Spatially-Aware Speaker for Vision-and-Language Navigation Instruction Generation
作者: Muraleekrishna Gopinathan, Martin Masek, Jumana Abu-Khalaf, David Suter
分类: cs.CL
发布日期: 2024-09-09
🔗 代码/项目: GITHUB
💡 一句话要点
提出SAS:一种空间感知指令生成模型,提升视觉语言导航中指令的丰富度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 指令生成 空间感知 奖励学习 具身智能
📋 核心要点
- 现有视觉语言导航指令生成模型生成的指令在指代对象和地标时缺乏多样性,且容易规避评估指标。
- SAS模型利用环境的结构和语义知识,生成更丰富的指令,从而提升指令的质量和多样性。
- 采用对抗环境中的奖励学习方法训练SAS模型,避免了语言评估指标引入的系统性偏差,实验结果优于现有模型。
📝 摘要(中文)
具身智能旨在开发能够理解和执行人类语言指令,并能用自然语言进行交流的机器人。本文研究了为具身机器人生成高度详细的导航指令的任务。尽管最近的研究表明,从图像序列生成逐步指令方面取得了显著进展,但生成的指令在对象和地标的指代方面缺乏多样性。现有的Speaker模型学习规避评估指标的策略,即使对于低质量的句子也能获得更高的分数。为此,我们提出了SAS(Spatially-Aware Speaker),一种指令生成器或“Speaker”模型,它利用环境的结构和语义知识来生成更丰富的指令。在训练方面,我们采用对抗环境中的奖励学习方法,以避免语言评估指标引入的系统性偏差。实验结果表明,我们的方法优于现有的指令生成模型,并通过标准指标进行评估。
🔬 方法详解
问题定义:论文旨在解决视觉语言导航(VLN)中,指令生成模型生成的指令缺乏多样性,且容易被现有评估指标误导的问题。现有方法生成的指令往往过于简单,缺乏对环境细节的有效描述,导致机器人难以准确理解和执行导航任务。
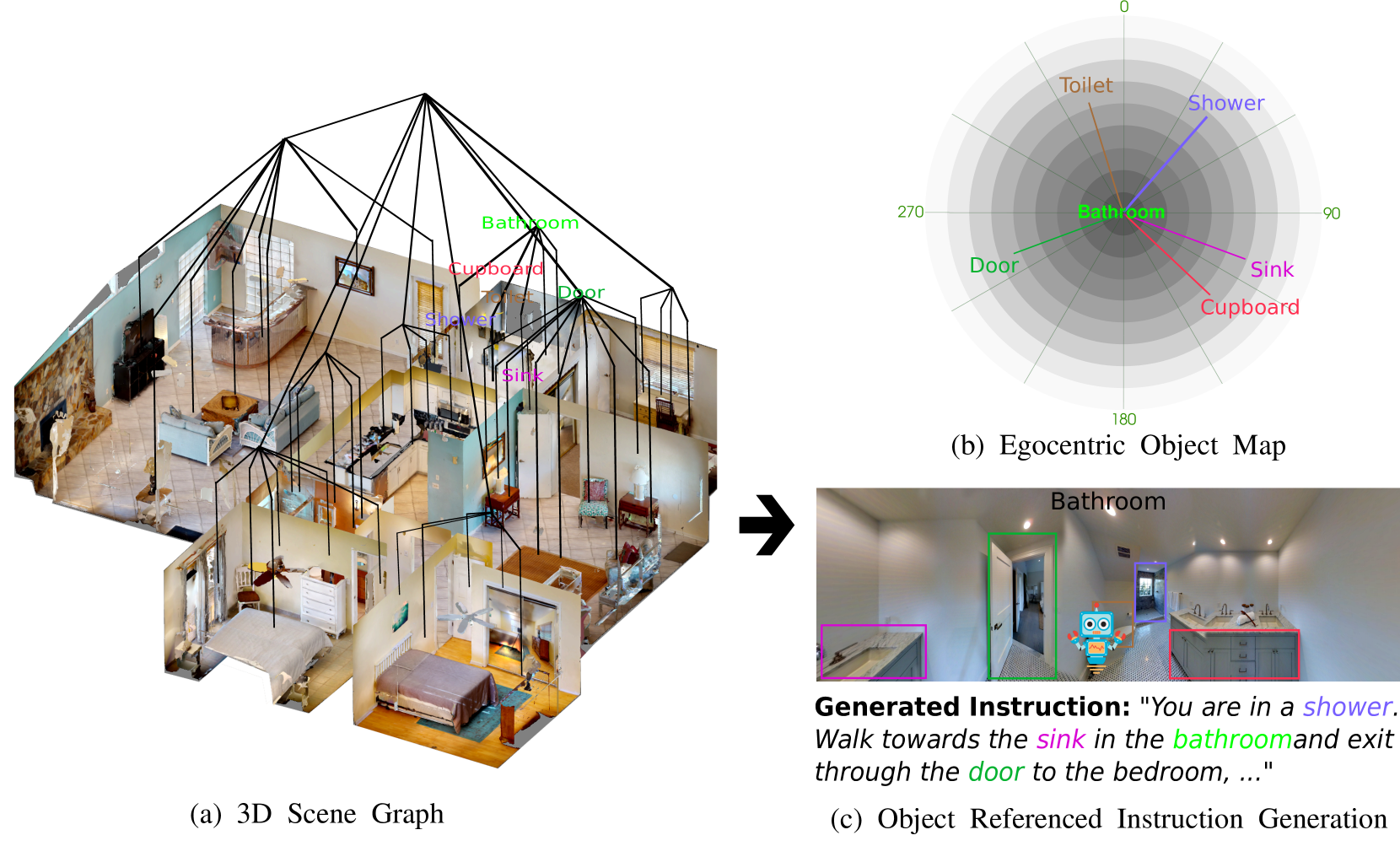
核心思路:论文的核心思路是利用环境的空间结构和语义信息,引导模型生成更丰富、更具描述性的指令。通过引入空间感知机制,模型能够更好地理解环境中的对象、地标及其相互关系,从而生成更准确、更自然的导航指令。此外,采用对抗学习和奖励机制,避免模型过度依赖评估指标,鼓励生成更符合人类语言习惯的指令。
技术框架:SAS模型的整体框架包含以下几个主要模块:1) 视觉编码器:用于提取环境图像的视觉特征。2) 空间感知模块:利用视觉特征和环境地图信息,构建环境的空间表示。3) 指令解码器:基于空间表示和历史指令,生成下一步的导航指令。4) 奖励学习模块:通过对抗学习,训练一个判别器来评估生成指令的质量,并根据判别器的输出,为指令解码器提供奖励信号。
关键创新:SAS模型的关键创新在于引入了空间感知模块和奖励学习机制。空间感知模块能够有效地利用环境的空间信息,生成更具描述性的指令。奖励学习机制能够避免模型过度依赖评估指标,鼓励生成更符合人类语言习惯的指令。
关键设计:在空间感知模块中,论文可能采用了图神经网络(GNN)等技术,对环境地图进行建模,并利用GNN学习节点(对象、地标)之间的关系。在奖励学习模块中,判别器可能采用了Transformer等模型,用于评估生成指令的流畅性、准确性和多样性。具体的损失函数可能包括交叉熵损失、对抗损失和奖励损失等。
