DiVA-DocRE: A Discriminative and Voice-Aware Paradigm for Document-Level Relation Extraction
作者: Yiheng Wu, Roman Yangarber, Xian Mao
分类: cs.CL, cs.AI, cs.IR
发布日期: 2024-09-07 (更新: 2025-04-08)
备注: After internal discussions among the co-authors, we have decided to withdraw the manuscript due to a change in research direction and a lack of unanimous agreement to proceed with publication at this time
💡 一句话要点
提出DiVA-DocRE,一种判别式和语音感知的文档级关系抽取方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文档级关系抽取 关系三元组抽取 判别式模型 主动被动语态 信息抽取
📋 核心要点
- 现有文档级关系抽取方法效率低,且忽略了主动语态与被动语态的差异。
- DiVA将文档级关系抽取转化为判别任务,关注关系本身和语态信息。
- 实验结果表明,DiVA在Re-DocRED和DocRED数据集上取得了SOTA性能。
📝 摘要(中文)
大型语言模型(LLMs)在文本理解和生成方面的卓越能力彻底改变了信息抽取(IE)领域。文档级关系三元组抽取(DocRTE)是其中的一项重要进展,旨在从文档中提取实体及其语义关系,是信息系统中的关键任务。然而,现有方法主要针对句子级关系三元组抽取(SentRTE),通常处理的关系和三元组事实数量有限。此外,一些方法将关系视为候选选择,集成到提示模板中,导致处理效率低下,并且在确定三元组中的关系元素时性能欠佳。为了解决这些局限性,我们引入了一种判别式和语音感知范式DiVA。DiVA仅包含两个步骤:执行文档级关系抽取(DocRE),然后根据关系识别主客体实体。无需额外处理,只需输入文档即可直接获得三元组。这种简化的流程更准确地反映了三元组抽取的实际场景。我们的创新在于将DocRE转化为判别任务,模型关注每个关系以及三元组中经常被忽视的主动语态与被动语态问题。在Re-DocRED和DocRED数据集上的实验表明,我们的方法在DocRTE任务上取得了最先进的结果。
🔬 方法详解
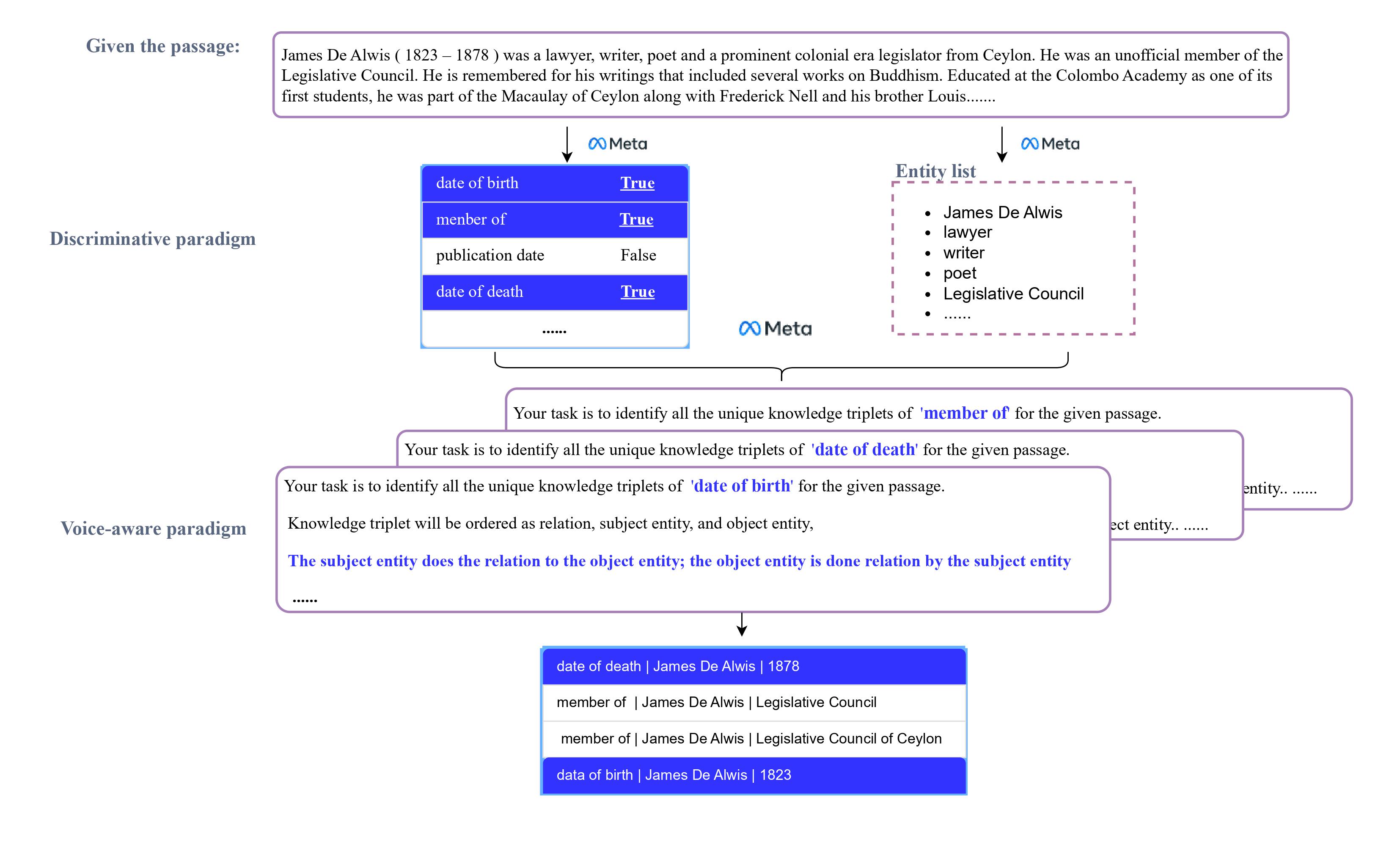
问题定义:论文旨在解决文档级关系三元组抽取(DocRTE)任务中,现有方法效率低下以及忽略主动语态和被动语态的问题。现有方法通常基于句子级别,无法有效处理长文档中的复杂关系。此外,将关系作为候选选择集成到提示模板中,导致效率降低,影响性能。
核心思路:论文的核心思路是将文档级关系抽取(DocRE)转化为一个判别任务。模型不再是生成关系,而是对每个可能的关系进行判别,判断其是否存在于文档中。同时,模型需要关注句子中实体关系的主动语态和被动语态,以更准确地抽取关系三元组。
技术框架:DiVA框架主要包含两个步骤:首先,执行文档级关系抽取(DocRE),判断文档中存在哪些关系。然后,根据抽取出的关系,识别对应的主客体实体。整个流程无需额外的后处理步骤,可以直接从文档中抽取三元组。
关键创新:DiVA的关键创新在于将DocRE转化为判别任务,并引入了对主动语态和被动语态的感知。与现有方法将关系作为候选选择不同,DiVA直接判别关系是否存在,提高了效率和准确性。同时,关注语态信息可以更好地理解实体之间的关系。
关键设计:论文中没有详细说明具体的参数设置、损失函数或网络结构等技术细节。但是,可以推断模型可能使用了某种形式的注意力机制,以便关注每个关系以及句子中的语态信息。损失函数可能采用了二元交叉熵损失,用于判别关系是否存在。
🖼️ 关键图片


📊 实验亮点
