Seek and Solve Reasoning for Table Question Answering
作者: Ruya Jiang, Chun Wang, Weihong Deng
分类: cs.CL, cs.AI
发布日期: 2024-09-09 (更新: 2025-04-20)
备注: Published in: ICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
DOI: 10.1109/ICASSP49660.2025.10890797
💡 一句话要点
提出Seek-and-Solve推理框架,提升LLM在表格问答任务中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格问答 大型语言模型 思维链 推理 上下文学习
📋 核心要点
- 表格问答任务因表格结构复杂和问题逻辑推理困难,对大型语言模型提出了挑战。
- 论文提出Seek-and-Solve流水线,通过引导LLM寻找相关信息并推理作答,提升性能。
- 实验表明,该方法在提高性能和可靠性的同时,保持了较高的效率。
📝 摘要(中文)
本文针对表格问答(TQA)任务中,大型语言模型(LLM)因表格结构和问题逻辑的复杂性而表现不佳的问题,指出任务简化过程中的推理比简化后的任务本身更有价值。为此,论文提出了一种Seek-and-Solve流水线,指导LLM首先寻找相关信息,然后回答问题,并在推理层面将这两个阶段整合为连贯的Seek-and-Solve思维链(SS-CoT)。此外,论文还从该流水线中提炼出一个单步TQA求解提示,利用带有SS-CoT路径的演示来指导LLM在上下文学习设置下解决复杂的TQA任务。实验结果表明,该方法在效率方面有所提升,同时提高了性能和可靠性。研究强调了激发LLM的推理能力以有效处理复杂TQA任务的重要性。
🔬 方法详解
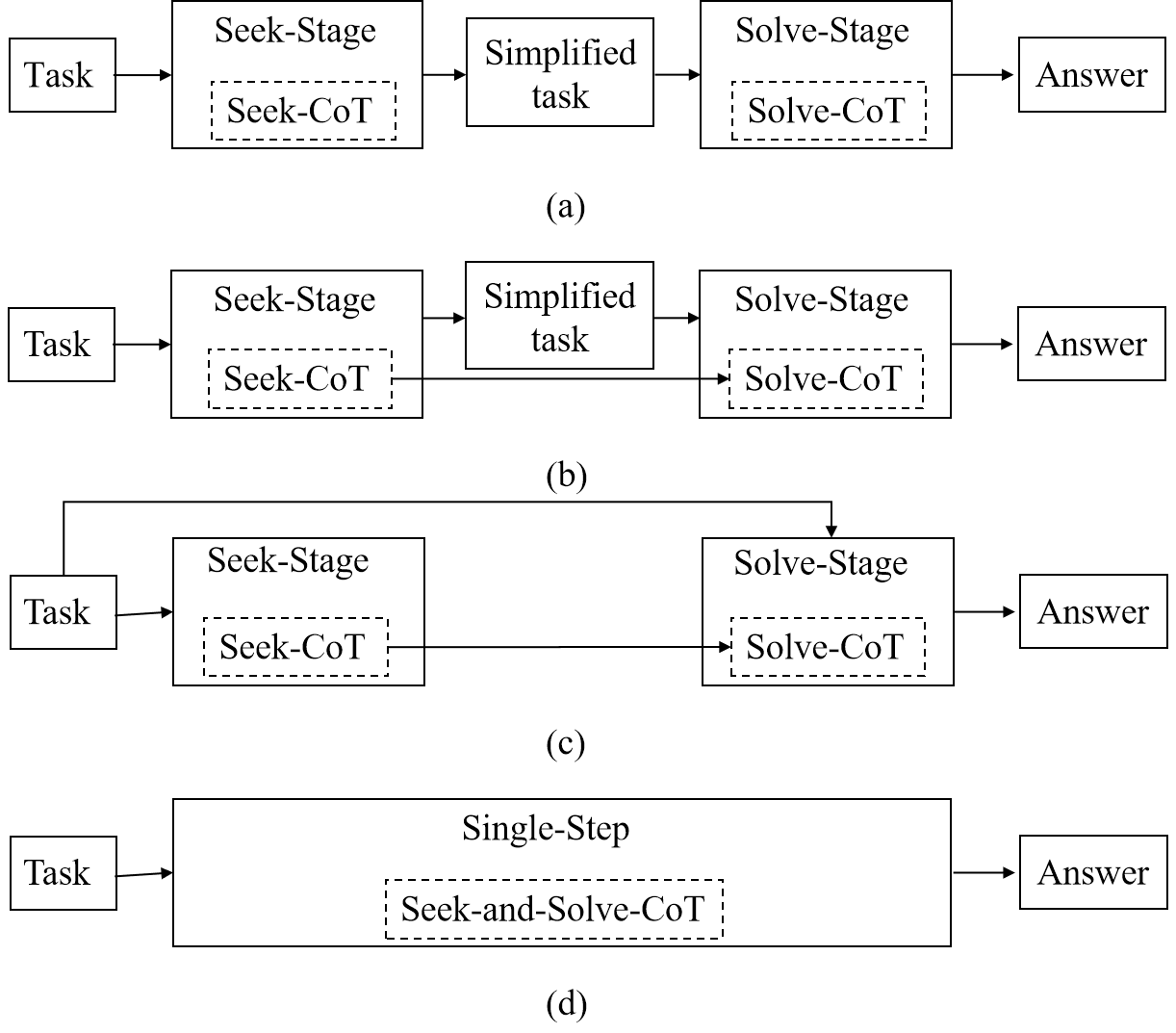
问题定义:表格问答(TQA)任务旨在根据给定的表格内容回答自然语言提出的问题。现有方法通常依赖于任务简化,但忽略了LLM在任务简化过程中蕴含的推理能力。现有的LLM在处理复杂表格和问题逻辑时,性能往往受限,需要更有效的推理机制来提升其准确性和可靠性。
核心思路:论文的核心思路是充分利用LLM在处理TQA任务时的推理能力,而不是仅仅依赖于简化后的任务。通过显式地引导LLM进行“寻找相关信息”和“解决问题”两个阶段的推理,并将这两个阶段整合到一个连贯的思维链中,从而提高LLM对复杂表格和问题的理解和处理能力。
技术框架:论文提出的Seek-and-Solve流水线包含两个主要阶段:Seek阶段和Solve阶段。在Seek阶段,LLM被引导去寻找与问题相关的表格信息。在Solve阶段,LLM利用Seek阶段找到的信息来回答问题。这两个阶段通过Seek-and-Solve Chain of Thought (SS-CoT)进行连接,形成一个完整的推理过程。此外,论文还从SS-CoT中提炼出一个单步TQA求解提示,用于指导LLM在上下文学习设置下解决问题。
关键创新:论文的关键创新在于将LLM的推理过程显式地分解为“寻找”和“解决”两个阶段,并通过SS-CoT将这两个阶段整合为一个连贯的推理链。这种方法能够更有效地利用LLM的推理能力,从而提高其在TQA任务中的性能。与现有方法相比,该方法更加注重利用LLM自身的推理能力,而不是仅仅依赖于外部的任务简化。
