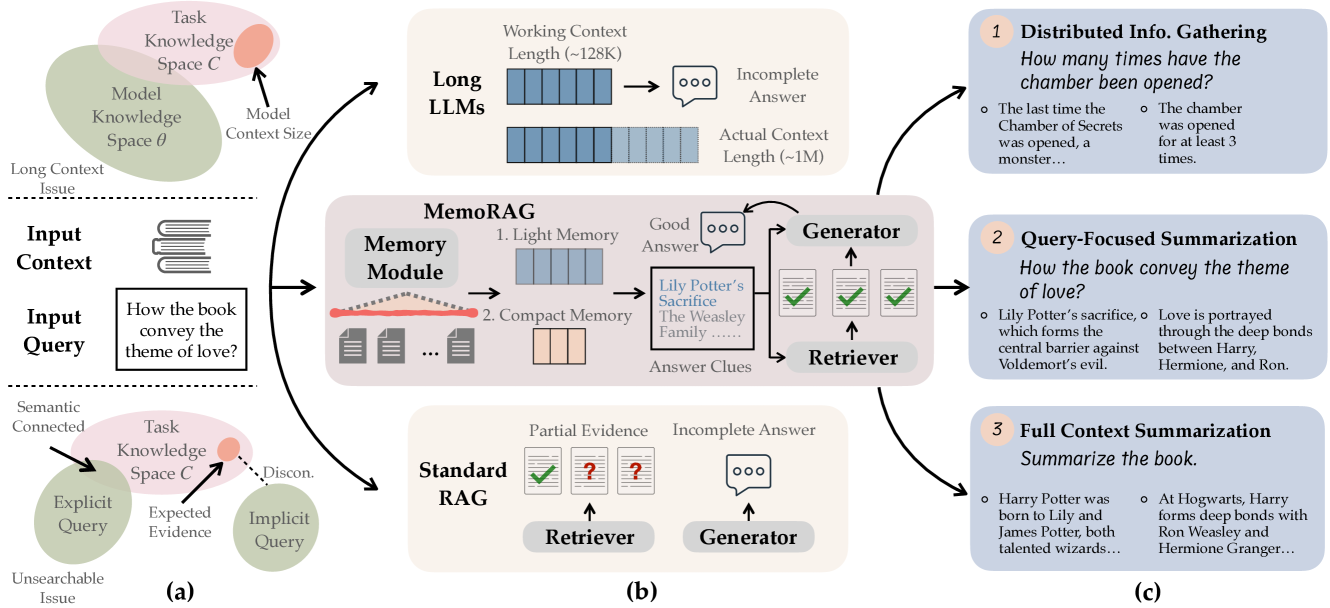
问题定义:现有RAG方法在处理长文本时,依赖于明确的查询和结构化的知识,这在许多实际长文本处理任务中并不成立。传统RAG难以有效利用长文本中的上下文信息,导致检索效果不佳,最终影响生成质量。此外,直接处理超长文本的计算成本非常高昂。
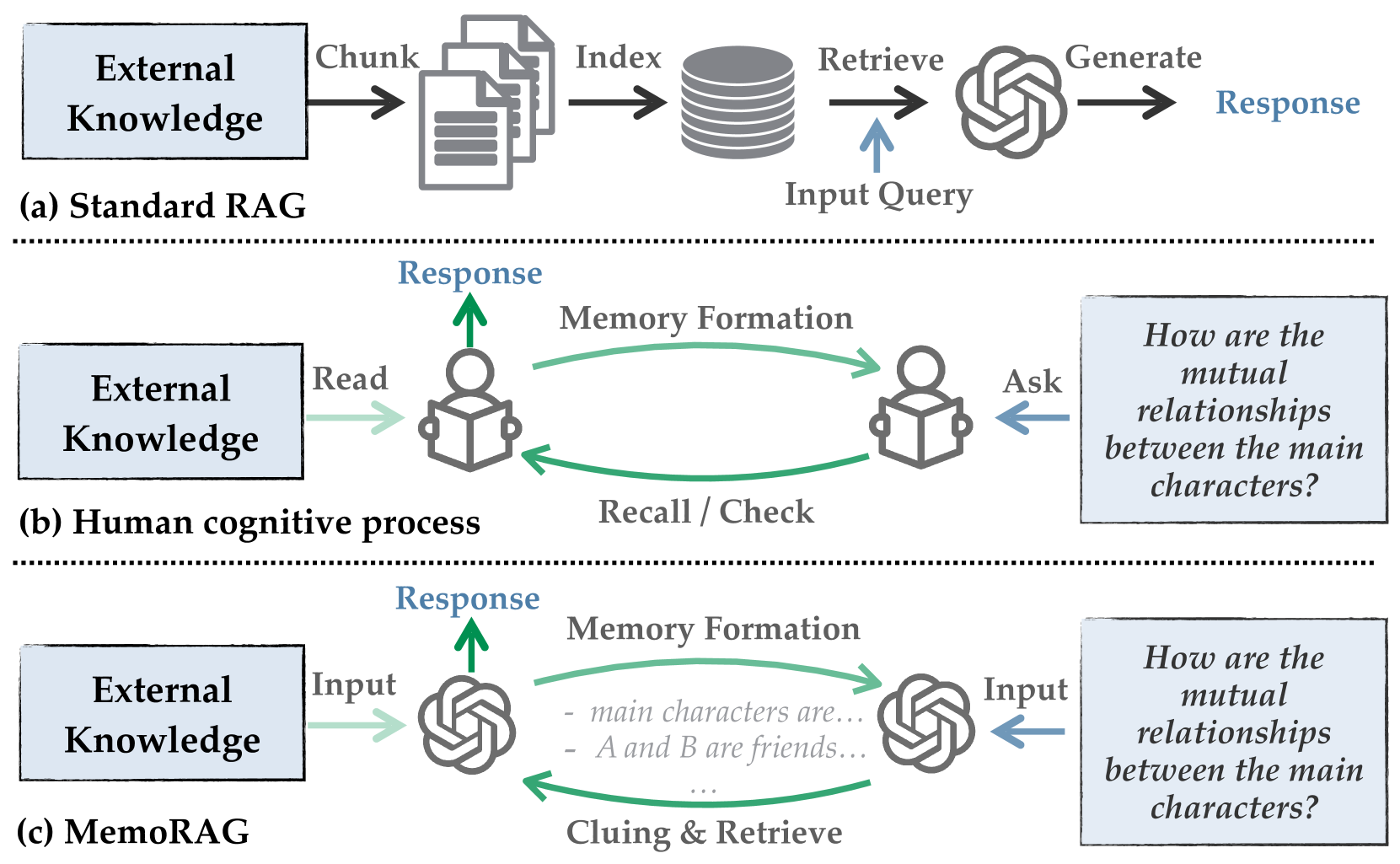
核心思路:MemoRAG的核心思路是利用一个轻量级的“记忆”模块来概括长文本的全局信息,并生成草稿答案作为检索的线索。这个“记忆”模块可以看作是对长文本的一种压缩表示,它能够帮助检索器更准确地找到与任务相关的段落。通过将检索范围缩小到与草稿答案相关的部分,可以显著提高检索效率和准确性。
技术框架:MemoRAG采用双系统架构。第一个系统是一个轻量级的长程模型,负责读取整个长文本,并构建全局记忆(以KV压缩的形式)。当接收到任务时,该系统生成草稿答案,为后续的检索提供线索。第二个系统是一个更强大的语言模型,它基于检索到的信息生成最终答案。整个流程包括:1) 长文本输入;2) 轻量级模型构建全局记忆并生成草稿答案;3) 检索器根据草稿答案从长文本中检索相关信息;4) 强大的语言模型基于检索到的信息生成最终答案。
关键创新:MemoRAG的关键创新在于引入了全局记忆增强的检索机制。与传统RAG直接基于查询进行检索不同,MemoRAG利用轻量级模型生成的草稿答案作为检索的线索,从而更好地利用长文本的上下文信息。此外,通过KV压缩的方式构建全局记忆,可以有效地降低计算成本。
关键设计:MemoRAG使用KV压缩来构建全局记忆,具体实现方式未知(论文中未详细说明)。此外,论文还提到使用来自生成质量的反馈(RLGF)来增强记忆模块的记忆和线索能力,但具体实现细节也未知。
🖼️ 关键图片
📊 实验亮点
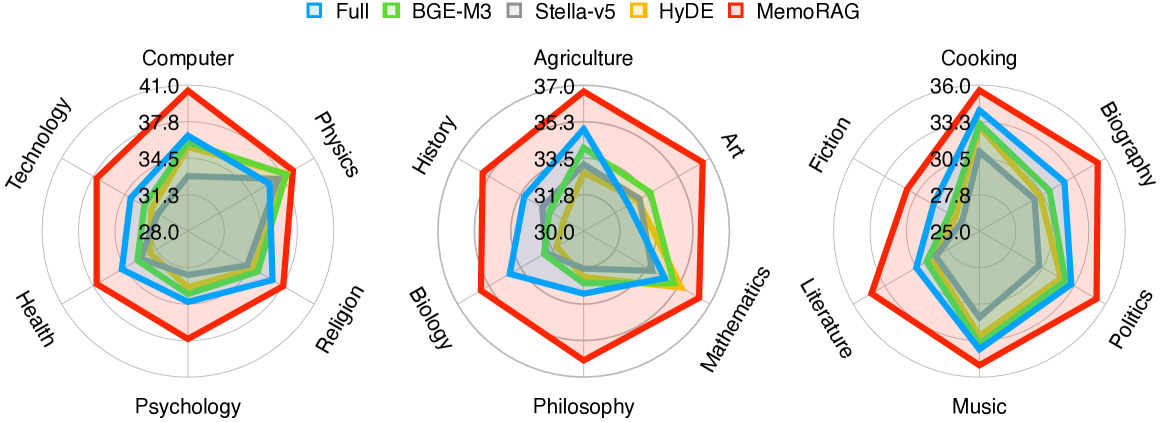
MemoRAG在多个长文本评估任务中取得了优异的性能,表明其在复杂和简单场景下均优于传统RAG方法。虽然论文中没有提供具体的性能数据和提升幅度,但强调了MemoRAG在传统RAG方法难以应对的复杂场景中的优势,以及在通常应用RAG的简单场景中也能保持竞争力。