🖼️ 关键图片


📊 实验亮点
论文提出的SAS模型在视觉语言导航指令生成任务中取得了显著的性能提升。通过标准评估指标的对比,SAS模型优于现有的指令生成模型,尤其是在指令的多样性和描述性方面。具体的性能数据(例如BLEU score、ROUGE score等)和提升幅度需要在论文中查找。
🎯 应用场景
该研究成果可应用于各种需要自然语言指令导航的机器人应用场景,例如家庭服务机器人、仓库物流机器人、自动驾驶汽车等。通过生成更清晰、更丰富的导航指令,可以提高机器人对人类指令的理解能力和执行效率,从而提升用户体验和应用价值。未来,该技术还可以扩展到其他自然语言生成任务中,例如对话系统、机器翻译等。
📄 摘要(原文)
Embodied AI aims to develop robots that can \textit{understand} and execute human language instructions, as well as communicate in natural languages. On this front, we study the task of generating highly detailed navigational instructions for the embodied robots to follow. Although recent studies have demonstrated significant leaps in the generation of step-by-step instructions from sequences of images, the generated instructions lack variety in terms of their referral to objects and landmarks. Existing speaker models learn strategies to evade the evaluation metrics and obtain higher scores even for low-quality sentences. In this work, we propose SAS (Spatially-Aware Speaker), an instruction generator or \textit{Speaker} model that utilises both structural and semantic knowledge of the environment to produce richer instructions. For training, we employ a reward learning method in an adversarial setting to avoid systematic bias introduced by language evaluation metrics. Empirically, our method outperforms existing instruction generation models, evaluated using standard metrics. Our code is available at \url{https://github.com/gmuraleekrishna/SAS}.