关键设计:论文的关键设计包括:1) 设计了Seek和Solve两个阶段的提示语,引导LLM进行相应的推理;2) 提出了Seek-and-Solve Chain of Thought (SS-CoT),将两个阶段的推理过程连接起来;3) 从SS-CoT中提炼出单步TQA求解提示,用于上下文学习。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细描述,属于LLM本身的设计。
🖼️ 关键图片


📊 实验亮点
实验结果表明,提出的Seek-and-Solve方法在表格问答任务中取得了显著的性能提升。具体的数据和对比基线在论文中给出,强调了该方法在提高性能和可靠性方面的有效性。该方法在效率方面也表现良好,表明其具有实际应用潜力。
🎯 应用场景
该研究成果可广泛应用于智能问答系统、数据分析、知识图谱构建等领域。通过提升LLM在表格问答任务中的性能,可以帮助用户更高效地从结构化数据中获取所需信息,具有重要的实际应用价值和广阔的发展前景。未来,该方法可以进一步扩展到其他类型的结构化数据问答任务中。
📄 摘要(原文)
The complexities of table structures and question logic make table-based question answering (TQA) tasks challenging for Large Language Models (LLMs), often requiring task simplification before solving. This paper reveals that the reasoning process during task simplification may be more valuable than the simplified tasks themselves and aims to improve TQA performance by leveraging LLMs' reasoning capabilities. We propose a Seek-and-Solve pipeline that instructs the LLM to first seek relevant information and then answer questions, integrating these two stages at the reasoning level into a coherent Seek-and-Solve Chain of Thought (SS-CoT). Additionally, we distill a single-step TQA-solving prompt from this pipeline, using demonstrations with SS-CoT paths to guide the LLM in solving complex TQA tasks under In-Context Learning settings. Our experiments show that our approaches result in improved performance and reliability while being efficient. Our findings emphasize the importance of eliciting LLMs' reasoning capabilities to handle complex TQA tasks effectively.