🎯 应用场景
MemoRAG可应用于需要处理长篇文档、书籍、报告等长文本的各种场景,例如:法律文档分析、金融报告解读、科研论文总结、长篇小说理解等。该方法能够提升信息检索的准确性和效率,帮助用户快速定位关键信息,并生成高质量的摘要或答案。未来,MemoRAG有望在智能客服、知识图谱构建等领域发挥重要作用。
📄 摘要(原文)
Processing long contexts presents a significant challenge for large language models (LLMs). While recent advancements allow LLMs to handle much longer contexts than before (e.g., 32K or 128K tokens), it is computationally expensive and can still be insufficient for many applications. Retrieval-Augmented Generation (RAG) is considered a promising strategy to address this problem. However, conventional RAG methods face inherent limitations because of two underlying requirements: 1) explicitly stated queries, and 2) well-structured knowledge. These conditions, however, do not hold in general long-context processing tasks. In this work, we propose MemoRAG, a novel RAG framework empowered by global memory-augmented retrieval. MemoRAG features a dual-system architecture. First, it employs a light but long-range system to create a global memory of the long context. Once a task is presented, it generates draft answers, providing useful clues for the retrieval tools to locate relevant information within the long context. Second, it leverages an expensive but expressive system, which generates the final answer based on the retrieved information. Building upon this fundamental framework, we realize the memory module in the form of KV compression, and reinforce its memorization and cluing capacity from the Generation quality's Feedback (a.k.a. RLGF). In our experiments, MemoRAG achieves superior performances across a variety of long-context evaluation tasks, not only complex scenarios where traditional RAG methods struggle, but also simpler ones where RAG is typically applied.