DiVA在Re-DocRED和DocRED数据集上取得了最先进的结果,证明了其有效性。具体的性能数据和提升幅度在论文中给出,表明DiVA在文档级关系三元组抽取任务上具有显著优势。该方法通过将DocRE转化为判别任务,并关注语态信息,实现了性能的提升。
🎯 应用场景
该研究成果可应用于知识图谱构建、信息检索、智能问答等领域。通过从海量文档中自动抽取实体关系,可以构建更全面、准确的知识库,提升信息服务的智能化水平。例如,在医学领域,可以从医学文献中抽取药物与疾病之间的关系,辅助药物研发和临床决策。
📄 摘要(原文)
The remarkable capabilities of Large Language Models (LLMs) in text comprehension and generation have revolutionized Information Extraction (IE). One such advancement is in Document-level Relation Triplet Extraction (DocRTE), a critical task in information systems that aims to extract entities and their semantic relationships from documents. However, existing methods are primarily designed for Sentence level Relation Triplet Extraction (SentRTE), which typically handles a limited set of relations and triplet facts within a single sentence. Additionally, some approaches treat relations as candidate choices integrated into prompt templates, resulting in inefficient processing and suboptimal performance when determining the relation elements in triplets. To address these limitations, we introduce a Discriminative and Voice Aware Paradigm DiVA. DiVA involves only two steps: performing document-level relation extraction (DocRE) and then identifying the subject object entities based on the relation. No additional processing is required simply input the document to directly obtain the triplets. This streamlined process more accurately reflects real-world scenarios for triplet extraction. Our innovation lies in transforming DocRE into a discriminative task, where the model pays attention to each relation and to the often overlooked issue of active vs. passive voice within the triplet. Our experiments on the Re-DocRED and DocRED datasets demonstrate state-of-the-art results for the DocRTE task.